 爆红智能AI如何看待DPU
爆红智能AI如何看待DPU
上线仅2个月,OpenAI的最新一代产品-AI聊天机器人ChatGPT月活用户接近1亿。
作为自然语言处理(NLP)领域的前沿研究成果之一,ChatGPT已成为AIGC里程碑式的产品。
这周我们也与ChatGPT聊了聊他/她对大规模预训练背后所需资源的看法。
让我们一起来看看ChatGPT的回答是否能让你满意呢?
强大的语言生成能力现在引起更多讨论的是规模预训练。在过去的很长一段时间里,许多的AI厂商都是通过本地设备来进行训练的。
GPT-3所训练的参数约为1750亿个,这部分需要大量的算力,而目前我们已知ChatGPT导入了至少1万颗英伟达高端GPU来训练模型。
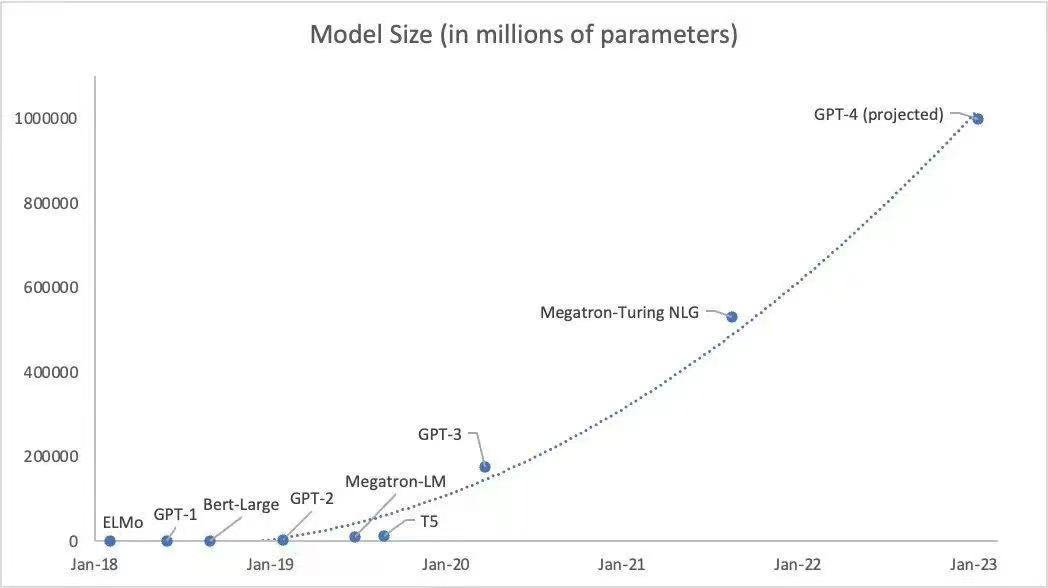

业界部分专家认为GPT-4训练参数可能会达到100万亿个参数,如此大规模、长时间的GPU集群训练任务,也对网络互联底座的性能、可靠性、成本等各方面都提出了极致的要求。
面对千亿、万亿参数规模的大模型训练,仅仅是单次计算迭代内梯度同步需要的通信量就高达TB量级。此外还有各种并行模式、加速框架引入的通信需求,使得传统低速网络的带宽远远无法支撑GPU集群的高效计算,甚至成为了其中关键的瓶颈。
因此要充分发挥GPU计算资源的强大算力,必须构建一个全新的高性能网络底座,用高速网络的大带宽来助推整个集群计算的高效率。
以CPU+GPU的异构计算模型已经成为高性能计算领域中的主流计算架构。而高吞吐、低延时是高性能计算场景中最为迫切的应用需求。
我们可以知道,GPUDirect RDMA是RDMA在异构计算场景中的应用延伸,使得GPU之间的通信不在依赖CPU转发,从而进一步提升高性能计算场景中整体算力。
从DPU芯片的实现角度看,不同DPU厂商的核心竞争壁垒在于专用加速引擎的硬件实现上。由于DPU是数据中心中所有服务器的流量入口,并以处理报文的方式处理数据,在网络芯片领域积累更多的厂商将更有优势。
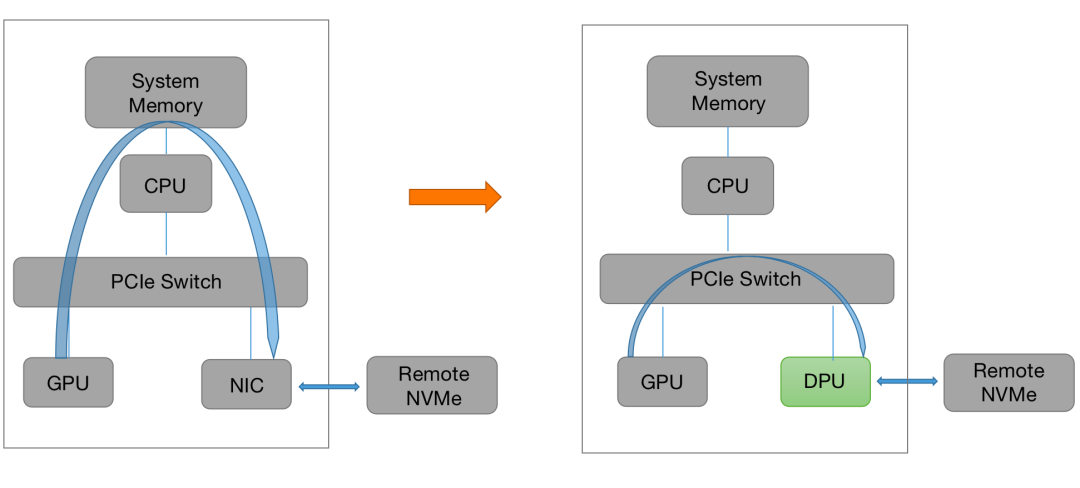
传统的GPU在访问存储时,需要将数据先搬移到系统内存,再由系统内存搬移到目标设备。而采用DPU介入后可以绕过CPU,直接通过PCIe访问远端的NVMe设备,加速AI训练,大大降低CPU的开销。
在AI/ML领域的工作负载对于存储系统的要求十分苛刻,目前此类应用已主要采用全闪存存储,其中NVMe全闪存逐渐成为主流趋势。同时存储与前端应用主机的网络存储协议开始采用NVMe over Fabrics(NVMe-oF)。
NVMe-oF是一种存储网络协议,通过网络将NVMe命令传送到远程NVMe子系统,以利用NVMe 全闪存的并行访问和低延迟,该规范定义了一个协议接口,旨在与高性能fabric技术配合使用,包括通过实现RDMA技术的InfiniBand、RoCE v2、iWARP或TCP。
NVMe-oF是一种使用NVMe协议将访问扩展到远程存储系统的非易失性存储器(NVM)设备的方法。这使得前端接口能够连接到存储系统中,扩展到大量NVMe设备,并延长数据中心内可以访问NVMe子系统的距离。NVMe-oF的目标是显著改善数据中心网络延迟,并为远程NVMe设备提供近似于本地访问的延迟,目标为10us。
我们知道AI对计算的需求非常大,目前主流的AI加速还是以GPU、FPGA和一些专门的AI芯片等为主。在GPU、AI芯片用于AI计算之前都是CPU承担计算的任务,CPU的效率难以满足需求,从而产生CPU+GPU+ASIC的异构计算。随着DPU的出现,这种异构计算的发展更加彻底,可以更大提供并行处理能力,适合大规模计算的发展。
支持Chiplet技术的超异构算力芯片,伴随着AI/ML的发展将会得到更好的应用,而支持Die-To-Die互联技术将能够提供互联其他AI芯片和算力单元的巨大能力,摆脱一直以来PCIe发展的限制。 拿芯启源自身举例,以支持高级AI为主要目标之一的芯启源最新的DPU芯片,其架构中就应用Chiplet技术。不仅提升了自有智能网卡的性能,通过支持与第三方芯片的Die-To-Die互联,还可以集成更多的特定专业领域的芯片,比如AI训练中的GPU芯片。
虽然PCIe非常的标准,但是带宽非常有限的,PCIe Gen3的理论带宽是32GB/s,PCIe Gen4的理论带宽是64GB/s,而实测带宽大概分别是24GB/s和48GB/s。
在AI训练中,每完成一轮计算,都要同步更新一次参数,也就是权系数。模型规模越大,参数规模一般也会更大,这样算力芯片的效率会收到PCIe架构的限制,支持更高能力层次的互联技术讲彻底解决带宽限制和瓶颈,极大提升单节点计算效率。
和ChatGPT聊了那么多,最后再让我们来看看他/她对于DPU应用了解多少呢?

审核编辑 :李倩
-
AI
+关注
关注
87文章
30979浏览量
269253 -
DPU
+关注
关注
0文章
364浏览量
24200 -
chiplet
+关注
关注
6文章
433浏览量
12600
原文标题:爆红智能AI如何看待DPU ChatGPT这样说
文章出处:【微信号:corigine,微信公众号:芯启源】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
AI智能网卡在AI网络中的作用
红魔9S Pro+ AI游戏手机实力如何
AI for Science:人工智能驱动科学创新》第4章-AI与生命科学读后感
《AI for Science:人工智能驱动科学创新》第二章AI for Science的技术支撑学习心得
《AI for Science:人工智能驱动科学创新》第一章人工智能驱动的科学创新学习心得
人工智能ai4s试读申请
名单公布!【书籍评测活动NO.44】AI for Science:人工智能驱动科学创新
IaaS+on+DPU(IoD)+下一代高性能算力底座技术白皮书
红魔9S Pro系列AI游戏手机正式发布
DPU技术赋能下一代AI算力基础设施
明天线上见!DPU构建高性能云算力底座——DPU技术开放日最新议程公布!
发布行业首款AI大模型三摄智能锁,全系列产品AI加持,萤石2024春季新品发布会很AI






 工商网监
工商网监
评论