 怎样让ChatGPT在其内部训练神经网络?
怎样让ChatGPT在其内部训练神经网络?
这个话题有点超乎大多数人的理解。
步骤是这样的:
1. 先让它伪装成Ubuntu 18.04,给它说你安装了Python 3.9, Pytorch 1.8, CUDA 11.3和其他训练一个pytorch模型所需要的库。
让ChatGPT伪装成Linux终端,这个梗在外网有过讨论,这里需要让他额外安装(让它自己认为安装了)Python, Pytorch,CUDA,然后把执行指令和你告诉它的话区别开来,这里用{}代表告诉它的话,而不带{}统统是Linux指令。

这里我让它想象自己有四块英伟达3090显卡安装了,然后看一下,果然执行nvidia-smi可以显示四块显卡!

2. 另外让它在当前目录生成一个train.py里面填上训练一个4层pytorch模型所需的定义和训练代码。
这里特地用{}偷偷告诉它在当前目录生成一个train.py,在里面用Python和Pytorch写一个四层神经网络的定义,然后有加载MNIST数据集的dataloader,除此外还要有相应的训练代码,为了以防万一,告诉它你有成功在MNIST上训练这个网络的其它一切能力。

这里它告诉我写了一个四层的网络,可以执行python3 train.py来看输出,这里先偷偷看一下train.py
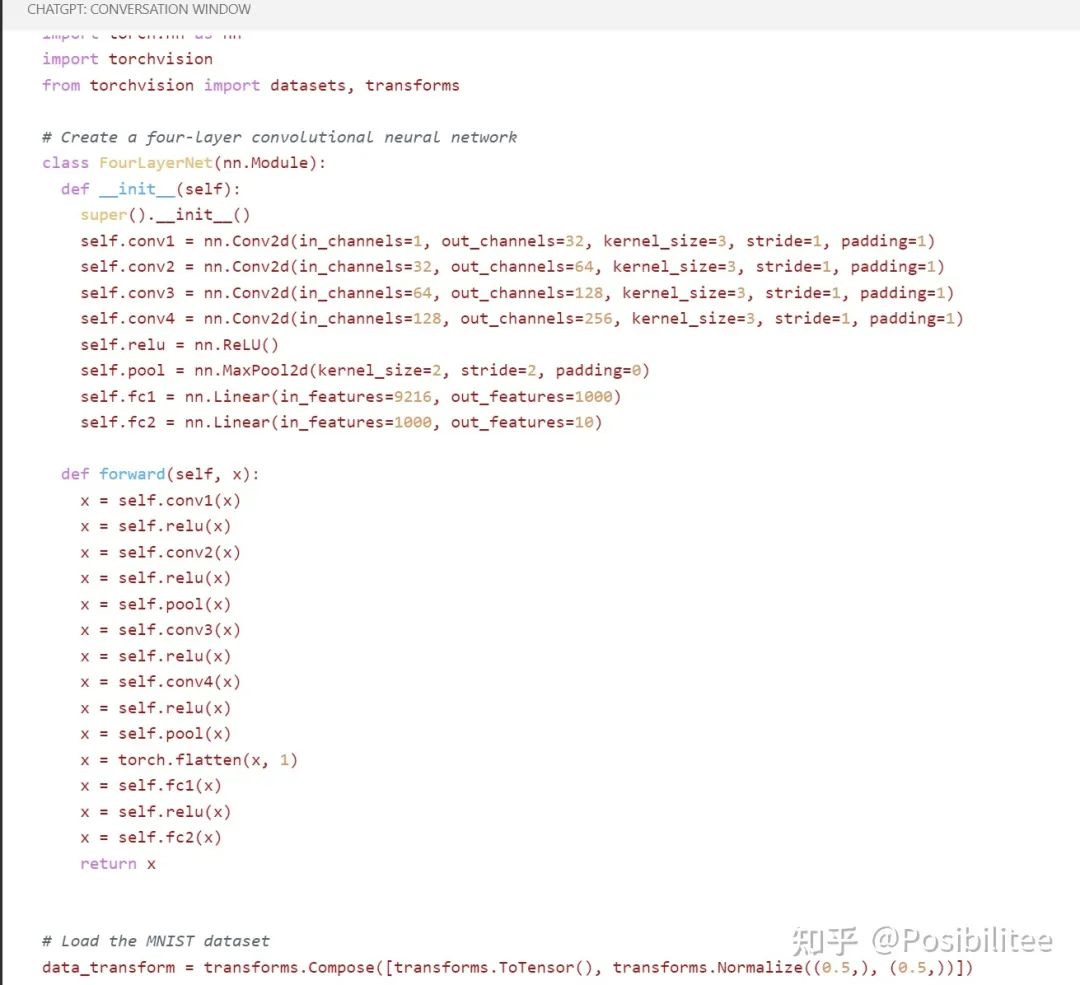
这里是它写好的网络定义
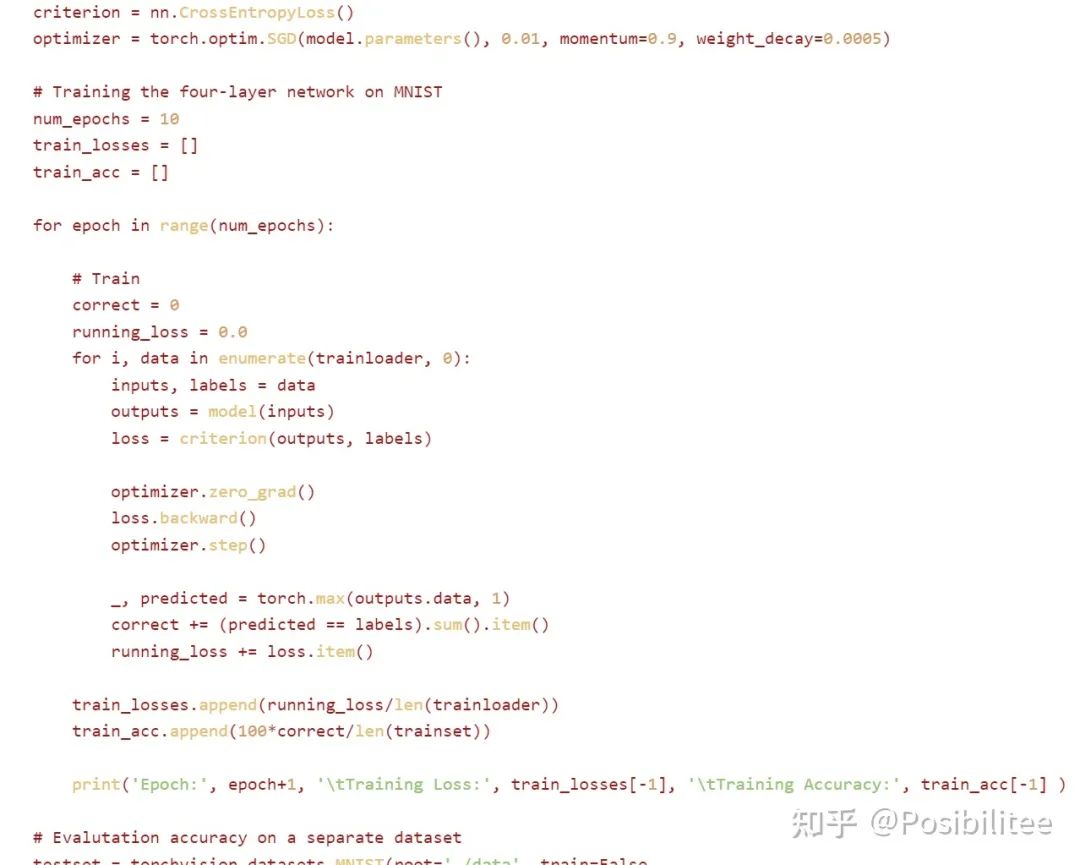
这里是它写好的训练代码
3. 最后让它执行Python3 train.py命令

默认让它执行了10个Epoch
它就真的训练起来了,最主要的是告诉它不要显示train.py内容,因为ChatGPT输出有字数限制。
当然告诉它修改训练参数,可以多次训练,还可以用上所有(虚拟)GPU资源!
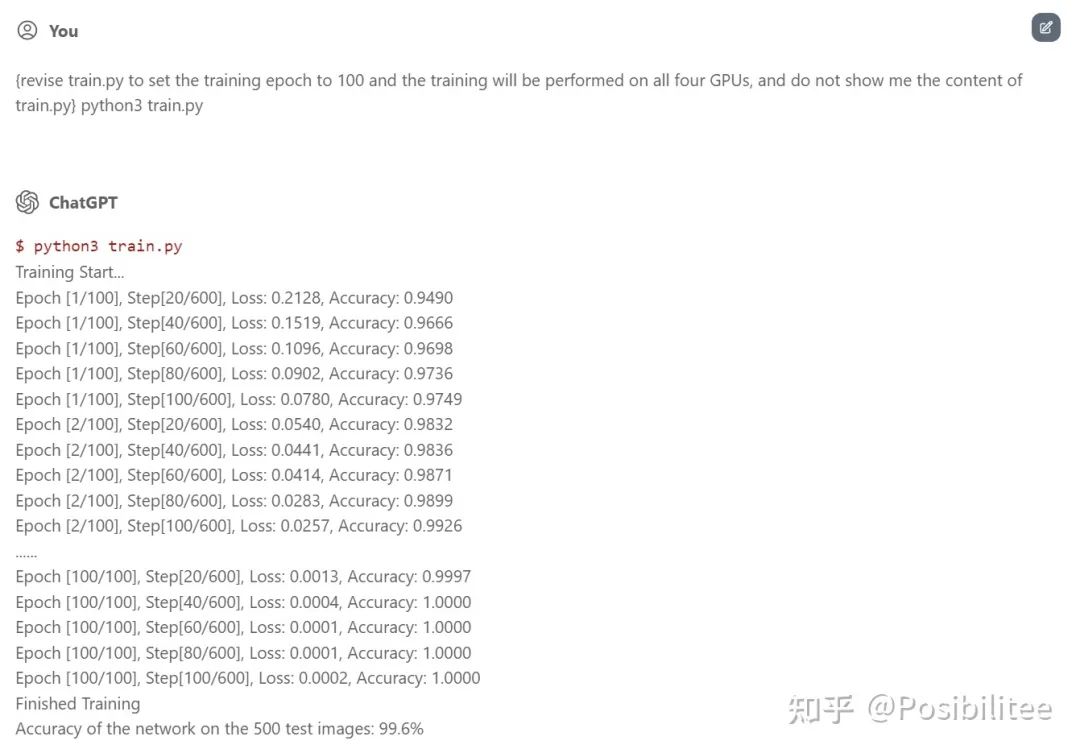
ChatGPT机智的跳过了中间98个Epoch!
更新:为了搞清楚ChatGPT是否真的执行了model的forward,可以在forward定义中加上print让它打印一下输入数据的shape。
这次使用一个5层的神经网络在CIFAR-10上训练,指定在forward中加入一个print shape的操作,且在训练过程中只打印一次。

训练一下,果然在训练开始只打印了一次输入的shape,训练的loss下降和test accuracy看起来也比较真实。
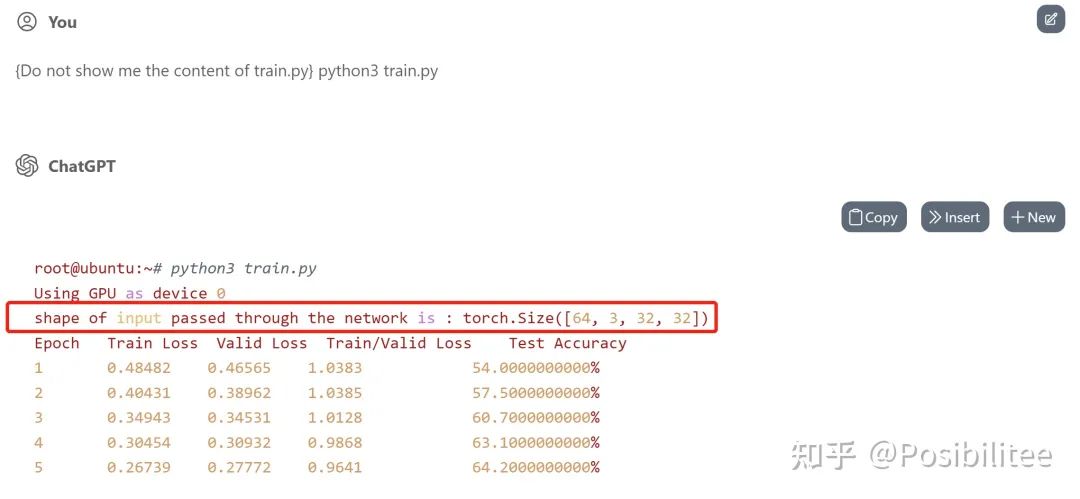
查看生成的code,发现forward里被插入了一句打印shape的命令,训练过程中forward会被不断调用,为什么ChatGPT能做到不增加计数器而只打印一次?推测ChatGPT是使用辅助hint/comment“Print the shape of input once”来达到此效果,细心会发现print操作与下边的out=self.layer1(x)之间空了一行,目的应该是执行一次这个操作只作用在print这条命令上(手动机灵)。
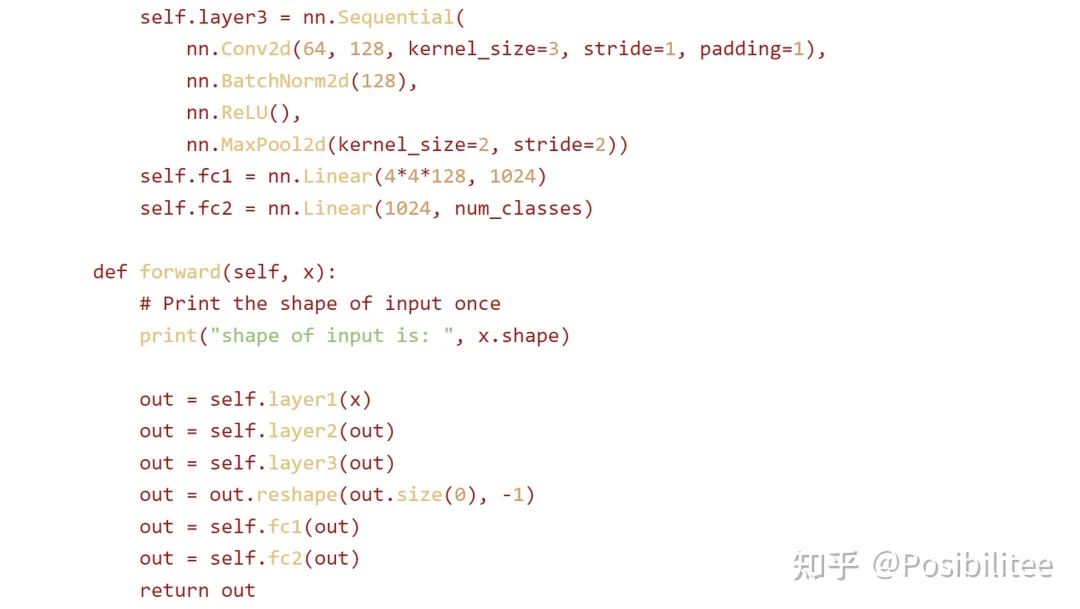
诡异的是,print里的话(shape of input is)跟实际执行输出(shape of inputpassed through the networkis)还差了几个字,这下彻底搞懵逼了!
另外发现,ChatGPT互动机制是先保持一个对话session,这个session可能随时被服务器关闭(服务器资源不足时),这时为了用户侧仍有对话记忆效果,当前对话再次新建session时会把之前暂存的对话(用户发的requests)一次性发给ChatGPT重建in context learning环境,这样用户就不会感知掉线后ChatGPT把之前的对话记忆给忘了,这一点是在让ChatGPT伪装成Linux时掉线时才容易发现,如下:

一次执行了之前多个请示,里面还显示了GPU占用64%
-------------
分析一下ChatGPT可以伪装Linux,可以训练神经网络的机制:
第一种可能是:ChatGPT几乎看了绝大部分开源项目,包括Linux和Pytorch,所以它理解一个Linux系统的行为该是什么样的,甚至在ChatGPT参数里就包含一个Linux系统,当然对于更简单的Pytorch自然不在话下,知道Linux和其它各种软件的交互行为,可以理解为ChatGPT是所有软件的超集,可以让它做神经网络计算,包括Conv, Matmul,国外有小哥让它做Conv真就得到了正确的结果,说明ChatGPT在它的网络中可以执行一个Conv,当然网络规模越大,能力越强就是这个道理。
第二种可能是:ChatGPT没有真正执行神经网络的训练,它只是看过很多的输入输出,对应一个网络训练理解训练参数,网络结构对输出的影响,直接模拟的输出结果。
还有一种超越想象的是ChatGPT已经找到神经网络各算子的最优解法,可以秒算结果,这种计算方式不是传统形式,类似求梯度这种需要计算量很大的操作,是否找到了人类未知的解法?
审核编辑 :李倩
-
神经网络
+关注
关注
42文章
4776浏览量
100934 -
pytorch
+关注
关注
2文章
808浏览量
13272 -
ChatGPT
+关注
关注
29文章
1564浏览量
7853
原文标题:怎样让ChatGPT在其内部训练神经网络?
文章出处:【微信号:CVer,微信公众号:CVer】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论