 OpenDaylight中的DataStore是什么
OpenDaylight中的DataStore是什么
本篇作为MD-SAL核心内容的第二篇,我们将从OpenDaylight的数据存型、DataStore是什么,如何实现等几个方面进行介绍。

图片来自网络
一、OpenDaylight需要的数据存储
1.1数据库简单介绍
我们熟知的软件系统有学校的“图书馆管理系统”,企业里面的“客户关系管理系统”,这些系统本质上只需要易操作就可以了,不需要高并发,这种系统的典型架构如下图所示:

我们注意到这些系统都包含一个数据库。而提到数据库,我们可能先想到的是MySql、oracle之类的关系型数据库,有人可能还会想到MangoDB、redis的非关系型数据库,使用Java语言编程的人员可能会想到ehcache、memcache等缓存数据库。如下图所示:

我们来看下什么是内存数据库?在Wiki上,我们可以看到:“内存数据库(in-memory database,IMDB),也称为主内存数据库系统或内存驻留数据库,是一种数据库管理系统,主要依赖主存储器进行计算机数据存储。它与采用磁盘存储机制的数据库管理系统形成对比。内存数据库比磁盘优化数据库更快,因为磁盘访问比内存访问慢,内部优化算法更简单,执行的CPU指令更少”。事实上,在具有实时计费能力的电信运营商,采用的基本上都是内存数据库。它的好处是访问速度快,一般来说,内存数据库要比磁盘数据库快10000倍。不好之处在于
数据是直接存在系统主内存中,如果内存数据库重启或崩溃后,可能会导致数据全部丢失。所以内存数据库很重要的一点就是如何保证数据的安全可靠,并能在出现问题时能够快速恢复数据。
1.2 OpenDaylight能力需求
SDN起源于校园网,发扬光大于数据中心,现广泛用于广域网,SDN控制器,可能管理着数十万台软交换机,下发数百万乃至上千万条路由信息。因此,作为SDN控制器的开源项目OpenDaylight,无论是业务逻辑还是数据存储,都需要具备如下能力:
l高并发:支持大规模的网络设备控制、网络路由计算和生成、海量的业务消息处理;
l高可靠:在控制器软硬件发生故障时,依然能够对外提供服务;
l实时性:SDN网络能够做到秒级或毫秒级的收敛;
1.3 OpenDaylight存储选型
从上面的分析可知,OpenDaylight选用内存数据库极为合适。下面我们来看下OpenDaylight的存储选型:
Lithium 版本之前 ,OpenDaylight采用基于AD-SAL的架构设计,数据存储采用的是Infinispan。它是基于内存的分布式键值存储系统。那么,如何理解键值存储呢?可以简单地将理解为“键与值的映射”,在内存中的具体形式体现HashMap和有序树。Infinispan可以作为一个Java Lib进行使用,也可以通过一系列主流的远程协议方式(如REST、WebSockets)来提供独立的服务。
Ininispan包可通过Maven的方式获取,Infinispan jar包含所需的OSGi manifest headers,可以作为OSGi包OSGi运行时环境中使用。 除此之外,还需要安装所需的第三方依赖项。详细安装方法可参照:
http://infinispan.org/docs/9.3.x/getting_started/getting_started.html
Lithium版本之后, OpenDaylight转向基于MD-SAL的架构设计,存储实现也相应的转为DataStore。
二、如何理解DataStore?
2.1DataStore是什么
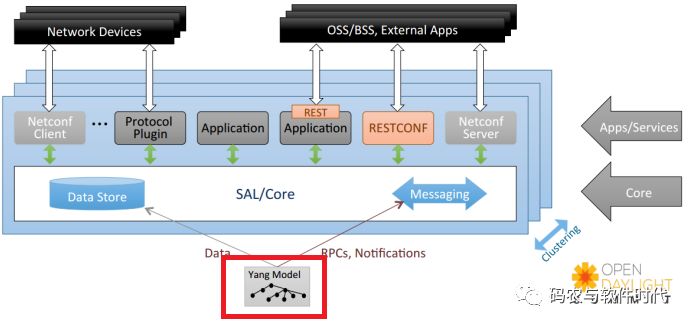
在OpenDaylight控制器中,使用YANG作为建模语言,用于对数据存储的内容和行为进行建模,YANG可以转换成XML的格式。作为MD-SAL核心的Datastore实现了W3C DOM Document树,并使用XML进行数据的表示。需要说明的一点:DataStore并不是完全基于XML的,OpenDaylight子项目YANGTools提供了优化YANG XML并使其适应XML DOM的模块。
DataStore由DataTree组成,Yang定义了该树的地址空间,由根节点、叶子节点和内部节点组成,如下图所示:

图片来自网络
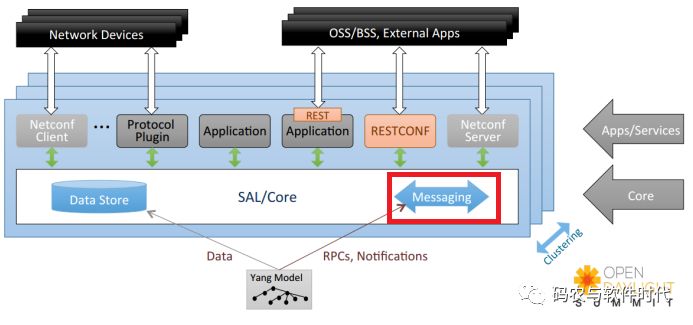
而DataTree分为两个逻辑数据存储:operational和config。这两部分都有统一的视图,并且可以使用实例标识符InstanceIdentifier来定位特定节点。如下图所示:

图片来自网络
2.2DataStore如何实现?
2.2.1如何进行并发控制?
数据库中经常发生并发的场景:应用逻辑A在读取数据的同时,应用逻辑B可能正在写入数据,应用逻辑A就可能读到不一致的数据,也就是脏读。为了解决上述出现的问题,实现并发控制,大家想到最简单的方法便是加锁,让所有读数据的应用程序等待写数据的应用程序工作完成,这相当于串行工作,效率非常低。现在大多数据库实现的是MVCC(Multi-Version Concurrency Control,多版本并发控制机制),基本思想是通过对同一份数据保持多版本来并发问题,在不加锁的情况下,实现读与写事务完成隔离。具体机制是:
l当应用逻辑需要读取或更新数据时,数据库会创建该数据的快照,数据库中存在同一份数据的多个版本。
l每个应用逻辑拥有一份独立快照,数据更新在没有完全提交之前,其他应用逻辑不可见。
l数据库会定期清理旧版本数据,以最新版本数据替换主数据。
l数据库读通过timestamp 或 transaction id 来标识数据最新的版本。
但如果是多个写事务并发,则有可能发生冲突,可通过乐观锁来解决。
同时,我们从第一部分分析OpenDaylight能力需求中可以看出,OpenDaylight内存数据库DataStore需要具备高并发、高性能的能力,DataStore同样实现了MVCC。如果对MVCC感兴趣,可以阅读《数据库村的旺财和小强》。
2.2.2 如何实现高可靠?
DataStore作为内存数据库,在遇到突然断电或系统宕机的情况,将会是毁灭性的。因此,需要定时将数据保存到硬盘里面,也就是要做持久化的操作。
DataStore持久化的实现机制是在控制器启动时对其创建快照,并在后续操作过程记录日志。我们查看控制器的部署目录,snapshots目录用来保存快照,而journal目录用来操作日志信息,如下图所示:

现在我们将snapshots和journal目录中的文件删除掉,然后重启OpenDaylight控制器,观察目录中又重新生成对应的文件:

当发生断电或宕机等情况后,将取这两个目录的文件,恢复内存数据库。
事实上,上述实现是EV(Event Sourcing,事件溯源)思想的实现,下面我们大致介绍下EV:生活中最常见的例子就是电信运营商业务中的缴费、扣费、调账、转账以及退款等业务流程,BOSS系统中会记录每一笔交易发生的详细信息,从而能够得到某个时间点用户的“钱”是多少。因此,EV也就是将数据的增删改查每一操作都按照顺序记录,顺次保存在日志文件中,如果想回到某个时间点的状态,则可以顺次回放就可以了。
具体到DataStore内存数据库,将多个操作封装到一个事务中,并生成本次事务的操作树,持久化时按照操作日志的顺序记录下来就可以了。
2.2.3 如何实现高性能?
面对海量数据,数据库系统采用分库、分表、分区、分片等手段来实现高性能,DataStore使用了分片(Sharding)技术。
YANG建模的DataStore是一个树型结构。一个分片就是一个子树。子树之间如果存在包含关系,则被包含的子树作为一个独立的分片,事实上是从根节点按照最长路径匹配其父路径所指定的分片。整个大树是Default分片,Shard1作为一个新分片后,Default分片将不包含Shard1部分的数据,其分片类同。当启用集群后,一个分片可以位于多台机器上。如下图所示:

2.3DataStore如何访问?
MD-SAL中使用DataBroker访问DataStore:

具体的访问方式如下所示:

-
路由
+关注
关注
0文章
278浏览量
41827 -
广域网
+关注
关注
1文章
245浏览量
21797 -
sdn
+关注
关注
3文章
254浏览量
44789
发布评论请先 登录
相关推荐



TP-EIQ-BRING-YOUR-OWN-DATA-BYOD没有名为“deepview”的模块是怎么回事?
Vmware OVA 6.7模板导入6.5报错模块Nvman”打开电源失败处理方法

如何从零开始学OpenDaylight
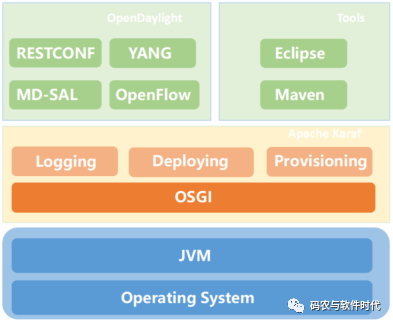
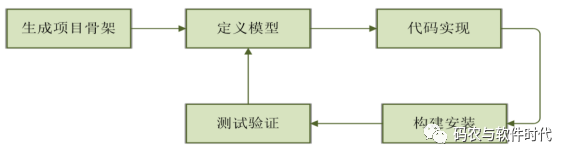
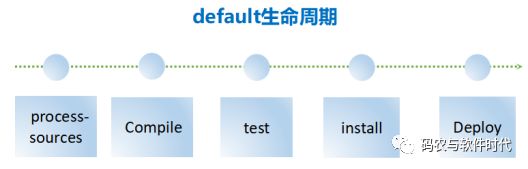
什么是OpenDaylight的Maven
OpenDaylight中的OSGi
OpenDaylight中的Karaf

OpenDaylight中的YANG
OpenDaylight中的RPC & Notification是什么
OpenDaylight中的MD-SAL是什么






 工商网监
工商网监
评论