 数据湖是什么
数据湖是什么
1.为什么出现数据湖?
支撑业务的IT软件系统最简单的数据链路是:操作业务APP的界面或者调用其API接口,将交易数据记录到关系型数据库中。
说其简单,是因为这样的系统能够支撑业务交易。业务APP上的每笔交易数据都会记录在数据库中。
这对业务交易员来说,已经足够了。但对业务管理者来说,期望看到的是“自己关心的、宏观的、能够反应历史变化的数据”,并且最好是可视化的界面,一目了然。
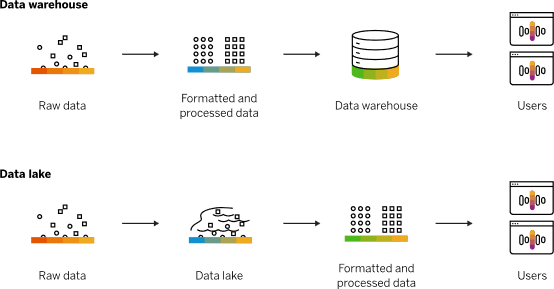
于是,“数据仓库”出现了,它就是一个面向主题的、集成的、反映历史变化的数据集合。
那么,数据是如何从业务数据库到达数据仓库的呢?
首先,要理解的是业务数据库和数据仓库的Schema(表结构)大部分情况下是不同的,前者用来记录实时交易信息,后者用来记录历史汇总信息。
其次,表结构的不同,就需要进行数据处理的三板斧--“抽取、转换和加载”,即Extract-Transform-Load,简称ETL。具体来说就是抽取管理者关心的(面向主题)、转换数据、加载到数据仓库中。
最后,根据业务规则,提取数据仓库中的数据进行可视化提取与展示(报表)。
数据仓库的使用思路是:业务管理者知道“自己关心哪些数据”,在创建数据仓库时,便可以将这些数据提取并记录下来。这样,数据仓库记录的是经过加工过的数据,而非原始数据。
注意到数据仓库的数据是结构化的。对于半结构化(CSVXMLJSON)和非结构化(e-mail文档)的数据来说,也蕴含着有价值的信息,同样需要分析,或者现在不知道怎么分析,也可以先存储起来。
那么就需要有一种方法:不但可以存储原始数据,也可以存储结构化、半结构化、非结构 化的数据,并且还能支撑数据的分析。
时势的呼唤下,“数据湖(Data Lake)”便产生了。
2.数据湖是什么?
数据湖是一个以原始格式存储数据的存储库或系统。
“数据”可以是各种格式的,结构化、半结构化的、非结构化的。并且数据是未经加工的,像大自然的水,流入到“湖”中。也就是数据的存储,无需像数据仓库那样事先设计Schema,也无需事先有明确的分析需求(有了想法,再延迟分析,称为读时模式Schema-On-Read)。
3.数据湖如何实现?
数据湖是一种方法论,探讨如何以原始形态存储各种格式的数据,并能支持后续的分析。
数据湖的开源实现有:Hadoop、Delta、Apache Iceberg 和 Apache Hudi。
-
数据库
+关注
关注
7文章
3799浏览量
64386 -
数据链路
+关注
关注
0文章
25浏览量
8943 -
软件系统
+关注
关注
0文章
63浏览量
9505 -
API接口
+关注
关注
1文章
84浏览量
10438
发布评论请先 登录
相关推荐
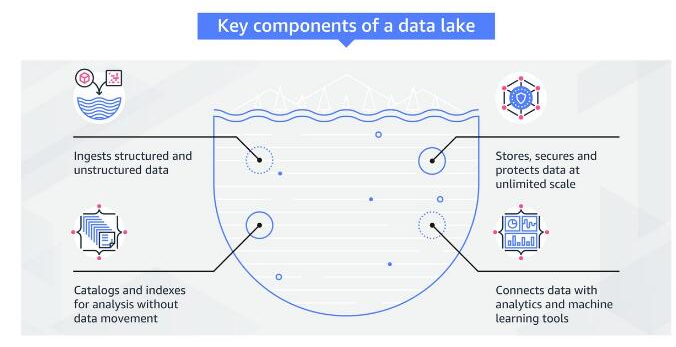
数据湖是什么,它的快速搭建方法介绍
AWS数据湖怎么脱颖而出的
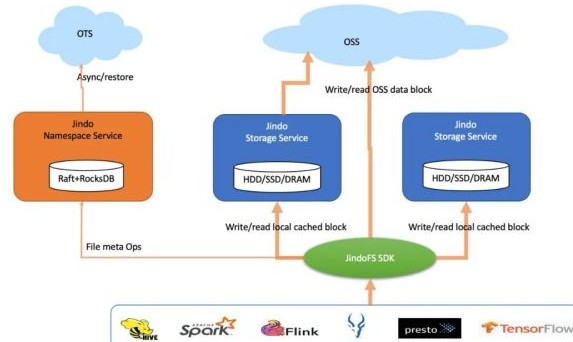
结合阿里云上的EMR JindoFS优化和实践,数据湖怎么玩“加速”?
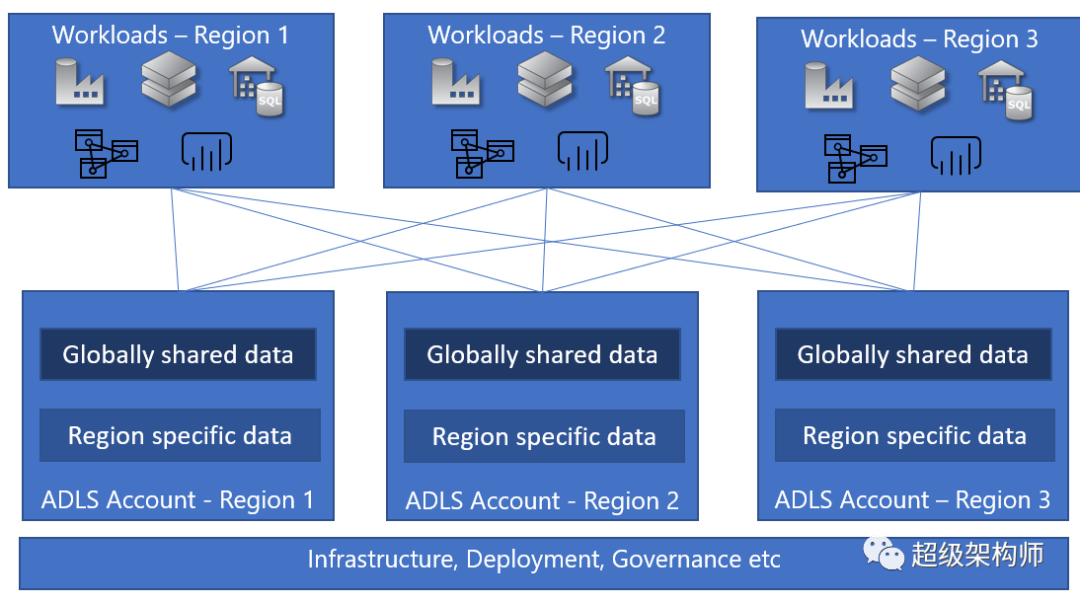
阿里云为什么要重构数据湖解决方案 主推下一代技术
阿里云宣布推出业内首个云原生企业级数据湖解决方案
虚拟化模型驱动的分布式数据湖架构设计
易华录提出面向数据湖的数据安全治理框架
如何将SAP归档数据合并到数据湖中
Azure Data Lake数据湖指南
数据湖真的能取代数据仓库吗?【SNP SAP数据转型 】
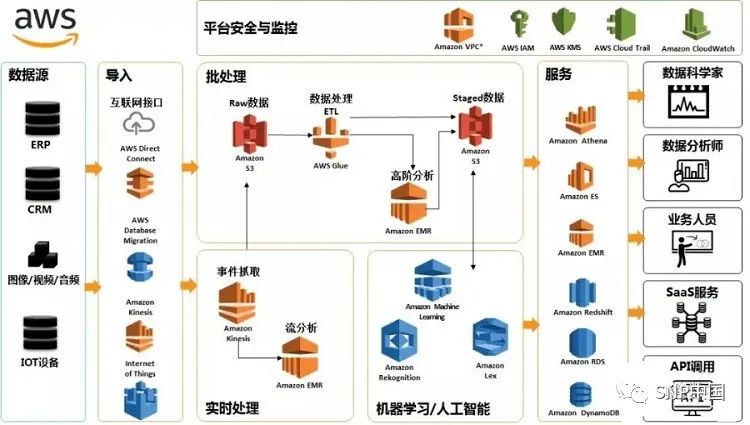
什么是数据湖?数据湖和数据仓库有什么区别?





 工商网监
工商网监
评论