 Google二进制编解码技术之Protobuf 1
Google二进制编解码技术之Protobuf 1
计算机网络编程中一个非常基本的问题:该怎样表示client与server之间交互的数据,在往下看之前先想一想这个问题。
共识与协议
这个问题可不像看上去的那样简单,因为client进程和server进程运行在不同的机器上,这些机器可能运行在不同的处理器平台、可能运行在不同的操作系统、可能是由不同的编程语言编写的,server要怎样才能识别出client发送的是什么数据呢?就像这样: client给server发送了一段数据:
client给server发送了一段数据:
0101000100100001
server怎么能知道该怎样“解读”这段数据呢?
显然,client和server在发送数据之前必须首先达成某种关于怎样解读数据的共识,这就是所谓的 协议 。
这里的协议可以是这样的:“将每8个比特为一个单位解释为无符号数字”,如果协议是这样的,那么server接收到这串二进制后就会将其解析为81(01010001)与33(00100001)。
当然,这里的协议也可以是这样的:“将每8个比特为一个单位解释为ASCII字符”,那么server接收到这串二进制后就将其解析为“Q!”。
可见,同样一串二进制在不同的“上下文/协议”下有完全不一样的解读,这也是为什么计算机明明只认知0和1但是却能处理非常复杂任务的根本原因,因为一切都可以编码为0和1,同样的我们也可以从0和1中解析出我们想要的信息,这就是所谓的编解码技术。
实际上不止0和1,我们也可以将信息编码为摩斯密码(Morse code)等,只不过计算机擅长处理0和1而已。
扯远了,回到本文的主题。
远程过程调用:RPC
作为程序员我们知道,client以及server之间不会简单传递一串数字以及字符这样简单,尤其在互联网大厂后端服务这种场景下。
当我们在电商App搜索商品、打车App呼叫出租车以及刷短视频时,每一次请求的背后在后端都涉及大量服务之间的交互,就像这样:
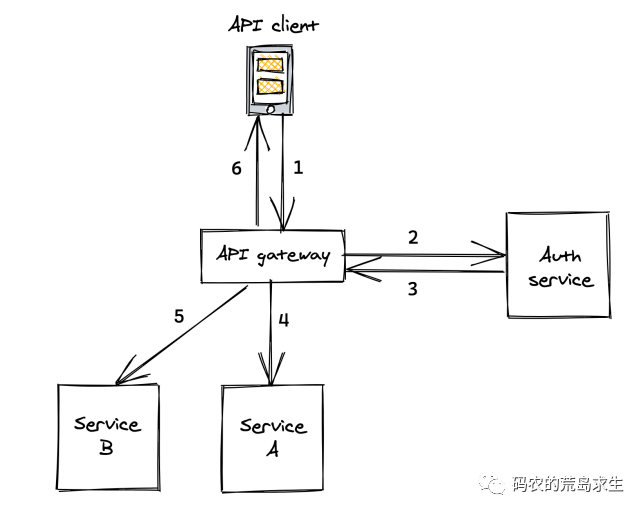
完成一次客户端请求gateway这个服务要调用N多个下游服务,所谓调用是说A服务向B服务发送一段数据(请求),B服务接收到这段数据后执行相应的函数,并将结果返回给A服务。
只不过对于服务A来说并不想关心网络传输这样的底层细节,如果能像调用本地函数一样调用远程服务就好了,这就是所谓的RPC,经典的实现方式是这样的:
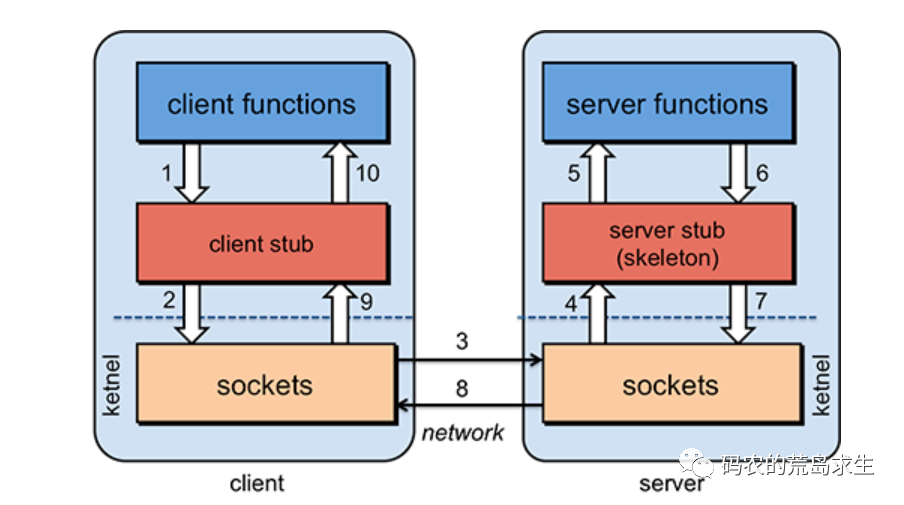
RPC对上层提供和普通函数一样的接口,只不过在实现上封装了底层复杂的网络通信,RPC框架是当前互联网后端的基石之一,很多所谓互联网后端的职位无非就是在此基础之上堆业务逻辑。
本文我们不关心其中的细节,这里我们只关心在网络层client是怎样对请求参数进行编码、server怎样对请求参数进行解码的,也就是本文开头提出的问题。
信息的编解码
在思考怎样进行编解码之前我们必须意识到:
- client和server可能是用不同语言编写的,你的编解码方案必须通用且不能和语言绑定
- 编解码方法的性能问题,尤其是对时间要求苛刻的服务
首先,我们最应该能想到的就是以纯文本的形式来表示。
纯文本从来都是一种非常有友好的信息载体,为什么?很简单,因为人类(我们)可以直接看懂,就像这段:
{
"widget": {
"window": {
"title": "Sample Konfabulator Widget",
"name": "main_window",
"width": 500,
"height": 500
},
"image": {
"src": "Images/Sun.png",
"name": "sun1",
"hOffset": 250,
"vOffset": 250,
},
}
}
是不是很清晰,一目了然,只要我们实现约定好文本的结构(也就是语法),那么client和server就能利用这种文本进行信息的编码以及解码,不管client和server是运行在x86还是Arm、是32位的还是64位的、运行在Linux上还是windows上、是大端还是小端,都可以无障碍交流。
因此在这里,文本的语法就是一种协议。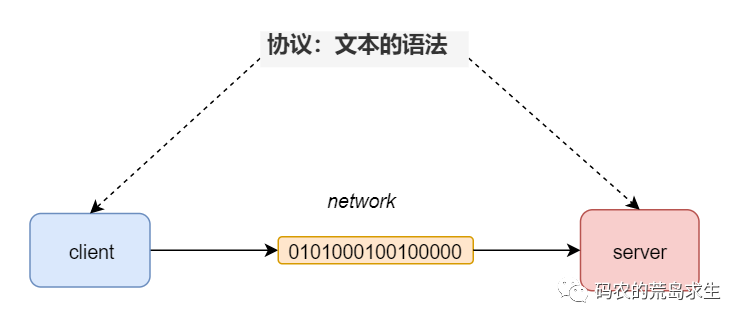 顺便说一句, 你都规定好了文本的语法,实际上就相当于发明了一种语言 。
顺便说一句, 你都规定好了文本的语法,实际上就相当于发明了一种语言 。
这里用来举例用的语言就是所谓的Json,只不过json这种语言不是用来表示逻辑(代码)而是用来存储数据的。
Json就是这个老头提出来的:
除了Json,另一种利用文本存储数据的表示方法是XML,来一段感受下:
<note>
<to>Toveto>
<from>Janifrom>
<heading>Reminderheading>
<body>Don't forget me this weekend!body>
note>
相对Json来说是不是就没那么容易看懂了,Json出现后在web领域逐渐取代了XML。
当两段数据量很少的时候——就像浏览器和服务端的交互,Json可以工作的非常好,这个场景就是这里: 在这里是json的天下。
在这里是json的天下。
但对于后端服务之间的交互来说就不一样了,后端服务之间的RPC调用可能会传输大量数据,如果全部用纯文本的形式来表示数据那么不管是网络带宽还是性能可能都会差强人意。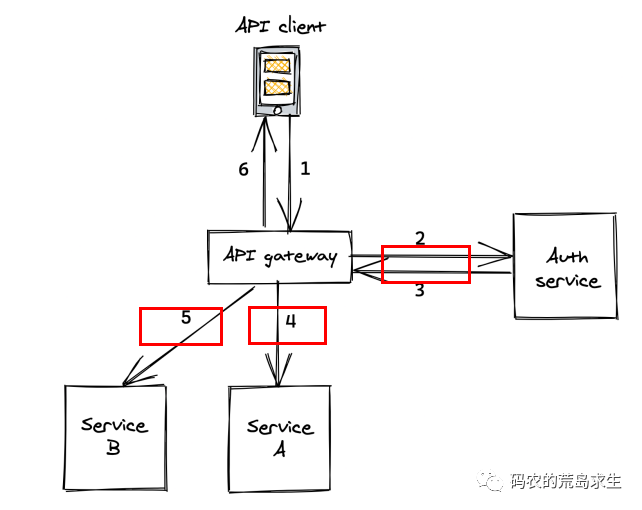
在这种场景下,Json并不是最好的选项,主要原因之一就在于性能以及数据的体积。
我们知道,文本表示对人类是最友好的,对机器来说则不是这样,对机器来说最好的还是01二进制。
那么有没有二进制的编码方法吗?答案是肯定的,这就是当前互联网后端中流行的protobuf,Google公司开源项目。
那么protobuf有什么神奇之处吗?
假设client端想给server端传输这样一段信息:“我有一个id,其值为43”,那么在XML下是这样表示的:
<id>43id>
数一数这这段数据占据了多少字节,很显然是11字节;
而如果用json来表示呢?
{"id":43}
数一数这段数据占据了多少字节,显然是9字节;
而如果用protobuf来表示呢? 是这样的:
// 消息定义
message Msg {
optional int32 id = 1;
}
// 实例化
Msg msg;
msg.set_id(43);
其中Msg的定义看上去比Json和XML更加复杂了,但这些只是给人看的,这些还会被protbuf进一步处理,最终被编码为:
082b
也就是0x08与0x2b,这占据了多少字节呢?答案是2字节。
从json的9字节到protobuf的2字节,数据大小减少了4倍多,数据量的减少意味着:
- 更少的网络带宽
- 更快的解析速度
那么protobuf是怎样做到这一点的呢?
-
计算机
+关注
关注
19文章
7494浏览量
87966 -
Server
+关注
关注
0文章
90浏览量
24037 -
网络编程
+关注
关注
0文章
71浏览量
10075
发布评论请先 登录
相关推荐
探讨2对4二进制解码器及4到16二进制解码器配置

二进制数的运算规则
什么是二进制计数器,二进制计数器原理是什么?
二进制电平,什么是二进制电平
二进制解码器到底是什么






 工商网监
工商网监
评论