 算法是指什么?算法概述
算法是指什么?算法概述
一、算法概述
算法是指解题方案的准确而完整的描述,是一系列解决问题、高度符合逻辑性、可执行性的指令集合,代表运用系统方法描述解决问题的策略机制。算法能够对一定规范的输入在有限时间内运行得到输出。
算法中的指令描述的是计算过程,当其运行时能从初始状态和初始输入(初始输入可能为空的)开始,经过一系列有限而清晰定义的状态,最终产生输出并终止于某一状态。
不同的算法在解决相同问题所需时间、空间可能不同,即算法的效率不同。算法的优劣可通过解决相同问题所需的时间复杂度与空间复杂度衡量。
二、传统算法与大数据算法
传统的数据算法可被称为数据分析,数据分析的目的在于对已有的数据进行描述性分析,其重点在于发现数据隐含的规律,进行商业分析和处理。
大数据时代的数据算法可被称为数据科学,与数据挖掘和机器学习相关。
机器学习是交叉学科,机器学习涉及的学科包括概率论、统计学、逼近论、图分析、算法复杂度理论等。机器学习主要研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,并重新组织已有的知识结构使之不断改善自身性能。
大数据机器学习更强调学习是手段。机器学习成为一种支持和服务技术,基于机器学习对复杂多样的数据进行深层次的分析和更高效地利用信息成为大数据机器学习研究的主要方向。所以,大数据机器学习逐渐向智能数据分析的方向发展,并已成为智能数据分析技术的重要组成部分。
大数据时代,数据体量以空前的速度增长,需要分析新类型数据也在不断出现,新类型数据包括:文本理解、文本情感分析、图像的检索和理解、图形和网络等。数据体量快速增长和新类型数据不断出现使得大数据机器学习和数据挖掘等智能计算技术在大数据智能化分析处理应用中具有重要作用。 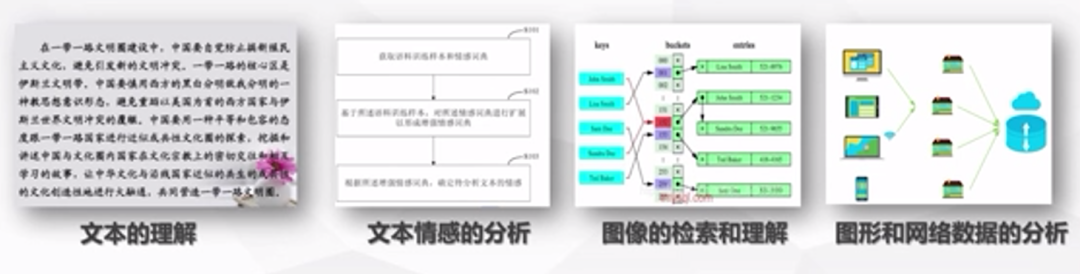
图片来源:学堂在线《大数据导论》
三、机器学习算法
目前,主流的机器学习算法包括:监督学习和非监督学习。
(1)监督学习
监督学习是指从标记的训练数据推断某一功能的机器学习任务,训练数据包括一套训练示例。每套训练示例均由一个输入对象(通常为矢量)和一个期望的输出值 (也称为监督信号)组成。监督学习算法通过分析训练示例(个人理解:需分析多套训练示例),产生某种推断功能,该推断功能可以用于映射新示例。
监督学习包括:分类算法和回归分析。
1)分类算法包括:自然贝叶斯、决策树、随机森林、神经网络等。分类算法主要针对离散数据。
2)回归类算法包括:线性回归、逻辑回归、支持向量机等。回归类算法主要针对连续数据。
(2)非监督学习
非监督学习是指在没有类别信息情况下,通过分析所研究对象大量样本的据数,实现样本分类的数据处理方法。
通过非监督式学习,可将样本集划分为若干个子集(类别),或将样本集作为训练样本集,再通过监督学习方法进行分类器设计。
非监督学习包括:聚类算法、抽维算法。
1)聚类算法包括:距离聚类、快速聚类等。
2)抽维算法包括:主因子、典型相关等。
审核编辑:刘清
-
神经网络
+关注
关注
42文章
4793浏览量
102023 -
机器学习
+关注
关注
66文章
8473浏览量
133735 -
大数据
+关注
关注
64文章
8934浏览量
138905
原文标题:大数据相关介绍(8)——算法
文章出处:【微信号:行业学习与研究,微信公众号:行业学习与研究】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
PID控制算法的C语言实现:PID算法原理
深入解析ECC256椭圆曲线加密算法
【「从算法到电路—数字芯片算法的电路实现」阅读体验】+内容简介
【「从算法到电路—数字芯片算法的电路实现」阅读体验】+介绍基础硬件算法模块
【「从算法到电路—数字芯片算法的电路实现」阅读体验】+一本介绍基础硬件算法模块实现的好书
激光雷达在SLAM算法中的应用综述





 工商网监
工商网监
评论