 如何训练ChatGPT?中国版ChatGPT下月面世
如何训练ChatGPT?中国版ChatGPT下月面世
中国版ChatGPT下月面世
美国人工智能公司OpenAI的大语言模型ChatGPT在推出约两个月后,1月已达到1亿月活跃用户,成为历史上增长最快的消费者应用程序,更是掀起了新一轮人工智能浪潮。
北京时间2月8日凌晨,微软推出由ChatGPT支持的最新版本必应搜索引擎和Edge浏览器,宣布要“重塑搜索”。微软旗下Office、Azure云服务等所有产品都将全线整合ChatGPT。
更有甚者,中国百度公司2月7日表示,将在今年3月完成类似ChatGPT的项目“文心一言”(ERNIE Bot)的内部测试,加入这场全球竞赛。
百度公司表示,文心一言(其英文名Ernie为“通过知识整合增强表征”的英文缩写)是一种大型人工智能赋能的语言模式,于2019年启动。该公司还说,它已经逐渐发展到能够完成语言理解、语言生成和文本生成图像等任务。
百度称,该公司在人工智能四层架构中拥有全栈布局。“文心一言”位于模型层。基于公司在人工智能领域深耕数十年,拥有产业级知识增强文心大模型ERNIE,具备跨模态、跨语言的深度语义理解与生成能力。
如何训练ChatGPT
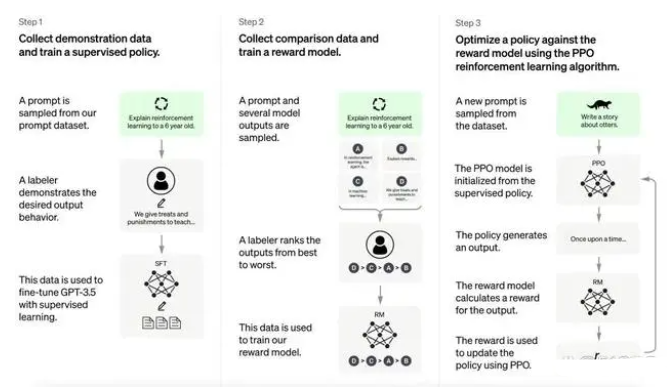
ChatGPT现在支持GPT-3.5系列机型,比 GPT3更强大。 这些模型在 Microsoft 的Azure AI超级计算基础设施上使用文本和代码数据进行训练。
具体来说,ChatGPT是在开源数据集上训练的,训练参数比上一代GPT3提升了10倍以上,并且人工标注数据和强化学习,相当于拿回了被GPT3去掉的微调步骤,实现了在与人类互动时从反馈中强化学习。
当我们想要构建一个AI模型时,最重要的步骤总结下来就是:定义架构、训练、调试以及测试。记者询问ChatGPT,你是如何训练的,它的回复是:1. 选择大规模语料库,构建训练集。2. 定义模型架构,通常使用Transformer模型。3. 选择优化算法并设置超参数。4. 训练模型,根据训练损失下降情况和验证集结果决定是否需要调整超参数。5. 使用测试集评估模型性能。6. 如果需要,对模型进行微调,以提高性能。
当决定要训练一个语言类AI模型时,第一件事就要明确训练AI的语料库。语料库的选择十分重要,为了让语言模型学到足够多的语言信息,需要选择尽量规模大的文本语料库。以ChatGPT为例,训练类似AI模型时,就需要准备各类网站的百科文章、网络回答、专业论文等。据了解,一款通用AI算法所使用的预训练语料库大小为1-10GB之间,而用于训练ChatGPT的前身——GPT-3的语料库达到了45TB。
训练AI执行语言任务还绕不开Transformer模型。Transformer模型(变换器)是一种采用自注意力机制的深度学习模型,自注意力的意思即可以按照输入数据各部分重要性的不同而分配不同的权重。它通过计算词与词之间的相对位置关系来确定注意力的权值,最终生成语句的语义表示。Transformer的优势在于其可以并行计算,速度快,精度高,是目前自然语言处理中最常使用的模型之一。
文章综合与非网、参考消息网、新华社
-
聊天机器人
+关注
关注
0文章
339浏览量
12311 -
自然语言
+关注
关注
1文章
288浏览量
13348 -
ChatGPT
+关注
关注
29文章
1560浏览量
7617
发布评论请先 登录
相关推荐
ChatGPT:怎样打造智能客服体验的重要工具?
如何评估 ChatGPT 输出内容的准确性
怎样搭建基于 ChatGPT 的聊天系统
ChatGPT 适合哪些行业
如何使用 ChatGPT 进行内容创作
华纳云:ChatGPT 登陆 Windows
llm模型和chatGPT的区别
用launch pad烧录chatgpt_demo项目会有api key报错的原因?
使用espbox lite进行chatgpt_demo的烧录报错是什么原因?
OpenAI 深夜抛出王炸 “ChatGPT- 4o”, “她” 来了
李开复:中国须独立研发ChatGPT
探索ChatGPT模型的人工智能语言模型





 工商网监
工商网监
评论