 ChatGPT的技术体系
ChatGPT的技术体系
ChatGPT的技术体系
0.参考资料
RLHF论文:Training language models to follow instructions with human feedback(https://arxiv.org/pdf/2203.02155.pdf)
摘要上下文中的 RLHF:Learning to summarize from Human Feedback (https://arxiv.org/pdf/2009.01325.pdf)
PPO论文:Proximal Policy Optimization Algorithms(https://arxiv.org/pdf/1707.06347.pdf)
Deep reinforcement learning from human preferences (https://arxiv.org/abs/1706.03741)
1. 引言
1.1 ChatGPT的介绍
作为一个 AI Chatbot,ChatGPT 是当前比较强大的自然语言处理模型之一,它基于 Google 的 T5 模型进行了改进,同时加入了许多自然语言处理的技术,使得它可以与人类进行自然的、连贯的对话。ChatGPT 使用了 GPT(Generative Pre-training Transformer)架构,它是一种基于 Transformer 的预训练语言模型。GPT 的主要思想是将大量的语料库输入到模型中进行训练,使得模型能够理解和学习语言的语法、语义等信息,从而生成自然、连贯的文本。与其他 Chatbot 相比,ChatGPT 的优势在于它可以进行上下文感知型的对话,即它可以记住上下文信息,而不是简单地匹配预先定义的规则或模式。此外,ChatGPT 还可以对文本进行生成和理解,支持多种对话场景和话题,包括闲聊、知识问答、天气查询、新闻阅读等等。
尽管 ChatGPT 在自然语言处理领域已经取得了很好的表现,但它仍然存在一些局限性,例如对于一些复杂的、领域特定的问题,它可能无法给出正确的答案,需要通过人类干预来解决。因此,在使用 ChatGPT 进行对话时,我们仍需要谨慎对待,尽可能提供明确、简洁、准确的问题,以获得更好的对话体验。
1.2 ChatGPT的训练模式
ChatGPT 的训练模式是基于大规模文本数据集的监督学习和自我监督学习,这些数据集包括了各种类型的文本,例如新闻文章、博客、社交媒体、百科全书、小说等等。ChatGPT 通过这些数据集进行预训练,然后在特定任务的数据集上进行微调。
对于 Reinforcement Learning from Human Feedback 的训练方式,ChatGPT 通过与人类进行对话来进行模型训练。具体而言,它通过与人类进行对话,从而了解人类对话的语法、语义和上下文等方面的信息,并从中学习如何生成自然、连贯的文本。当 ChatGPT 生成回复时,人类可以对其进行反馈,例如“好的”、“不太好”等等,这些反馈将被用来调整模型参数,以提高 ChatGPT 的回复质量。Reinforcement Learning from Human Feedback 的训练方式,可以使 ChatGPT 更加智能,更好地模拟人类的思维方式。不过这种训练方式也存在一些问题,例如人类反馈的主观性和不确定性等,这些问题可能会影响模型的训练效果。因此,我们需要在使用 ChatGPT 进行对话时,谨慎对待反馈,尽可能提供明确、简洁、准确的反馈,以获得更好的对话体验。
1.3 RLHF的介绍
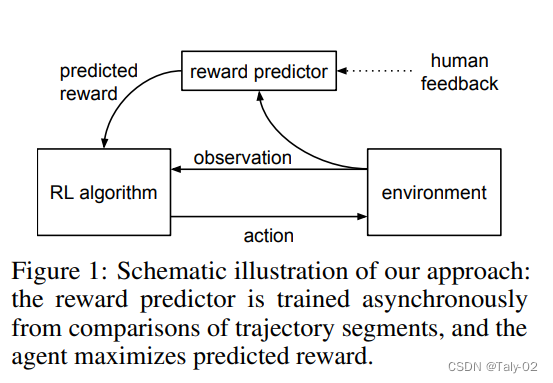
在过去的几年中,语言模型通过根据人类输入提示生成多样化且引人注目的文本显示出令人印象深刻的能力。然而,什么才是“好”文本本质上很难定义,因为它是主观的并且依赖于上下文。有许多应用程序,例如编写您需要创意的故事、应该真实的信息性文本片段,或者我们希望可执行的代码片段。编写一个损失函数来捕获这些属性似乎很棘手,而且大多数语言模型仍然使用简单的下一个loss function(例如交叉熵)进行训练。为了弥补损失本身的缺点,人们定义了旨在更好地捕捉人类偏好的指标,例如 BLEU 或 ROUGE。虽然比损失函数本身更适合衡量性能,但这些指标只是简单地将生成的文本与具有简单规则的引用进行比较,因此也有局限性。如果我们使用生成文本的人工反馈作为性能衡量标准,或者更进一步并使用该反馈作为损失来优化模型,那不是很好吗?这就是从人类反馈中强化学习(RLHF)的想法;使用强化学习的方法直接优化带有人类反馈的语言模型。RLHF 使语言模型能够开始将在一般文本数据语料库上训练的模型与复杂人类价值观的模型对齐。
在传统的强化学习中,智能的agent需要通过不断的试错来学习如何最大化奖励函数。但是,这种方法往往需要大量的训练时间和数据,同时也很难确保智能代理所学习到的策略是符合人类期望的。Deep Reinforcement Learning from Human Preferences 则采用了一种不同的方法,即通过人类偏好来指导智能代理的训练。具体而言,它要求人类评估一系列不同策略的优劣,然后将这些评估结果作为训练数据来训练智能代理的深度神经网络。这样,智能代理就可以在人类偏好的指导下,学习到更符合人类期望的策略。除了减少训练时间和提高智能代理的性能之外,Deep Reinforcement Learning from Human Preferences 还可以在许多现实场景中发挥作用,例如游戏设计、自动驾驶等。通过使用人类偏好来指导智能代理的训练,我们可以更好地满足人类需求,并创造出更加智能和人性化的技术应用
2. 方法介绍
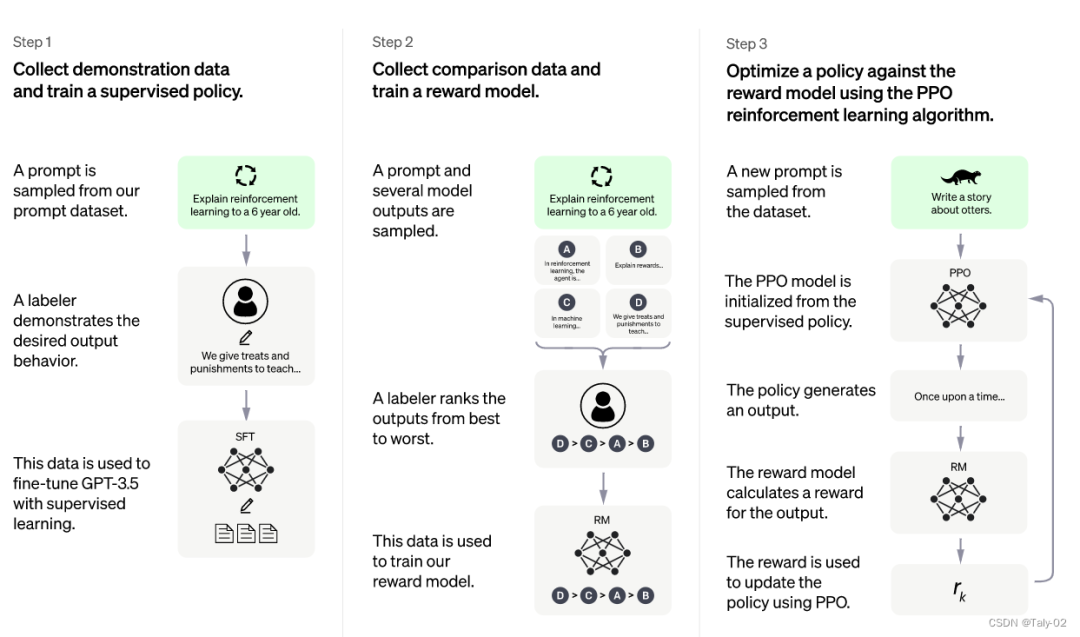
方法总体上包括三个不同步骤:
监督调优模型:在一小部分已经标注好的数据上进行有监督的调优,让机器学习从一个给定的提示列表中生成输出,这个模型被称为 SFT 模型。
模拟人类偏好,让标注者们对大量 SFT 模型输出进行投票,这样就可以得到一个由比较数据组成的新数据集。然后用这个新数据集来训练一个新模型,叫做 RM 模型。
用 RM 模型进一步调优和改进 SFT 模型,用一种叫做 PPO 的方法得到新的策略模式。
第一步只需要进行一次,而第二步和第三步可以持续重复进行,以收集更多的比较数据来训练新的 RM 模型和更新策略模式。
2.1 监督调优模型
需要收集数据来训练有监督的策略模型。为了做到这一点,选定一些提示,让标注人员写出预期的回复。这个过程虽然缓慢和昂贵,但最终得到的是一个相对较小、高质量的数据集,可用于调优预训练的语言模型。选择了 GPT-3.5 系列中的预训练模型作为基线模型,而不是对原始 GPT-3 模型进行调优。
然而,由于此步骤的数据量有限,这个过程得到的 SFT 模型可能会输出一些不是用户想要的文本,通常也会出现不一致问题。为了解决这个问题,使用的策略是让标注者对 SFT 模型的不同输出进行排序以创建 RM 模型,而不是让标注者创建一个更大的精选数据集。
2.2 训练回报模型
在这一步中,我们的目标是学习一个目标函数,它可以直接从数据中学习,而不是仅仅从有限的训练数据中调整语言模型。这个目标函数的作用是为 SFT 模型生成的输出进行评分,以表示这些输出对人类来说有多可接受。它反映了人类标注者的偏好和共同准则。最终,这个过程可以得到一个系统,它可以模仿人类的偏好。包括以下步骤:
利用prompt 生成多个输出。
利用标注者对这些输出进行排序,获得一个更大质量更高的数据集。
把模型将 SFT 模型输出作为输入,并按优先顺序对它们进行排序。
2.3 使用 PPO 模型微调 SFT 模型
这一步的目标是通过强化学习来调整 SFT 模型。具体来说,使用了一个叫 PPO 的算法来训练一个叫做近端策略优化模型的调整模型,用于优化 SFT 模型。
PPO 是一种用于训练智能体的算法,可以不断地调整策略以提高效果。与其他算法不同的是,PPO 会限制策略的更改范围,以确保训练的稳定性。此外,PPO 还使用了一个价值函数来估计每个行动的价值,从而更加准确地进行调整。
在这一步中,PPO 模型使用 SFT 模型作为起点,RM 模型作为基础,为给定的输入生成回报。为了避免过度优化,SFT 模型会为每个 token 添加 KL 惩罚因子。
3. 性能评估
作为一个大型语言模型,ChatGPT的评估标准可以有多种。在训练ChatGPT时,通常会使用一些标准的自然语言处理评估指标来评估其性能,如困惑度(perplexity)、BLEU分数、ROUGE分数等。这些指标可以用来评估ChatGPT在生成文本时的流畅度、语义连贯性和表达能力等方面的表现。此外,ChatGPT也可以通过人类评估来评估其性能,例如进行用户调查或人类评分实验。这些方法可以提供更贴近实际使用场景的评估,以便更全面地评估ChatGPT在生成自然语言文本方面的表现。
主要借助以下三个标准进行评估:
帮助性:判断模型遵循用户指示以及推断指示的能力。
真实性:判断模型在封闭领域任务中有产生虚构事实的倾向。
无害性:标注者评估模型的输出是否适当、是否包含歧视性内容。
4. ChatGPT的前景
ChatGPT 在自然语言处理领域具有广泛的应用前景。它可以用于语言翻译、情感分析、问答系统、文本摘要、对话系统等多个任务,帮助人们更好地理解和处理自然语言。此外,ChatGPT 还可以应用于许多其他领域,例如自然语言生成、自动文本摘要、机器翻译、自动问答、语音识别等。它也可以用于推荐系统、智能客服、智能问答、知识图谱等领域。ChatGPT 的未来发展前景非常广阔,可以预见的是,随着技术的不断发展,它将在各个领域得到更广泛的应用和改进。同时,也需要关注和解决一些挑战,例如如何提高模型的效率和准确性,如何解决对话中的常识推理和知识不足等问题。
审核编辑 :李倩
-
模型
+关注
关注
1文章
3440浏览量
49630 -
智能体
+关注
关注
1文章
211浏览量
10814 -
ChatGPT
+关注
关注
29文章
1580浏览量
8443
原文标题:ChatGPT的技术体系
文章出处:【微信号:GiantPandaCV,微信公众号:GiantPandaCV】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
【国产FPGA+OMAPL138开发板体验】(原创)6.FPGA连接ChatGPT 4
在FPGA设计中是否可以应用ChatGPT生成想要的程序呢
OpenAI 深夜抛出王炸 “ChatGPT- 4o”, “她” 来了

科技大厂竞逐AIGC,中国的ChatGPT在哪?
chatGPT一种生产力的变革
不到1分钟开发一个GPT应用!各路大神疯狂整活,网友:ChatGPT就是新iPhone
ChatGPT实现原理





 工商网监
工商网监
评论