 聊聊SystemVerilog编码层面提速的若干策略
聊聊SystemVerilog编码层面提速的若干策略
今天别的先不聊,就单从代码习惯出发聊聊SystemVerilog编码层面提速的若干策略。
本篇的主体策略来自Cliff Cummings和其团队多年以来得出的一些研究结论,所展示的策略主要偏重于定性分析,而非定量分析,偏重结论而非详细的理论论述。如果大家感兴趣,可以自己设计仿真实验进一步定量分析,或深入查阅文献资料深究原理。
值得一提的是,本文虽偏重定性分析和结论摆出,但是这些结论还是具有很不错的价值,例如对SystemVerilog仿真速度的编码层面优化方法提供了一些思路和认知,对SystemVerilog代码风格建立提供了一个新的观察视角,当你在代码提速优化“山穷水尽”之时,也许因为某条“柳暗花明”。
好了,废话不说了,请出干货:
1.频繁的函数/任务调用会增加开销
比如:用foreach遍历方式计数(foreach有内置函数),不如单独的计数器!如下代码:
这样写比较慢:

这样写比较快:

对于简单调用,编译器可以将函数/任务内联以避免堆栈帧操作,但复杂调用因为编译器性能考虑原因通常不会内联,每个函数/任务都将数据引用或完整的数据副本推送到调用堆栈,并处理任何指定的返回。如此就会增加仿真时间了。如果这个函数/任务本身又被循环掉用,时间就会浪费更多!
上面的反例代码,通过foreach遍历来统计mad_q中的元素数,每次都需要掉用一次内部的内置函数,将会慢于一个独立的计数器!
2.计算表达式、引用请“逃出”循环
例2.1:循环条件中不要带计算,每次循环都会计算一次
这样写比较慢:

这样写比较快:
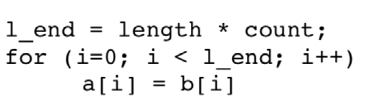
例2.2:和循环因子无关的计算应在循环外计算好
这样写比较慢:
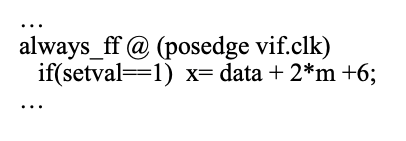
这样写比较快:
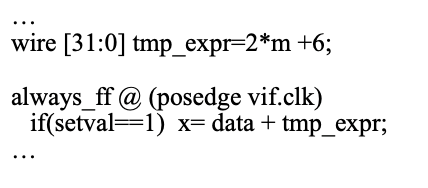
例2.3:引用不要和循环沾边
这样写比较慢:

这样写比较快:

这个例子比较慢的代码把例如comms.proto.pkt….的引用带入了循环里。
在硬件世界中,可以预先计算分层引用,因为这些引用在运行时是静态的。在systemverilog testbench中,引用通常是同时遍历类实例层次结构和动态类型,所有这些都可以在仿真运行期间更改。因此,模拟器必须遍历所有引用才能获得数据,这显然会降低速度。
3.对于条件的相关编码长点儿心吧
例3.1:简单的条件短路

第一行if中通过“或”联系起来的条件,当其中term1为1时,则后续不用判断则可以得出if条件整体成立。
同理第二行if中通过“与”联系起来的条件,当其中term1为0时,则后续不用判断则可以得出if条件整体不成立。
所以这样写这个条件会比较快,例如:
if(最高频率的条件 || 次高频率的条件 || 最低频率的条件),把最高频率的写在最前面。
例3.2:能条件成立后才进行计算的,就不要着急放到前面算。
比如下面这个例子,data的计算是调用了randomize()这个函数,但是用这个值是在一个If(live==TRUE)条件成立之后才用的!假如条件没成立,那就是没用上,没用上前面是不白算了?自然就浪费资源了!(我们前面讲循环的时候说该算的提前算好,看到条件这里的时候我们可能要多想想了,原来不是啥都赶前面算就好啊,哈哈)

例3.3:UVM平台中妙用uvm_report_enabled()函数作为条件来优化。
如下例,如果打印详细级别设置为UVM_DEBUG或高于UVM_DEBUG,则触发消息打印。

例3.4:再来一个UVM平台中玩好条件的案例,monitor或者driver进行port传递时,以port的size()为条件,减少不必要的打数据包的次数。

4.连接处logic的语义显式声明wire,可以折叠为同一对象,加快仿真速度(RTL or TB)
这样写比较慢:

这样写比较快:

SystemVerilog中的logic类型,它可以有wire线存储或var变量存储,如果没有显式声明,则存储类型由仿真器根据上下文确定。
别小看这个类型,对仿真差别很大哦,如果是wire型,仿真器可以折叠为同一对象以获得更高的仿真速度,但是变量却不能!
因为logic类型的语义除了在input、inout之外的所有情况下全都默认为变量存储!所以你的代码有时候可能仿真正确,但不知道为啥比想象中的慢!
如上例子中A2.y、A2.X1.y和A2.X1.T1.y是不同的,粗体wire声明允许将它们折叠为单个对象。(当然上例子中input本身默认为wire类型不需要显式声明,但是全部显式声明更加清楚,这个代码风格更好)
5. 在“向量”上直接操作比操作bit更快
这样写比较慢:

这样写比较快:
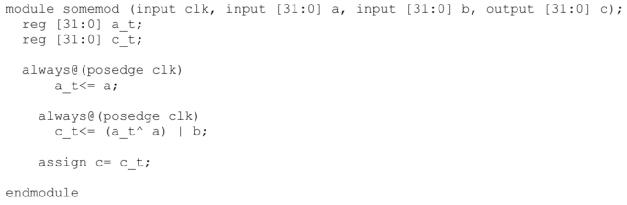
如上例32bit的a_t、c_t,可以看作32个1bit的变量组成的“向量”。对于这个“向量”直接操作会快于对其32个1bit循环操作。
顺便一提,上面的反例中,除了位操作,而且效率低下的示例使用了一个generate语句,它创建了一个静态层次结构。这样的跨层次结构的问题,仿真器会进行优化,但是对于复杂的问题,往往不能做到很好的优化,会变成隐藏的性能问题。
6.尽量用ref,少传递复杂数据结构
ref会直接对目标方法的内存进行操作,这样便节省了资源,尤其是对于很多复杂数据结构例如具有数百个字段的结构体、或具有数百个元素的队列、动态数组、联合数组等。其实,很多时候函数只需要拥有读取大型数据对象的访问权限即可,根本不会写入它。
7.动态数据结构,不要滥用、想清楚再用
“动态数据结构”如队列、动态数组、联合数组是常见性能问题的来源,不要滥用。SystemVerilog和大多数具有这些类型的语言通常都是如此。
所以,尽可能使用静态数组而不是动态数组。即使数组长度有少量变化,最好指定静态数组稍大一些,而不是承担动态数组的开销(内存占用空间和垃圾收集时间)。比如可能有2--10个int型的元素,直接定义和使用“int A[10];”,或者更大点“int A[12];”来存储元素,而不是直接定义使用动态数组“int A[ ];”来动态分配空间。
除此之外,动态数组和队列有各自适合的场景,他们都可以完成对方的功能,但是不要随意混用,否则都会有不好的性能。动态数组最适合查找,随机插入/删除操作,队列最适合自动调整大小的前后操作,仿真器具有不同的内部表示来优化他们各自的操作,所以尽量让他们去合适自己的“岗位”。
8.能用单个对象,不要多new
比较慢的写法:

比较快的写法:

低效的内存可能导致严重的cache miss,堆管理开销和垃圾收集开销,这些都可能难以通过分析发现,所以养成好的代码习惯,例如尽量少new不必要的对象、不是必需情况下尽量少深拷贝动态对象。
9.可以考虑静态类代替动态类
接着上一条,如果同一组类反复被分配内存和释放内存,仿真器通过内存管理反复循环,降低了仿真时间,而如果是静态定义的类,仿真的整体内存占用保持一致,从而执行速度会变快!
10.简单异构数据结构能用结构体就不要用类
很多人常常有种想法认为class是基于面向对象引入的更“高级”的封装方式,结构体好像更“low”一点,其实不然!单独的类将需要堆管理并可能涉及垃圾收集,简单的struct(结构体)不会,所以更快。简单异构数据结构能用结构体就不要用类了吧。
11.接口中的“重”功能放在接口中而不是类中
这样写比较慢:
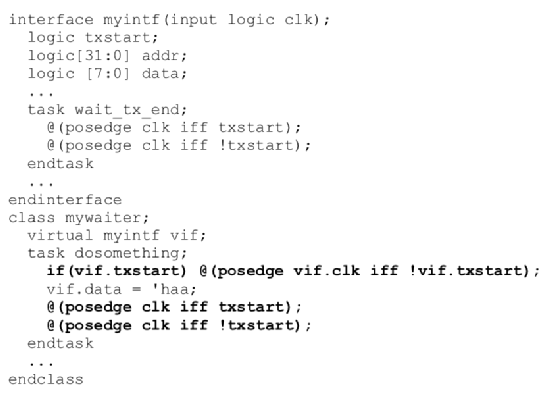
这样写比较快:

将接口“重”的功能放入接口而不是类中也更具仿真效率。
首先,因为功能与接口本身相关联,可重用性更好。
其次,在接口上操作的类包含与接口相关联的基本操作使接口的任何未来用户都可以复制此基本代码,但是通过virtual接口无法有效地引用它们。
12.减少动态task或者function的唤醒
SystemVerilog仿真器是由事件驱动的,它们在给定时间点运行的事件越多,运行速度越慢。SystemVerilog中最常见的进程应该就是带有敏感信号(如clk)的always块来,正因如此常见,这个静态进程在所有仿真器中都进行了高度优化,但是,动态task或者function(如DPI(或任何外部)功能,虚拟类任务/功能和虚拟接口任务/功能)的副作用可能会导致仿真器禁用优化!这种情况,“坐着不如躺着”少唤醒最安全。就像前面例3.2条件的处理那样,尽量减少他们的执行,如下

值得一提的是,除了这样还有一种玩法可以减少执行次数:用iff,如下例子

13.对于UVM平台中带约束的随机,尽量分解或简化
这样写比较慢:
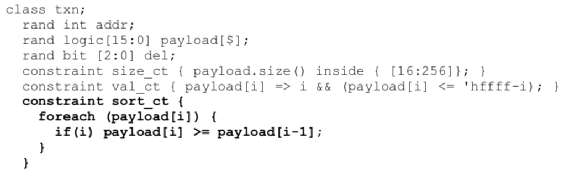
这样写会快很多:

在上图反例中,循环中对其相邻对每个数组元素设置约束,假设100个元素,就相当于必须同时求解100个约束。下面的代码使用post_randomize,经统计,可以将运行时性能提高1000倍!
14.断言的序列和属性尽量避免使用局部变量
这样写比较慢:

这样写比较快:

虽然可能需要局部变量来操纵序列和属性内部的数据,但它们在仿真过程中增加了开销。在可能的情况下,应避免使用局部变量。
15.覆盖率收集时,尽可能减少采样事件
这样写比较慢:

这样写比较快:

上面第二段代码之所以比第一段快,是因为合并使用了相同事件的采样过程,更少的coverage采样事件可以减少仿真时间。
所以除此之外,尽量使用特定事件触发器而不是诸如系统时钟之类的通用事件来采样覆盖率、覆盖组共享共同表达式等手段也可以减少仿真时间。
16. 可以使用宏加快循环计算
对于如下循环代码,reverse()函数会在大量的数据点被掉用,每次调用reverse( ) 都需要创建可能影响缓存命中的堆栈帧,仿真速度会非常慢。使用REVERSE宏,就会使仿真更快。当然宏过度使用会增加调试难度和内存消耗。

结语
正如前文所说:“专辑发文顺序与提速收益无关”,本篇的提效手段,对于代码规模不大的验证业务,说实话并不是收益最大的提速方式,甚至有的收益难以感知,属于“勒紧裤腰带”的致富方式。但是“粒粒皆辛苦”,多条并用,积少成多,当验证业务规模大的时候(除了芯片规模大之外还包括仿真数据量很大时,例如大数据量图像视频的压测场景)你将获得一个还不错的速度收益。
审核编辑:刘清
-
Verilog
+关注
关注
28文章
1351浏览量
110068 -
计数器
+关注
关注
32文章
2255浏览量
94472 -
编译器
+关注
关注
1文章
1623浏览量
49104 -
模拟器
+关注
关注
2文章
874浏览量
43205
原文标题:验证仿真提速系列--SystemVerilog编码层面提速的若干策略
文章出处:【微信号:处芯积律,微信公众号:处芯积律】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
从可综合的RTL代码的角度聊聊interface
[启芯公开课] SystemVerilog for Verification
round robin 的 systemverilog 代码
做FPGA工程师需要掌握SystemVerilog吗?
(2)打两拍systemverilog与VHDL编码 精选资料分享
SystemVerilog Assertion Handbo
SystemVerilog的断言手册
基于OFDM和循环延迟分集的空时频编码策略
基于双向MIMO中继系统的一种预编码策略





 工商网监
工商网监
评论