 在利用OpenVINO在英特尔处理器上实现1000+ FPS性能
在利用OpenVINO在英特尔处理器上实现1000+ FPS性能
!作为目标检测领域著名的模型家族,you only look once (YOLO) 推 出新模型的速度可谓是越来越快。
就在刚刚过去的1月份,YOLO又推出了最新的YOLOv8模型,其模型结构和架构上的创新以及所提供的性能提升,使得它刚刚面世,就获得了广大开发者的关注。
YOLOv8的性能到底怎么样?如果说利用OpenVINO的量化和加速,利用英特尔CPU、集成显卡以及独立显卡与同一代码库无缝协作,可以获得1000+ FPS的性能,你相信吗?
那不妨继续往下看,我们将手把手的教你在利用OpenVINO在英特尔处理器上实现这一性能。
| 图1. YOLOv8推理结果示例 好的,让我们开始吧。 注意:以下步骤中的所有代码来自OpenVINO Notebooks开源仓库中的230-yolov8-optimization notebook 代码示例。
01安装相应工具包及加载模型
本次代码示例我们使用的是Ultralytics YOLOv8模型,因此需要首先安装相应工具包。
1.!pipinstall"ultralytics==8.0.5"
1.fromultralyticsimportYOLO
2.
3.MODEL_NAME="yolov8n"
4.
5.model=YOLO(f'{MODEL_NAME}.pt')
6.
7.label_map=model.model.names
定义测试图片的地址,获得原始PyTorch模型的推理结果:
1.IMAGE_PATH="../data/image/coco_bike.jpg"
2.results=model(IMAGE_PATH,return_outputs=True)
其运行效果如下
为将目标检测的效果以可视化的形式呈现出来,需要定义相应的函数,最终运行效果如下图所示:
02将模型转换为OpenVINOIR格式
为获得良好的模型推理加速,并更方便的部署在不同的硬件平台上,接下来我们首先将YOLO v8模型转换为OpenVINO IR模型格式。
YOLOv8提供了用于将模型导出到不同格式(包括OpenVINO IR格式)的API。
model.export负责模型转换。
我们需要在这里指定格式,此外,我们还可以在模型中保留动态输入。
1.frompathlibimportPath
2.
3.model_path=Path(f"{MODEL_NAME}_openvino_model/{MODEL_NAME}.xml")
4.ifnotmodel_path.exists():
5.model.export(format="openvino",dynamic=True,half=False)
接下来我们来测试一下转换后模型的准确度如何。运行以下代码,并定义相应的前处理、后处理函数。
1.fromopenvino.runtimeimportCore,Model
2.
3.core=Core()
4.ov_model=core.read_model(model_path)
5.device="CPU"#GPU
6.ifdevice!="CPU":
7.ov_model.reshape({0:[1,3,640,640]})
8.compiled_model=core.compile_model(ov_model,device)
在单张测试图片上进行推理,可以得到如下推理结果:
03在数据集上验证模型准确度
YOLOv8是在COCO数据集上进行预训练的,因此为了评估模型的准确性,我们需要下载该数据集。
根据YOLOv8 GitHub仓库中提供的说明,我们还需要下载模型作者使用的格式的标注,以便与原始模型评估功能一起使用。
1.importsys
2.fromzipfileimportZipFile
3.
4.sys.path.append("../utils")
5.fromnotebook_utilsimportdownload_file
6.
7.DATA_URL="http://images.cocodataset.org/zips/val2017.zip"
8.LABELS_URL="https://github.com/ultralytics/yolov5/releases/download/v1.0/coco2017labels-segments.zip"
9.
10.OUT_DIR=Path('./datasets')
11.
12.download_file(DATA_URL,directory=OUT_DIR,show_progress=True)
13.download_file(LABELS_URL,directory=OUT_DIR,show_progress=True)
14.
15.ifnot(OUT_DIR/"coco/labels").exists():
16.withZipFile(OUT_DIR/'coco2017labels-segments.zip',"r")aszip_ref:
17.zip_ref.extractall(OUT_DIR)
18.withZipFile(OUT_DIR/'val2017.zip',"r")aszip_ref:
19.zip_ref.extractall(OUT_DIR/'coco/images')
接下来,我们配置DetectionValidator并创建DataLoader。原始模型存储库使用DetectionValidator包装器,它表示精度验证的过程。
它创建DataLoader和评估标准,并更新DataLoader生成的每个数据批的度量标准。
此外,它还负责数据预处理和结果后处理。对于类初始化,应提供配置。
我们将使用默认设置,但可以用一些参数替代,以测试自定义数据,代码如下。
1.fromultralytics.yolo.utilsimportDEFAULT_CONFIG
2.fromultralytics.yolo.configsimportget_config
3.args=get_config(config=DEFAULT_CONFIG)
4.args.data="coco.yml"
1.validator=model.ValidatorClass(args)
2.
3.data_loader=validator.get_dataloader("datasets/coco",1)
Validator配置代码如下:
1.fromtqdm.notebookimporttqdm
2.fromultralytics.yolo.utils.metricsimportConfusionMatrix
3.
4.validator.is_coco=True
5.validator.class_map=ops.coco80_to_coco91_class()
6.validator.names=model.model.names
7.validator.metrics.names=validator.names
8.validator.nc=model.model.model[-1].nc
定义验证函数,以及打印相应测试结果的函数,结果如下: 
04利用NNCFPOT量化API进行模型优化
Neural network compression framework (NNCF) 为OpenVINO中的神经网络推理优化提供了一套先进的算法,精度下降最小。
我们将在后训练(Post-training)模式中使用8位量化(无需微调)来优化YOLOv8。
优化过程包括以下三个步骤:
1)建立量化数据集Dataset;
2)运行nncf.quantize来得到优化模型
3)使用串行化函数openvino.runtime.serialize来得到OpenVINO IR模型。
建立量化数据集代码如下:
1.importnncf#noqa:F811
2.fromtypingimportDict
3.
4.
5.deftransform_fn(data_item
6."""
7.Quantizationtransformfunction.Extractsandpreprocessinputdatafromdataloaderitemforquantization.
9.data_item:DictwithdataitemproducedbyDataLoaderduringiteration
10.Returns:
11.input_tensor:Inputdataforquantization
12."""
13.input_tensor=validator.preprocess(data_item)['img'].numpy()
14.returninput_tensor
15.
16.
17.quantization_dataset=nncf.Dataset(data_loader,transform_fn)
运行nncf.quantize代码如下:
1.quantized_model=nncf.quantize(
2.ov_model,
3.quantization_dataset,
4.preset=nncf.QuantizationPreset.MIXED,
5.ignored_scope=nncf.IgnoredScope(
6.types=["Multiply","Subtract","Sigmoid"],#ignoreoperations
7.names=["/model.22/dfl/conv/Conv",#inthepost-processingsubgraph
8."/model.22/Add",
9."/model.22/Add_1",
10."/model.22/Add_2",
11."/model.22/Add_3",
12."/model.22/Add_4",
13."/model.22/Add_5",
14."/model.22/Add_6",
15."/model.22/Add_7",
16."/model.22/Add_8",
17."/model.22/Add_9",
18."/model.22/Add_10"]
19.))
最终串行化函数代码如下:
1.fromopenvino.runtimeimportserialize
2.int8_model_path=Path(f'{MODEL_NAME}_openvino_int8_model/{MODEL_NAME}.xml')
3.print(f"Quantizedmodelwillbesavedto{int8_model_path}")
4.serialize(quantized_model,str(int8_model_path))
运行后得到的优化的YOLOv8模型保存在以下路径:
yolov8n_openvino_int8_model/yolov8n.xml
接下来,运行以下代码在单张测试图片上验证优化模型的推理结果:
1.ifdevice!="CPU":
2.quantized_model.reshape({0,[1,3,640,640]})
3.quantized_compiled_model=core.compile_model(quantized_model,device)
4.input_image=np.array(Image.open(IMAGE_PATH))
5.detections=detect(input_image,quantized_compiled_model)[0]
6.image_with_boxes=draw_boxes(detections,input_image)
7.
8.Image.fromarray(image_with_boxes)
运行结果如下:
验证下优化后模型的精度,运行如下代码:
1.print("FP32modelaccuracy")
2.print_stats(fp_stats,validator.seen,validator.nt_per_class.sum())
3.
4.print("INT8modelaccuracy")
5.print_stats(int8_stats,validator.seen,validator.nt_per_class.sum())
得到结果如下:
可以看到模型精度相较于优化前,并没有明显的下降。
05比较优化前后模型的性能
接着,我们利用OpenVINO 基线测试工具https://docs.openvino.ai/latest/openvino_inference_engine_tools_benchmark_tool_README.html 来比较优化前(FP32)和优化后(INT8)模型的性能。
在这里,我们分别在英特尔至强第三代处理器(Xeon Ice Lake Gold Intel 6348 2.6 GHz 42 MB 235W 28 cores)上运行CPU端的性能比较。
针对优化前模型的测试代码和运行结果如下:
1.#InferenceFP32model(OpenVINOIR)
2.!benchmark_app-m$model_path-dCPU-apiasync-shape"[1,3,640,640]"
FP32模型性能: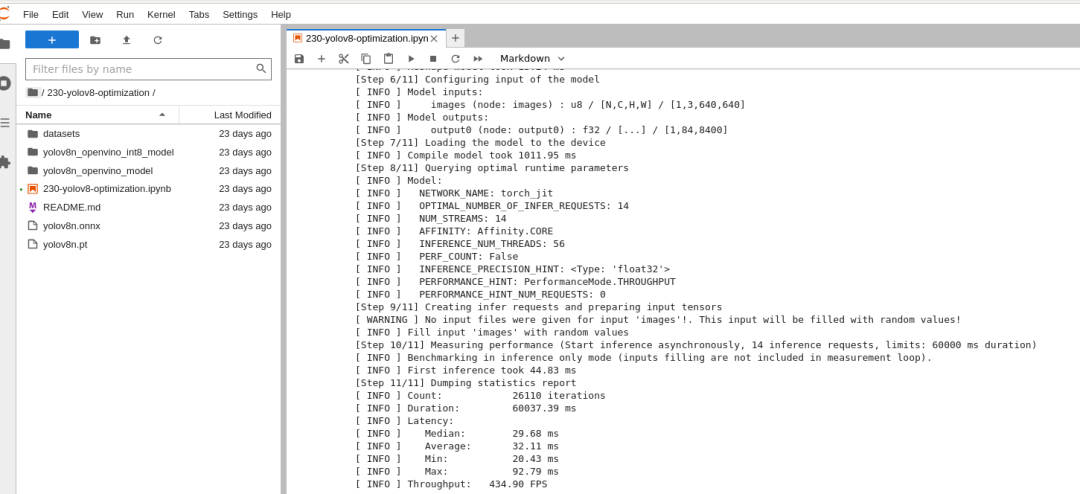
INT8模型性能: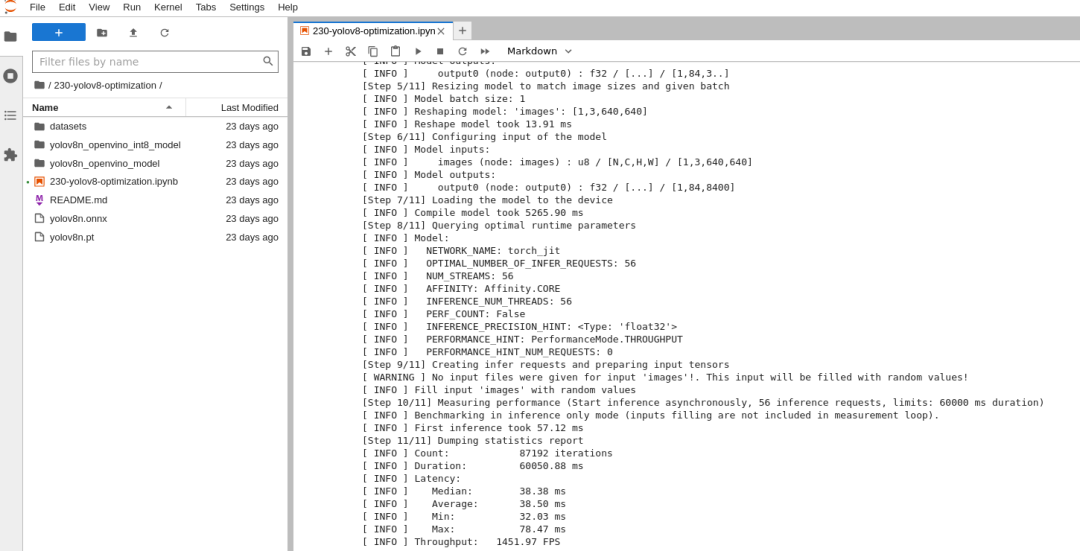
已经达到了1400+ FPS! 在英特尔独立显卡上的性能又如何呢?我们在Arc A770m上测试效果如下: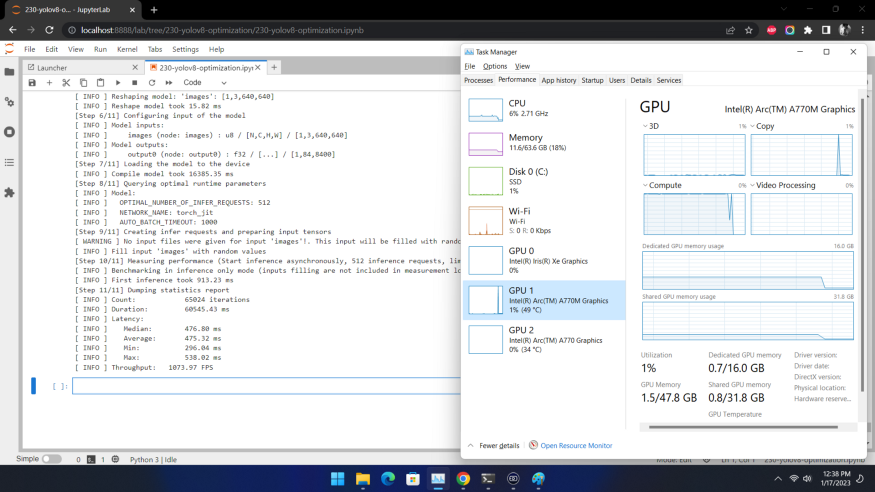
也超过了1000 FPS!
需要注意的是要想获得如此的高性能,需要将推理运行在吞吐量模式下,并使用多流和多个推理请求(即并行运行多个)。
同样,仍然需要确保对预处理和后处理管道进行微调,以确保没有性能瓶颈。
06利用网络摄像头运行实时测试
除了基线测试工具外,如果你想利用自己的网络摄像头,体验一下实时推理的效果,可以运行我们提供的实时运行目标检测函数:
1.run_object_detection(source=0,flip=True,use_popup=False,model=ov_model,device="AUTO")
获得类似如下图的效果: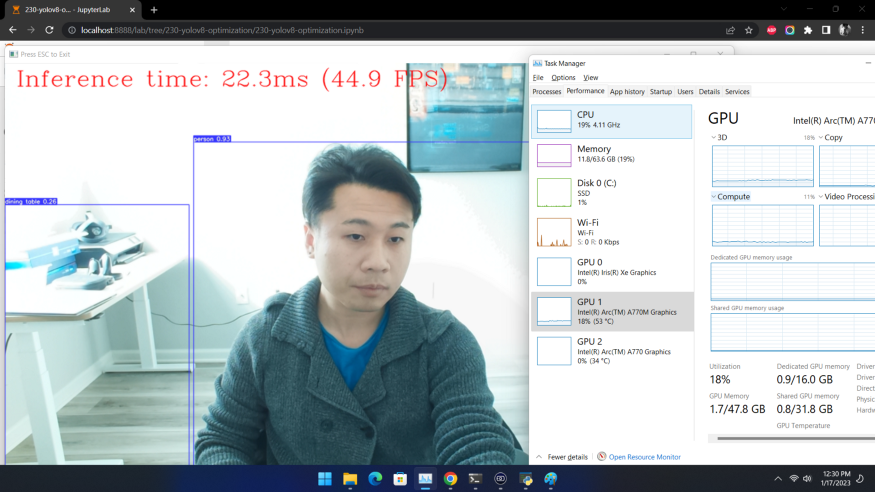
07进一步提升性能的小技巧
非同步推理流水线
在进行目标检测的推理时,推理性能常常会因为数据输入量的限制而受到影响。此时,采用异步推理的模型,可以进一步提升推理的性能。异步API的主要优点是,当设备忙于推理时,应用程序可以并行执行其他任务(例如填充输入或调度其他请求),而不是等待当前推理首先完成。
使用预处理API
预处理API允许将预处理作为模型的一部分,从而减少应用程序代码和对其他图像处理库的依赖。预处理API的主要优点是将预处理步骤集成到执行图中,并将在选定的设备(CPU/GPU/VPU/等)上执行,而不是作为应用程序的一部分始终在CPU上执行。这将提高所选设备的利用率。
对于本次YOLOv8示例来说,预处理API的使用包含以下几个步骤:
1.初始化PrePostProcessing对象
20.fromopenvino.preprocessimportPrePostProcessor
21.
22.ppp=PrePostProcessor(quantized_model)
2.定义输入数据格式
1.fromopenvino.runtimeimportType,Layout
2.
3.ppp.input(0).tensor().set_shape([1,640,640,3]).set_element_type(Type.u8).set_layout(Layout('NHWC'))
4.pass
3.描述预处理步骤 预处理步骤主要包括以下三步: ·将数据类型从U8转换为FP32 ·将数据布局从NHWC转换为NCHW格式 ·通过按比例因子255进行除法来归一化每个像素
代码如下:
1.ppp.input(0).preprocess().convert_element_type(Type.f32).convert_layout(Layout('NCHW')).scale([255.,255.,255.])
2.
3.print(ppp)
4.将步骤集成到模型中
1.quantized_model_with_preprocess=ppp.build()
2.serialize(quantized_model_with_preprocess,str(int8_model_path.with_name(f"{MODEL_NAME}_with_preprocess.xml")))
具有集成预处理的模型已准备好加载到设备。现在,我们可以跳过检测函数中的这些预处理步骤,直接运行如下推理:
1.defdetect_without_preprocess(image:np.ndarray,model
2."""
3.OpenVINOYOLOv8modelwithintegratedpreprocessinginferencefunction.Preprocessimage,runsmodelinferenceandpostprocessresultsusingNMS.
4.Parameters:
5.image(np.ndarray):inputimage.
6.model(Model):OpenVINOcompiledmodel.
7.Returns:
8.detections(np.ndarray):detectedboxesinformat[x1,y1,x2,y2,score,label]
9."""
10.output_layer=model.output(0)
11.img=letterbox(image)[0]
12.input_tensor=np.expand_dims(img,0)
13.input_hw=img.shape[:2]
14.result=model(input_tensor)[output_layer]
15.detections=postprocess(result,input_hw,image)
16.returndetections
17.
18.
19.compiled_model=core.compile_model(quantized_model_with_preprocess,device)
20.input_image=np.array(Image.open(IMAGE_PATH))
21.detections=detect_without_preprocess(input_image,compiled_model)[0]
22.image_with_boxes=draw_boxes(detections,input_image)
23.
24.Image.fromarray(img_with_boxes)
小 结
整个的步骤就是这样!现在就开始跟着我们提供的代码和步骤,动手试试用Open VINO优化和加速YOLOv8吧。
审核编辑:刘清
-
处理器
+关注
关注
68文章
19259浏览量
229642 -
FPS
+关注
关注
0文章
35浏览量
11980 -
pytorch
+关注
关注
2文章
807浏览量
13197
原文标题:如何用OpenVINO™让YOLOv8获得1000+ FPS性能?
文章出处:【微信号:SDNLAB,微信公众号:SDNLAB】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论