 Google二进制编解码技术之Protobuf 3
Google二进制编解码技术之Protobuf 3
字段名称与字段类型
对于任何一个有用的信息都包含这样几部分:
- 字段名称
- 字段类型
- 字段值
就像C/C++中定义变量时:
int i = 100;
在这里,字段名称就是i,字段类型是int,字段值是100。
刚才我们用varint以及ZigZag编码解决了字段值表示的问题,那么该怎样表示字段名称和字段类型呢?
首先,对于字段类型还比较简单,因为字段类型就那么多,protobuf中定义了6种字段类型:
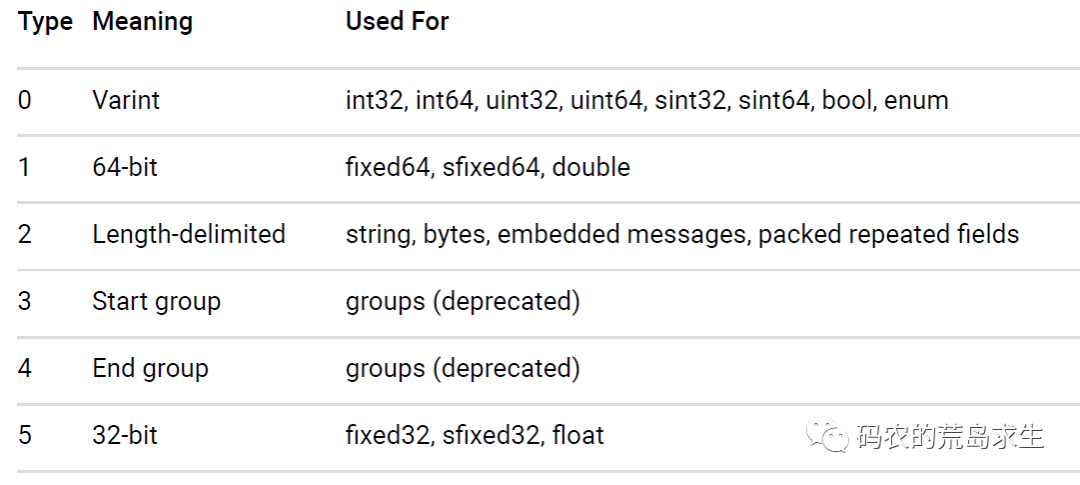
对于6种字段类型我们使用3个比特位来表示就足够了。
接下来比较有趣的是字段名称该怎么表示呢?假设我们需要传递这样一个字段:
int long_long_name = 100;
那么我们真的需要把“long_long_name”这么多字符通过网络传递给对端吗?
既然通信双方需要协议,那么“long_long_name”这字段其实是client和server都知道的,它们唯一不知道的就是“ 哪些值属于哪些字段 ”。
为解决这个问题, 我们给每个字段都进行编号 ,比如通信双方都知道“long_long_name”这个字段的编号是2,那么对于:
int long_long_name = 100;
这个信息我们只需要传递:
- 字段名称:2 (2对应字段“long_long_name”)
- 字段类型:0 (0表示varint类型,参见上图)
- 字段值:100
所以我们可以看到, 无论你用多么复杂的字段名称也不会影响编码后占据的空间,字段名称根本就不会出现在编码后的信息中, so clever。
从宏观上看
我们已经在protobuf中看到了数字以及字段名称以及字段类型是怎么表示了,现在是时候从宏观角度来看看多个字段该怎么编码了。
从本质上讲,protobuf被编码后形成一系列的key-value,每个key-value对应一个proto中的字段。
也就是键值对:

其中value比较简单,也就是字段值;而字段名称和字段类型会被拼接成key,protobuf中共有6种类型,因此只需要3个比特位即可;字段名称只需要存储对应的编号,这样可以就可以这样编码:
(字段编号 << 3) | 字段类型
假设server接收到了一个key为0x08,其二进制的表示为:
0000 1000
由于key也是利用varint编码的,因此需要将第一个比特位去掉,这样我的得到:
000 1000
根据key的编码方式,其后三个比特位表示字段类型,即:
000
也就是0,这样我们知道该key的类型是Varint(第0号类型),而字段编号为抹掉后3个比特位的值,即:
0001
这样,我们就知道了该key对应的字段编号为1,得到编号我们就能根据编号找到对应的编号名称。
嵌套数据
与Json和XML类似,protobuf中也支持嵌套消息,就像这样:
message SubMsg {
optional int32 id = 1;
}
message Msg {
optional SubMsg msg = 1;
}
其实现也比较简单,这依然遵循被编码后形成一系列的key-value,只不过对于嵌套类型的key来说,其value是由子消息的key-value组成。

protobuf与编译语言
与Json一样,protobuf也是一门语言,兼具了文本的可读性以及二进制的高效。
protobuf之所以能做到这一点就好比C语言与机器指令。
C语言是给程序员看的,可读性好,而机器指令是给硬件使用的,性能好,编译器会将C语言程序转为机器可执行的机器指令。
而protobuf也一样,protobuf也是一门语言,会将可读性较好的消息编码为二进制从而可以在网络中进行传播,而对端也可以将其解码回来。
在这里protobuf中定义的消息就好比C语言,编码后的二进制消息就好比机器指令。
而protobuf作为事实上语言必然有自己的语法,其语法就是这样:

怎么样,还觉得编译原理没什么用吗?
不理解编译原理是不可能发明protobuf这种技术的。
总结
我在写这篇文章时不断感叹,Google的这项技术节省了多少程序员的时间,同时我们也能看到这种基石般的技术依赖的底层原理却非常古老:
- 信息的编解码
- 编译原理
怎么样,这些是不是远远没有IT界各种流行的技术听上去时髦有趣,而正是这种朴素的技术支撑起了工业界,现在你也应该能明白底层技术的重要性了吧。
-
计算机
+关注
关注
19文章
7389浏览量
87671 -
Server
+关注
关注
0文章
90浏览量
23993 -
网络编程
+关注
关注
0文章
71浏览量
10057
发布评论请先 登录
相关推荐
探讨2对4二进制解码器及4到16二进制解码器配置

什么是二进制计数器,二进制计数器原理是什么?
二进制电平,什么是二进制电平
基于软件二进制代码重用技术综述
二进制解码器到底是什么






 工商网监
工商网监
评论