 利用视觉+语言数据增强视觉特征
利用视觉+语言数据增强视觉特征
研究动机
传统的多模态预训练方法通常需要"大数据"+"大模型"的组合来同时学习视觉+语言的联合特征。但是关注如何利用视觉+语言数据提升视觉任务(多模态->单模态)上性能的工作并不多。本文旨在针对上述问题提出一种简单高效的方法。
在这篇文章中,以医疗影像上的特征学习为例,我们提出对图像+文本同时进行掩码建模(即Masked Record Modeling,Record={Image,Text})可以更好地学习视觉特征。该方法具有以下优点:
简单。仅通过特征相加就可以实现多模态信息的融合。此处亦可进一步挖掘,比如引入更高效的融合策略或者扩展到其它领域。
高效。在近30w的数据集上,在4张NVIDIA 3080Ti上完成预训练仅需要1天半左右的时间。
性能强。在微调阶段,在特定数据集上,使用1%的标记数据可以接近100%标记数据的性能。
方法(一句话总结)
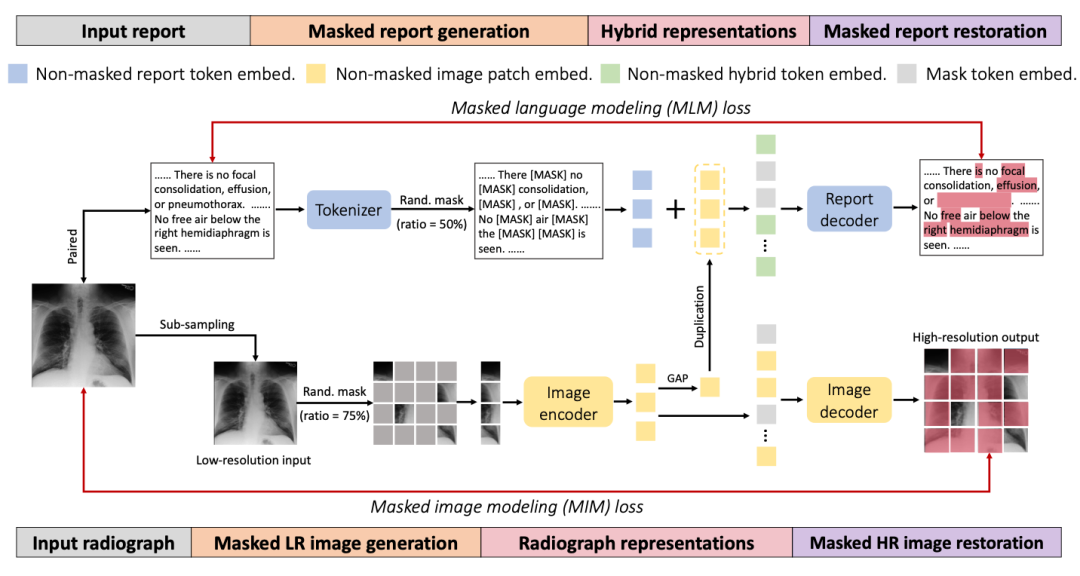
如上图所示,我们提出的训练策略是比较直观的,主要包含三步:
随机Mask一部分输入的图像和文本
使用加法融合过后的图像+文本的特征重建文本
使用图像的特征重建图像。
性能
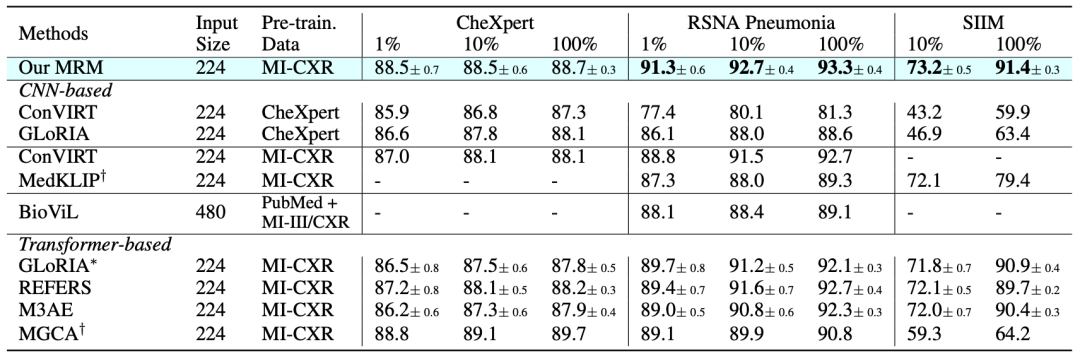
如上图所示,我们全面对比了现有的相关方法和模型在各类微调任务上的性能。
在CheXpert上,我们以1%的有标记数据接近使用100%有标记数据的性能。
在RSNA Pneumonia和SIIM (分割)上,我们以较大幅度超过了之前最先进的方法。
审核编辑 :李倩
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
建模
+关注
关注
1文章
305浏览量
60771 -
数据集
+关注
关注
4文章
1208浏览量
24699 -
大数据
+关注
关注
64文章
8886浏览量
137434
原文标题:ICLR 2023 | 厦大&港大提出MRM:利用视觉+语言数据增强视觉特征
文章出处:【微信号:CVer,微信公众号:CVer】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
基于视觉语言模型的导航框架VLMnav
本文提出了一种将视觉语言模型(VLM)转换为端到端导航策略的具体框架。不依赖于感知、规划和控制之间的分离,而是使用VLM在一步中直接选择动作。惊讶的是,我们发现VLM可以作为一种无需任何微调或导航数据的端到端策略来使用。这使得该
图像采集卡:增强视觉数据采集
图像采集卡介绍:在视觉数据采集领域,图像采集卡在捕获和处理来自各种来源的图像或视频方面发挥着关键作用。在本文中,我们将深入探讨图像采集卡的世界、其功能、应用以及它们在视觉数据采集领域提

视觉检测是什么意思?机器视觉检测的适用行业及场景有哪些?
检测的定义与原理 机器视觉检测,是利用光学成像、数字信号处理和计算机技术,模拟人类视觉的功能,对目标物体进行自动检测和分析的技术。它包括图像采集、预处理、特征提取、分类识别等多个环节,
什么是机器视觉opencv?它有哪些优势?
机器视觉(Machine Vision)是一种利用计算机和图像处理技术来模拟人类视觉系统的功能,实现对图像的识别、分析和理解的技术。OpenCV(Open Source Computer
机器视觉的应用实例解析
机器视觉是一种利用计算机视觉技术对图像进行处理、分析和理解的技术。它在许多领域都有广泛的应用,包括工业自动化、医疗诊断、交通监控、安全监控等。 一、引言 机器视觉技术的发展可以追溯到2
机器视觉控制的优缺点有哪些
机器视觉控制是一种利用计算机视觉技术对机器进行控制的方法,它在工业自动化、机器人技术、智能交通等领域得到了广泛应用。然而,机器视觉控制也存在一些优缺点。本文将详细介绍机器

视觉检测设备的分类
视觉检测设备是一种利用摄像头、传感器、光源和图像处理算法等技术组成的设备,用于检测、识别、分析和判断图像或视频中目标物体的特征、属性、状态或缺陷。这些设备可以应用于各种行业和领域,包括工业自动化

机器视觉软件有哪些 机器视觉软件的优点
机器视觉软件是一种利用计算机视觉技术来模拟和弥补人眼视觉功能的软件系统。它可以通过对图像和视频进行分析,识别和理解目标物体,以实现自动化和智能化的任务。机器
赛默斐视表面瑕疵检测系统是一种利用机器视觉技术
或其他图像采集设备对产品表面进行拍摄,获取产品的图像数据。 图像预处理:对采集到的图像进行预处理,包括去噪、灰度化、增强对比度等操作,以提高后续处理的准确性。 特征提取:从预处理后的图像中提取
机器人基于开源的多模态语言视觉大模型
ByteDance Research 基于开源的多模态语言视觉大模型 OpenFlamingo 开发了开源、易用的 RoboFlamingo 机器人操作模型,只用单机就可以训练。
发表于 01-19 11:43
•419次阅读

焊接视觉检测系统的原理和应用
工业生产中的重要性和应用情况。 焊接视觉检测是基于机器视觉和图像处理技术的自动化技术,原理是利用计算机视觉技术,通过图像采集、处理和分析,实现对焊接质量自动化检测、
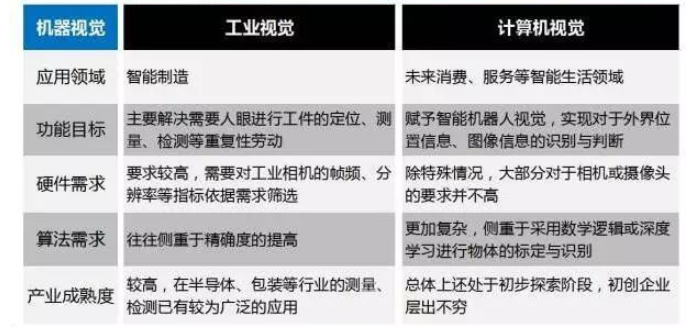
工业视觉与计算机视觉的区别
工业视觉主要解决以往需要人眼进行的工件的定位、测量、检测等重复性劳动;计算机视觉的主要任务是赋予智能机器人视觉,利用测距、物体标定与识别等功能实现对于外界位置信息、图像信息等的识别与判
发表于 01-16 10:06
•592次阅读
labview视觉开发模块认识及应用
开发者能够快速、高效地开发出各种视觉应用。 LabVIEW视觉开发模块的主要特点包括以下几个方面: 图形化编程:LabVIEW使用图形化编程语言G语言,可以通过简单地拖拽和连接函数模块





 工商网监
工商网监
评论