 大数据系统包括哪些
大数据系统包括哪些
目前,主流的大数据平台包括:Hadoop、Spark。
Hadoop是分布式(根据网络资料理解:分布式与集中式相对应,对于大量数据计算,集中于一台计算机中计算需耗费较长时间,通过将计算分布于多个计算机,节约整体计算时间)系统基础架构。Hadoop的两个功能包括:数据存储(HDFS)、数据处理(MapReduce)。
Spark是专为大规模数据处理而设计的快速通用计算引擎。Spark不提供文件管理系统,没有数据存储功能;Spark的数据计算基于内存实现,数据处理速度快。
一、HDFS(分布式文件存储)
数据通过HDFS放置于一个Hadoop集群中,Hadoop集群通常由几台至上千台的计算机组成。根据课程介绍理解,百度公司最大的Hadoop集群已超过4000台计算机。
数据在存储于HDFS前,被分割成若干数据块,每个数据块储存于一台计算机中。不同Hadoop版本所分割的数据块大小不同,Hadoop1.0版本中数据块大小为64MB,Hadoop2.0版本中数据块大小为128MB。Hadoop也可以设置数据块大小(含个人理解)。
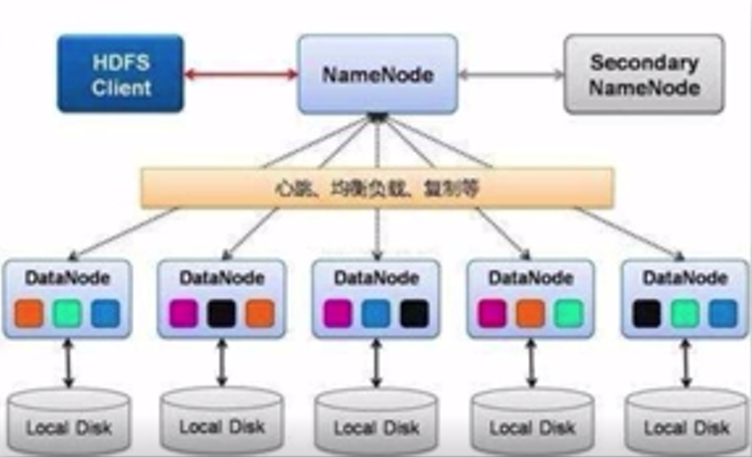
图片来源:学堂在线《大数据导论》
二、MapReduce(分布式数据处理架构)
MapReduce是分布式计算框架。开发人员在运用MapReduce处理数据时,MapReduce将指定某一Map函数,将一组键值对(根据网络资料理解:键值对可以根据一个值获得对应的一个值)映射成一组新的键值对,并指定并发的Reduce函数,保证所有Map函数映射的结果可以进行Reduce规约(根据网络资料理解:通过某一连接动作将所有元素汇总为一个结果的过程)运算。
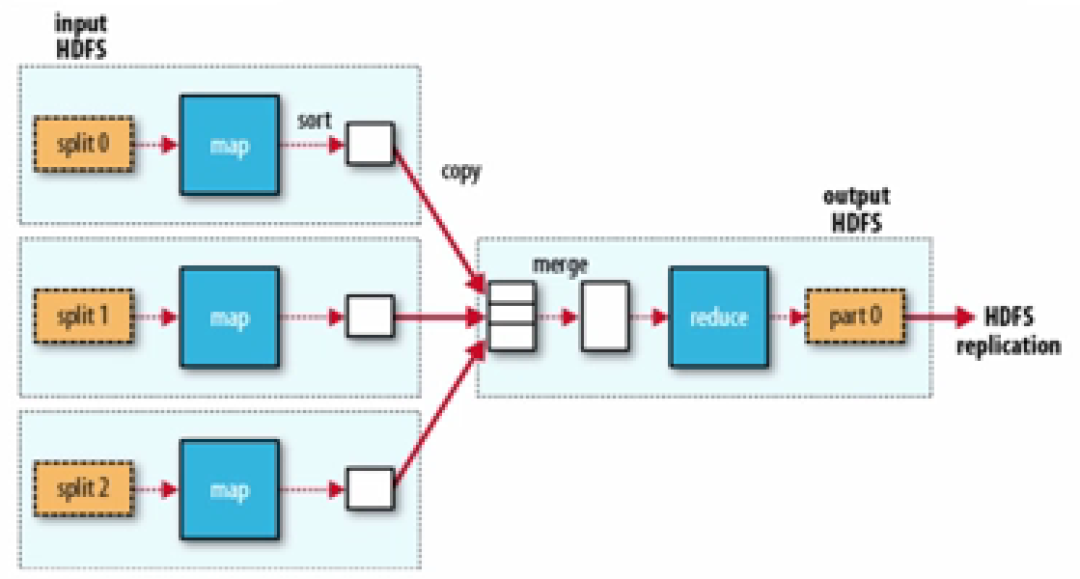
图片来源:学堂在线《大数据导论》
在运用MapReduce框架编写计算机程序时,开发人员只需考虑业务逻辑,不需考虑并行管理。
WordCount是统计文件夹所有文本中某一词出现的次数。
其中,WordCount的Map函数程序代码如下:
Map(K, V){
For each word w in V
Collect(w,1);
}
WordCount的Map函数中的K代表文本中的词,WordCount的Map函数的功能是将文本中的每个词与1建立键值对,即每个词对应一个“1”。
WordCount的Reduce函数程序代码如下:
Reduce(K.V[]){
int count=0;
For each v in V
count+= v;
Collect(K,count);
}
WordCount的Reduce函数将经过WordCount的Map函数处理的相同词对应的“1”求和,得出某一词的出现的次数。
该WordCount示例中,Map和Reduce函数的具体运行如图一所示:
首先,所有数据被整理成单行数据,图一流程图中具有三个节点(个人理解:节点可被认为是计算机),图一中的三行数据被分行输入到三个节点中。
然后,Map函数运行,将每个词与1建立键值对。
Map函数运行结束后,Shuffle过程运行,Shuffle过程是MapReduce内设过程,可将具有相同词的键值对中的“1”集合至一个List(列表)中。如图一所示,因为“Bear”一词出现了两次,所以经过Shuffle过程后,“Bear”所对应的List为(1,1)。
最后,Reduce函数运行,将Shuffle过程所生成的List求和,完成对某一词出现的次数统计。
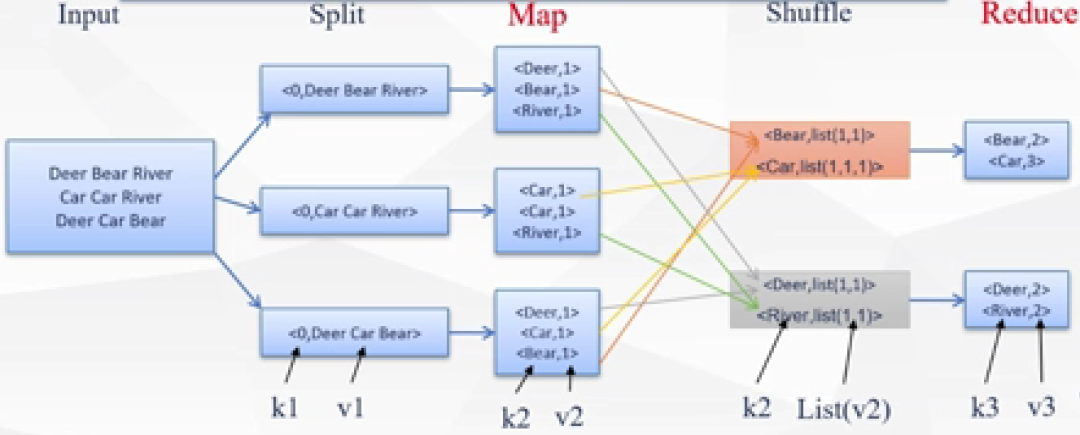
图一,图片来源:学堂在线《大数据导论》
审核编辑:刘清
-
数据存储
+关注
关注
5文章
971浏览量
50909 -
HDFS
+关注
关注
1文章
30浏览量
9597 -
大数据系统
+关注
关注
0文章
7浏览量
1878
原文标题:大数据相关介绍(9)——大数据系统(上)
文章出处:【微信号:行业学习与研究,微信公众号:行业学习与研究】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
缓存对大数据处理的影响分析
ADS1675最大数据吞吐率是是多少?
raid 在大数据分析中的应用
智慧城市与大数据的关系
基于Kepware的Hadoop大数据应用构建-提升数据价值利用效能
使用CYW20829的BLE进行最大数据发送应用,BLE丢失数据如何解决?
大数据在军事方面的应用
多通道数据采集系统的工作原理包括什么
大数据分析平台网站
大数据在军事方面的应用有哪些
CYBT-343026传输大数据时会丢数据的原因?
简析大数据技术下智能充电桩在网络系统中的应用





 工商网监
工商网监
评论