 基于CPU性能调优的必要性和方法
基于CPU性能调优的必要性和方法
今天的东西可能会比较轻松哈,不会特别不会特别细。给大家讲一下,因为现在硬件按理论来说硬件会越来越好,为什么还要去做这么深的投入和这么多精力去做代码性能调优。然后再举一个例子,怎么去做性能分析?基于 Top-down 性能分析,以及怎么优化它?
02 背景:世界日益数据化,数据处理的性能要求愈加强烈
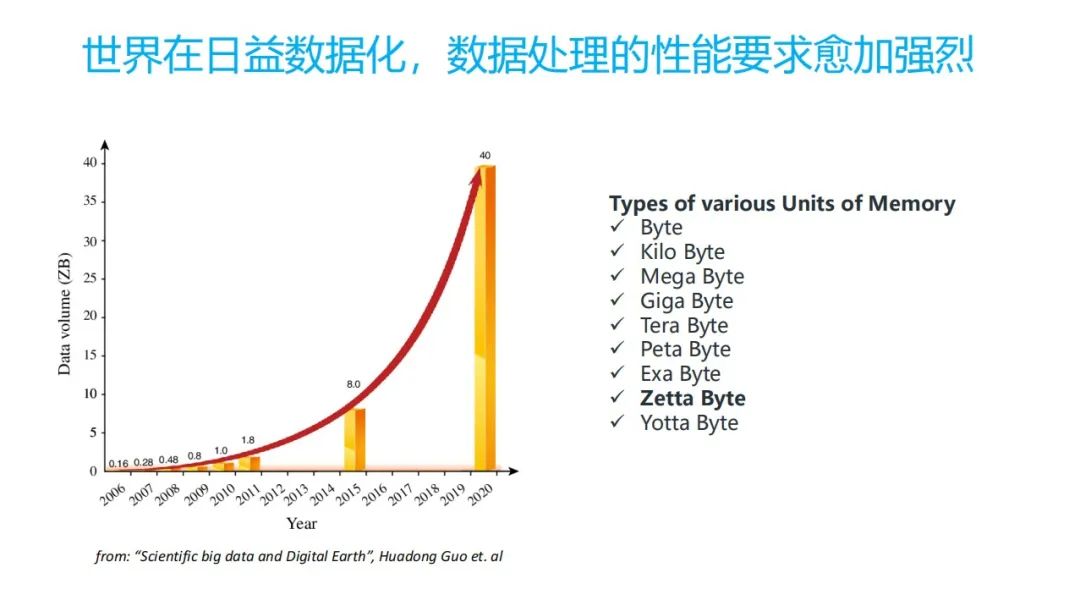
首先看,现在整个世界基本上是以数据为中心,数据越来越多,对数据处理的性能要求会越来越强烈。从现在可以看到,整个咱们整个全世界出现的数据大概是从 2020 年已经到了 40CB 。因为它是指数性的增长,今年肯定还会更多。
03 背景:处理器单线程处理性能增长进入瓶颈期
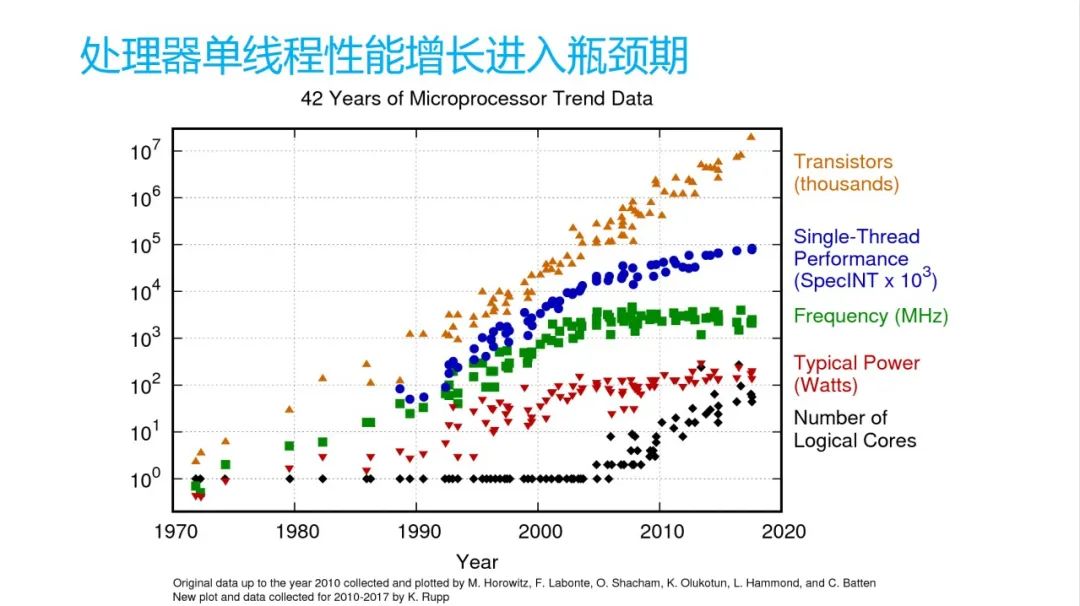
从硬件上,摩尔定律其实已经进到一个尾声阶段了。大家可以看到图上这一块是晶体管的数量是在慢慢增加的。频率可以看到大家基本上也是慢慢的进入一个持平的状态。比如现在手机上高通可能每年提就挤牙膏似的,跟 Intel 一样挤牙膏挤一点点。功耗它可能现在可能在手机上,功耗会越来越高,手机现在越来越发烫。
但是最关键是单线程性能,我可能核会越来越多,但是单线程性能并没有太增加。我可能会通过手机是小核,中核,大核这样一个策略来给它性能提升,但是对单核来说,它性能并没有特别明显的提升,这是它的一个背景。
04 趋势:未来计算性能优化的三个维度

这个人叫 John Hennessy,他是哈佛大学的前校长,现在应该和 alphabet (谷歌母公司) 的董事长。他当时做了一个演讲,计算的未来是什么样。他说对于通用的计算,其实现在来说已经 "is dead" ,已经死了。
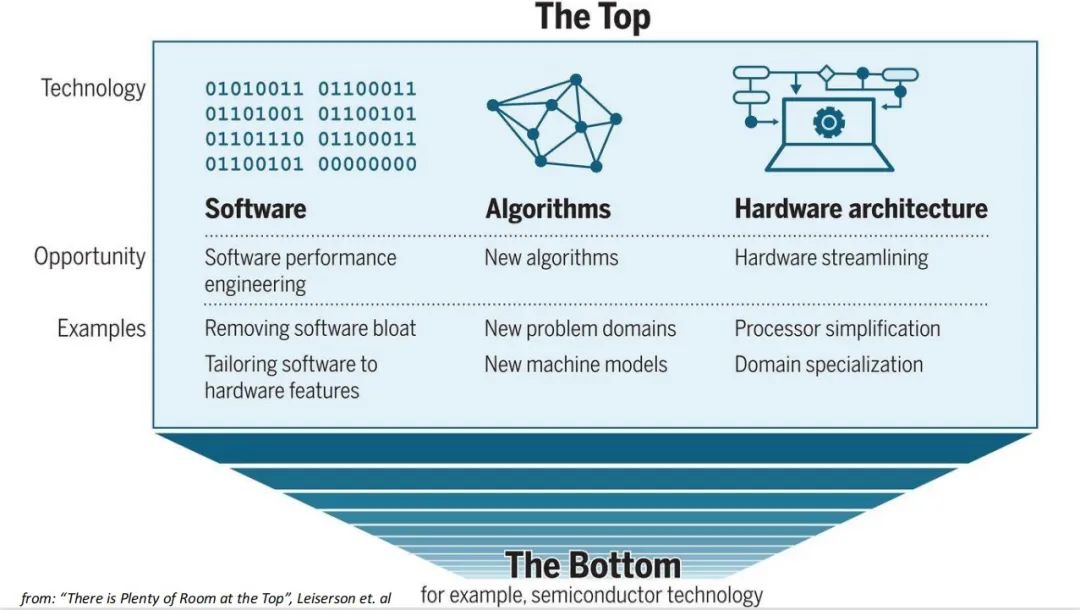
接下来应该是什么样子?下一对这篇论文就是,应该是 20 年的一篇论文。他讲将来我计算的一个提升有三个维度,第一个维度就是软件,第二个维度就是算法,第三个维度就是硬件。
我先讲讲硬件,针对硬件的一个精简,或者硬件的专业化,比如处理器更精简,或者基于一个特定的算法,比如 GPU 或者 DSP 的硬件加速器。第二个就是新的一个算法,新的一些算法或者一些机器模型来去推算。
今天咱们的或者这本书,它能解决的问题是什么?可能是通过把我们的软件工程,软件性能工程领域,它里边有两个点。一个就是把软件更精简,再一个就是把软件裁剪的更适合于硬件特性。今天其实这篇这本书里面讲的更多的是这块(软件裁剪),他并没有说我是怎么去改硬件,比如是怎么去设计一个芯片。我怎么基于硬件特征让把相同的程序跑得更好?
在后摩尔时期,让你代码跑得更快,会越来越重要。尤其是把它裁剪的或者调优的,更适合于它所运行的硬件是很关键的。
05 机会在哪里?软件的不同实现对性能表现上的差异
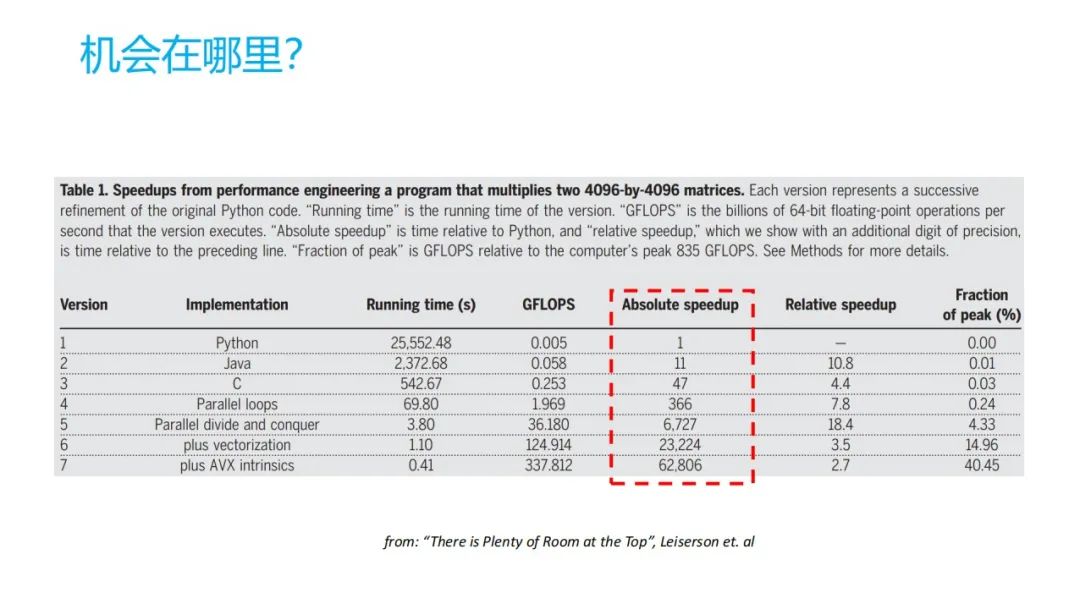
机会在哪里?这个地方它讲了一下,同一个程序我用 Python 去写,用 Java 去写,用 C 去写。普通的写法,它的性能以 Python 为基准,比如 Python 是 1, Java 可能就是11,一 C 就是 47 ,如果是把程序简单做一个强行的并行化是 366,到最终他用硬件本身的一个硬件特性,它有 6万倍(相对于 Python )的增加。这个时间差距还是很大的,如果能把充分的把硬件给利用起来,更充分的去适应具体的芯片,它的能力会提出很多。
06 软件和硬件在性能方面均有能力范围

其实我们一般都想去依赖于硬件的提升,CPU 提升去提升整体的性能。但是 CPU 它其实是一个死的,它并不说你给我随便也给我一个指令,我都能把你运行。不一定的。对编译器来说,比如 GCC/LLVM 它是利用它的成本或者一个成本收益的模型去估算。但是如果他认为你可能有个优化的或者一个转换,它认为他可能风险比较大的,或者会导致他损耗比较高,或什么时候他就不去做了。他会比较保守,可能就达不到默认的优化的预期。
07 现在是做软件优化的黄金时期
所以说现在可能就是最好的一个时机去做软件优化,前段时间也有人提过一个黄金十年就是这样一个意思。如果对 Google 搜索增加 2% 的一个速度,可能它的搜索量就会有 2% 的增加。雅虎之前统计过,如果它一个网页加载时间如果增加四百毫秒,可能使用率可能会降5% 到 9%。
但是整个东西来做,并不是你直接就可以拿到了,需要你深入的去理解你的软件,还有你的硬件怎么去匹配,但是大家有没有做好准备呢?。
08 需要我们怎么做?构建自己的技术栈
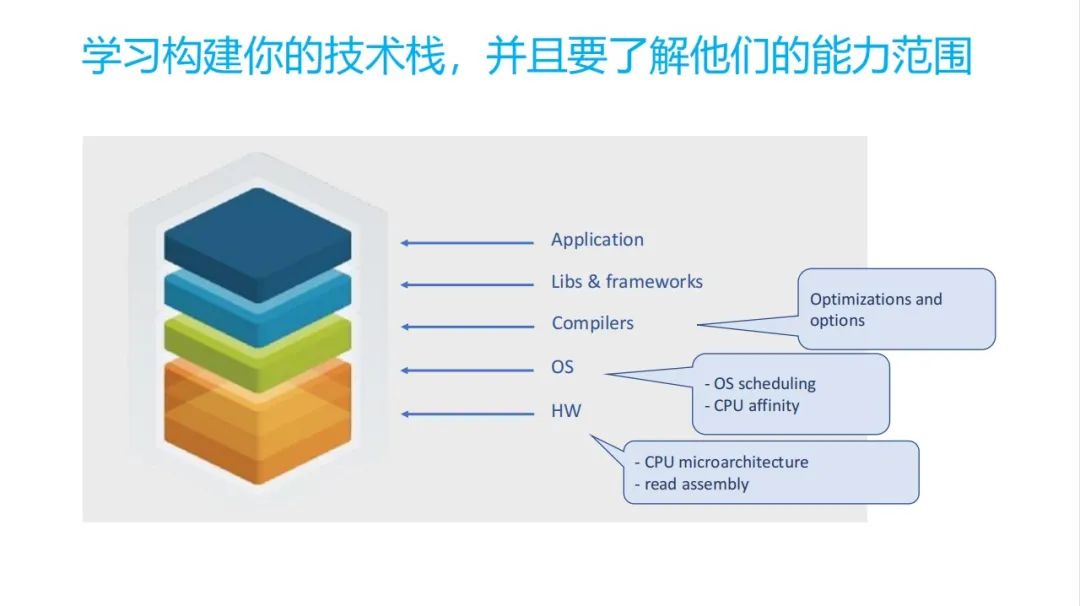
这时候需要我们怎么做?可能我们需要构建自己的技术栈。技术栈有哪些呢?就有这些,跟手机一样,手机应用,还有它框架,编译器,OS,还有硬件。可能对咱们这本书里面涉及到的,主要的是这些。
•第一个就是编译器,你可能不需要更深入理解编译器的具体的原理,但是你要了解编译器通用的编译优化手段,以及它有比较通用的一些编译优化的选项。
•第二个就是 OS 的一个调度,还有一个可能 CPU 绑核。在手机上的话,绑核还是很明显的,如果是在小核上和大核,要是中核,它们也差距很多。硬件的限制。如果你想你的任务要跑特别快,比如假如一个特别重要的前台功能,你需要把你的主线程一个界面相关的线程可能就要绑定到大核上,让他跑这么快。
•第三个在硬点上,我可能我们要比较了解 CPU 的微架构是什么样的, CPU 微架构什么样的,为什么我的代码跑的时候它就慢,慢又拆解为几类,怎么去分析它。第二个你要去可能要去尝试的去学习,怎么去读或者改这些汇编的一些指令。
09 避免性能调优的误区
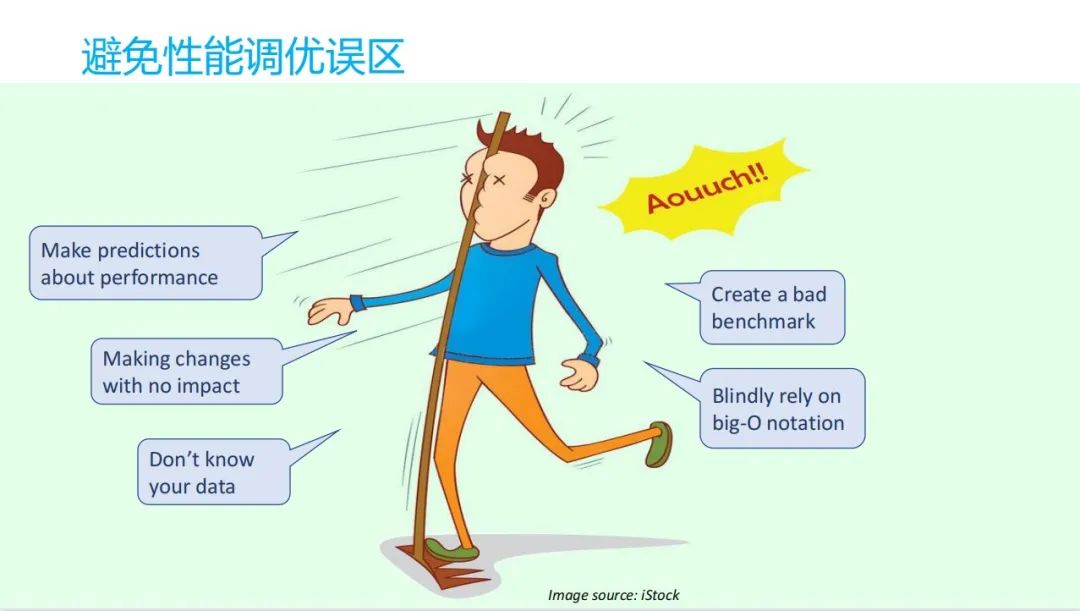
接下来我们在性能调优的时候会有些误区,这些误区可能有这几类。
•第一个就是我看这代码,我自己猜哪个地方可能会有问题,就去改了,结果可能做了一些修改,其实对系统没有任何影响,只是自己在瞎猜。我可能就是猜,但是我并不是知道我具体的数据什么样的,并没有真实去测它,这是很恐怖的。从我们公司内部来看,我们搞问题的肯定是以终为始,一定要是拿到你具体对用户体验相关的一个具体的问题,它是什么样的,拿的数据来,从数据出发。
•第二个,可能你自己造了比较糟糕的一个 benchmark 和基准测试,也是非常糟糕。最好是拿比较开源的,大家共同认可的一个。
•最后一个,因为都是学计算机相关专业的哈,可能大家比较信仰大O的这种算法的复杂度。但是其实在 CPU 上跑的时候,它并不一定说 O 你算法复杂度越低,它跑得越快,这不一定。
10 定位性能问题的方法

这本书其实讲了这几种方法。
•第一个方法扣的这样的一个插桩,写代码打日志,我看到我函数执行特别多,不是前后加日志。
•第二个生成最简单火山图,大家应用也比较多了。
•第三个如果不搞编译器可能大家用的比较少。 compare opt reports 就是编译器的一个优化的报告,你可以打开一个编译开关,你在编译的时候把它报告拿出来。这个地方确实我用过一次,但我们是在用过几次,在我们我们公司一个比较关键的特性里边,他就报告里面,我发现有个地方,他可能有一个函数的内联没有做,没做其实它性能就比较差,我们做完以后性能有百分之将近 10% 的收益。这是很明显的。
•再一个就是 TMA Top-down,也是书上的例子,待会展开。主要是基于 CPU 架构,应该一个英特尔的,一个以色列的专家提出的构想,对性能的分析来说是非常好。
•最后一个是 Roofline 五点线这个模型,CPU 里边性能其实就涉及两类,一个是计算,一个是访存。一个性能与缓存,通过Roofline 线的来判断,我的当前的程序是在哪个地方。还有再一个就是我硬件当前是什么样一个情况,通过这两个信息我就知道程序有没有充分运用硬件的能力,它的访存,它计算都有没有运用全。所以这个地方是可以用来进行反向的去优化我的硬件设计,也可以来指导我的程序里面怎么去改进,以及是访存的类型,我可能就要去优化访存的一个瓶颈,包括计算,我可能要从计算去交流,但这个目前好像没有看到特别好的工具。作者也并没有讲,只是有这样一个方法。我看到香山开源的 RISC-V 的芯片里面,其实他们相关的研究里面应该也用到了这种方法。
11 性能优化的技术点

刚才分析完了,我具体评定以后可能有哪些的优化的方法。
•PGO(Profile GuidedOptimization),其实在手机上,在每个任何一个安卓手机上,它其实都在用。用户用的时候它会产生profile,在虚拟机里面的产生 profile 采集用户用的这些函数的次数,它会都会收集起来。例如,等到晚上手机充电的时候,你如果关注晚上充电的时候就摸一下,可能比较烫,一个原因是充电的烫就可能后台做相关的一些任务,就是要基于 profile 进行函数的一个指导编译,因为它全编可能一个是比较大,再一个可能就比较激进。基于profile 的调用关系,可能更多的可能会把一些函数依赖,或者把一些函数之间的距离可能给它重新排一下,这样它调进的时候,它 attach miss 就会比较小,会好一点。
•Vectorization 是向量化。
•Memory prefetching,后边会讲一个 memory prefetching 的例子。
•Optimize code layout,把你的代码的样子优化一下。
•Function inlining,函数内联其实是用的挺多的,包括安卓它本身其实在虚拟机的修改,它在 AndroidT版本的修改,很多都是把函数进行 inline,再进行优化的。刚才提到我们内部也用了,针对一些个别场景,也会把一些函数,尤其for循环,比如在某一个函数的时候,它都会有调用惯例,这样它会要压栈出栈,这样去还要保存寄存器里的信息,就会很损耗,把它去掉会好很多。
•Optimize memory accesses,在一些内存的访问的时候,比如让它对齐。
•还有一些循环展开,再利用一些技术消除一些分支的预测的信息。
12 实践是检验真理的唯一标准
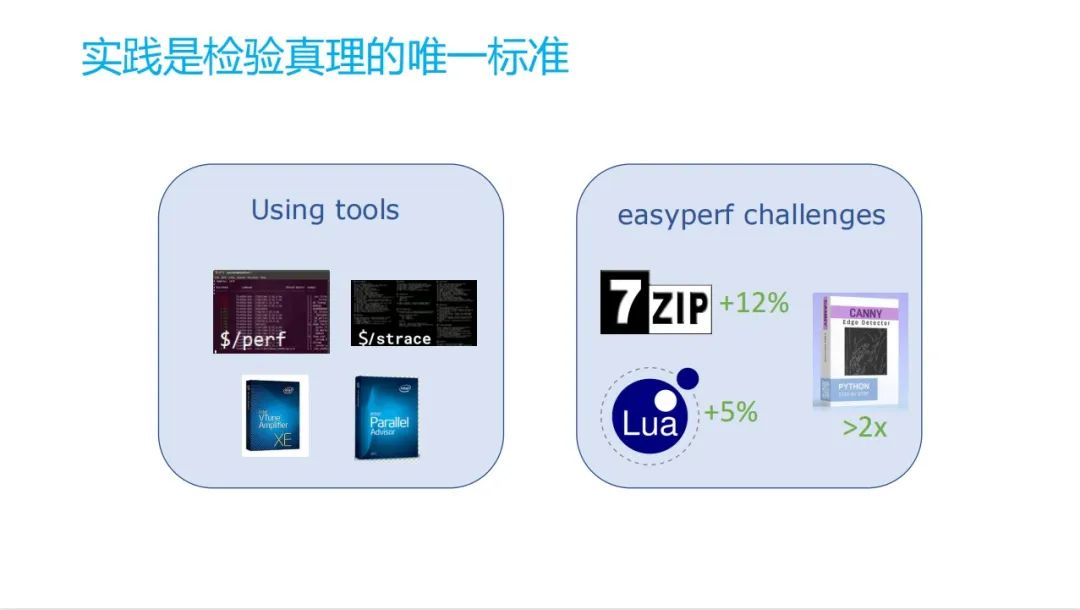
提到了一些方法,在书里面其实提到了一个是 perf。其实这还有一个叫 pmu-tools, Vtune 的一个开源版,Vtune 是一个 Intel 开发的一个工具,专门用于 Intel 的 PMU 架构。 pmu-tools 是开源的一个工具。
再补充一下。今天材料主要就是原作者丹尼斯,他在 21 年对他写的当时做的一个材料,主要是也介绍梳理一些内容。我的要闻把材料稍微改了一下,稍微补充一些信息。
13 Top-down 微体系结构分析方法
这个给大家展示个例子哈。
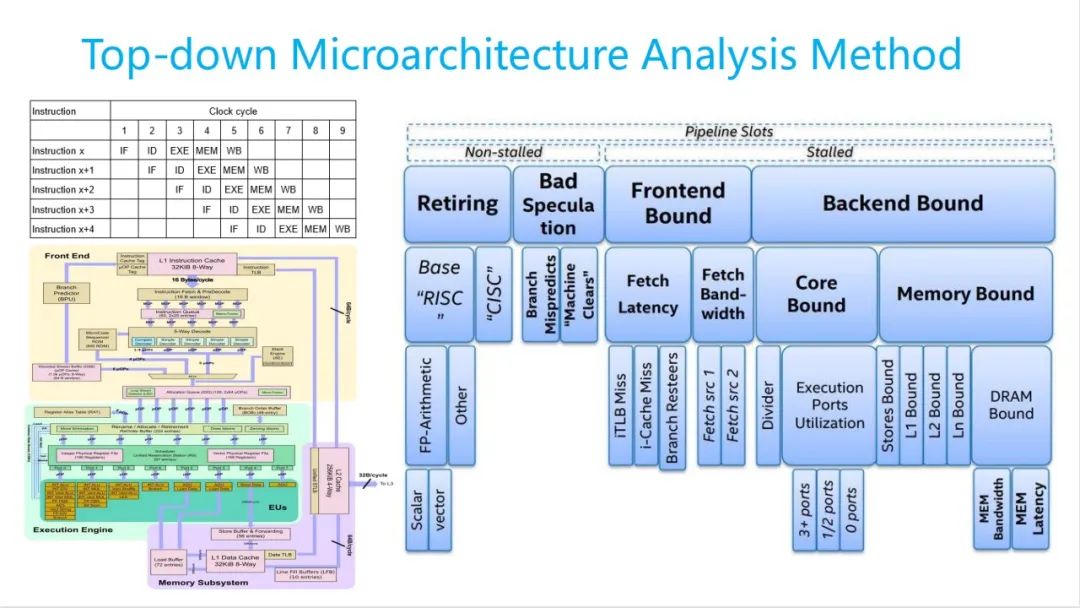
首先我们看一下主要目的,给大家简单的介绍一下什么是 Top-down。首先我先讲一下 CPU 流水线。 CPU 流水线它其实有这几个阶段,一个指令都它执行,是怎么执行?它有一个取指-译指-执行-保存-回写,其中前两个阶段是前端,主要是指令相关的,后三个阶段是后端,主要是访存相关的。如果其中有一个阻塞了,可能会导致空转,它的英文叫bound,比如 front and bound 和 back and bound, front and bound 可能是我取值的时候时间长。取指时间原因可能有多种,下面分这几类。
指令一个是从这里面可能开始取过来,再进行分发,再给decode,再往下是执行后端了。执行的时候他可能不同的单元,我们可能要去不同的port,这个 port 里面给他去执行。前后端是这样串起来的。
到于指令执行的时候,我们可以基于它 store 的在哪个阶段给它进行一个分类。第一层分了 4 类。
•第一个就是 Retiring ,你就退休了,你寿终就寝就行了。指令已经执行到五个阶段,我都已经执行完了。OK,这是最好的一种状态。如果所有的都是这块,基本上相当于就已经自由了。完全利用了CPU 的整个流水线是非常好,但是基本上是不可能的,基本上不可能。
•第二个就是 Bad Speculation,错误的投机。有时候它可能会去提前执行一些指令,比如有个 if-else,我们可能我不知道它是指哪一个,可能要投机去执行了,我先执行,我执行完以后,我先不提交,提交给寄存器处理。这地方会给他进行一个判断,等到你真正的判断执行完了,如果你是对的,OK,我这部分信息我就提交过去,这边就执行完了。如果不对,我觉得你这个特性,我就把它都给它清掉,CPU 就在这里边执行的流水线执行,相当于这段时间这份资源就浪费了,这一部分也会造成一定损失,这个也是希望它小的。
•第三个就是 Frontend Bound,刚提到这个取指的时候可能会慢。
•第四个叫 Backend Bound,一般比较多的。
然后再往下一层。
•Retiring 里面,可能还有一特殊的,到时候看书的可能也会提到,一般浮点可能会有问题。
•Bad Speculation 一般也他们很难去优化它,可能也会有些困难。
•Frontend Bound 主要是两类,取指令它有两种,一个是延迟,一种是带宽。带宽大家可以看到带宽过来,因为带宽特别窄,我可能取特别多。带宽特别窄的时候我可能就取不过来了,取不过来我就等带宽;延迟的话,我可能我取个指令的时候,可能我代码编译的可能特别大,比如他是刚执行的 A ,执行 B 并没有在这里挨着,可能特别远。这时候我可能要去从我的内存或者那地方再把它倒过来,那时候就会遇到 iTLB Miss 或者 i-Cache Miss,这时候就会导致等了时间会比较长。
•Backend Bound 分两类,一个是 Core Bound ,一个是 Memory Bound 。 Core Bound大家简单理解,计算类的,比如我可能我计算特别多,假如加法特别多,或者除法特别多的时候,这时候如果应付不过来,这时候就会产生 Core Bound ,这地方可能会获得时间比较长;最后一个就是 Memory Bound,这可能大家用的会相对可能会多一点。但是 Memory Bound 并不是直接指的内存。里边分好几层,一个是L1/L2/L3 ,还有一个 DRAM Bound ,可能执行过程中我需要读数据,从读数据的时候接着开始读数据,如果在开始, L1 开始有了,OK,那就没问题。最快的 L1 开始没有,随 L2 就会增加一些损耗。最好。如果 L2 没有,随 L3 再增加一些损耗。如果 L3 也没有,那就得去 DRAM 里边去取,时间会更长。在下面的涉及到 memory 这些带宽,更大的 latency 。
OK,这就是 Top-down 的一个拆解。基于拆解以后,你很明确的可以知道你的程序在 CPU 运行的时候,到底依赖是哪个资源。你回过头来,在不能改变硬件情况下,你怎么去改你的程序,把它更好的利用 CPU 的流水线或者它微架构,让它运行更快。
14 TMA分析实例 - 源码

这个实例也比较简单,我 malloc 一块内存,这内存是 200 M 的,每个里面都写个 0。我要干什么?我要写一个这么大的循环,应该是一亿次的一个循环,每个循环我就随机的访问这一刻从 0 到 200M 内存。访问内存,它运行这个时间一般是 8. 5 秒。
怎么去通过用 Top-down 这个方法来进行分析。其实补充一下,在 Linux 上,它英特尔应该都是支持 perf,里面它有个 Top-down 的一个选项,你可以试一下。它可以统计出来一层的我到底是哪种类型的 Bound,这里边用的是 pmu-tools 这个方法。
15 TMA分析实例 - 1和2层分布
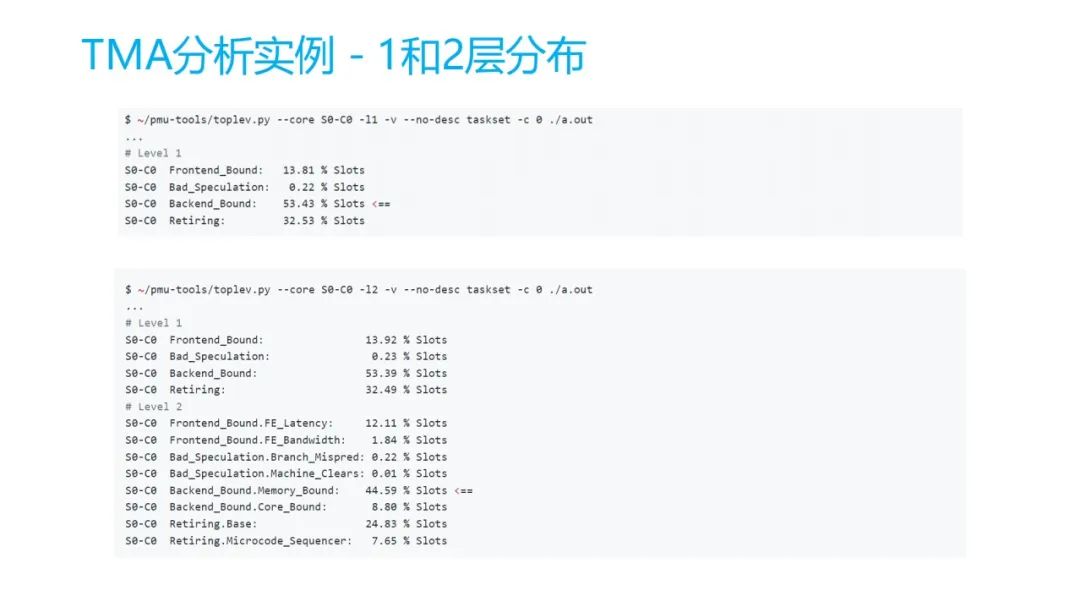
你可以看出来,它程序运行的过程中,它 53% 是在 Backend Bound ,我刚才已经看到 Backend Bound 是在后边的一个。再看第二层,就是 L2 ,在 L2 可以看到,在这里面是 Memory Bound,对 Core Bound 是只有 8.80%,也不多。
16 TMA分析实例 - 3层分布

再看第三个 L3,L3 的 DRAM Bound,图里边右下角 Bound 时间,整个时间是整个占比47%。你可以看到里面每个 cycle 的时间,如 register 基本上一个 cycle 就搞定了,L1 就可能是 8 ~ 32 cycles ,L2 是 300 cycles ,已经到 memory 了。memory 很多,你越低速度越慢时间越长。
17 TMA分析实例 - 通过perf定位到具体函数

然后怎么去定位它?有一个地方有对应关系,这个工具理论是英特尔提出来的。英特尔有一个叫TMA metrics,大家可以在书上可以看到它有对应表格,刚才可以看到它是 DRAM Bound 类型的,它的也需要会给你提供另外一个 L3 miss 的这样一个 PMU 的事件让你去用,你可以去统计 L3 Miss 以后,它就会到 DRAM 那里面去 L3 Miss 事件哪个最多,它通过 perf record 完以后,跟通过他去。可以通过解析审核的 data 文件, prop data 可以看到,这里面主要是复制函数,里面他用到的是 move 的一个缓存的动作,100% 都在这个地方。
18 TMA分析实例 - 通过__buildin_prefetch内存预取优化
怎么去优化它?在 for 循环里边它不是有一个,刚才代码里面可以看到它是随机的去访问它里边的一个地址。
OK,他现在预计他提前能预取出来。它有三个参数,第一个参数就是我预取的它的地址是哪一块,把它预取到 cache 里边来。第二个参数 0 代表是相当于我是读的,第三个参数 1 代表它的程度。第三个参数如果是 0 档基本上我是本地,不是本地的我不取。我认为这块取了以后可能用的不特别多。 1 档代表比较低程度, 2 档代表比较中度的, 3 档代表是高度的。
现在用__buildin_prefetch ,我理解应该是可以缓解 L3 Miss 这一部分。改完以后效果,这个事件原来应该是比原来相对小了 10 倍。大家可以看一下整个运行性能,提升了 2 秒,原来是 8. 5,基本上也是 30% 的加速这样一个模型。
19 性能分析调优建议

最后丹尼斯在他书上也反复提了他的优化建议。最后其实他有很多,挑出来这一部分翻译成中文。大家一起来看一下。
•第一个默认情况下软件,它并不会到达你最优的一个性能,写完代码以后,你认为可能是有,但是它并不一定非常契合你的硬件,可能你需要还要针对硬件做一些针对性的优化。
•刚才也提到,硬件性的自然速度就不如过去几年了,是将来软件性能调优,可能也是提前性能提升性能提升的有关键驱动力。
•再一个就是要构建你的技术栈, CPU微体系结构, v 架构,还有阅读汇编代码,还有操作指令测算系统的一些内核的机制,还有一些编译优化的选项等等。
•再就是避免性能的误区,一定要去通过测量,通过以实时数据的角度来去指导你性能的一个分析,还有优化
•善于使用他们刚才提到的这些工具,进行代码中的一个性能分析,先练习修复他们。
审核编辑:刘清
-
处理器
+关注
关注
68文章
19316浏览量
230081 -
dsp
+关注
关注
553文章
8014浏览量
349179 -
数据处理
+关注
关注
0文章
602浏览量
28584 -
硬件加速器
+关注
关注
0文章
42浏览量
12808
原文标题:朱金鹏:基于CPU性能调优的必要性和方法
文章出处:【微信号:LinuxDev,微信公众号:Linux阅码场】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论