 开源方案低成本复现ChatGPT流程,仅需1.6GB显存即可体验
开源方案低成本复现ChatGPT流程,仅需1.6GB显存即可体验
开源并行训练系统 ColossalAI 表示,已低成本复现了一个 ChatGPT 训练的基本流程,包括 stage 1 预训练、stage 2 的奖励模型的训练,以及最为复杂的 stage 3 强化学习训练。具体亮点包括: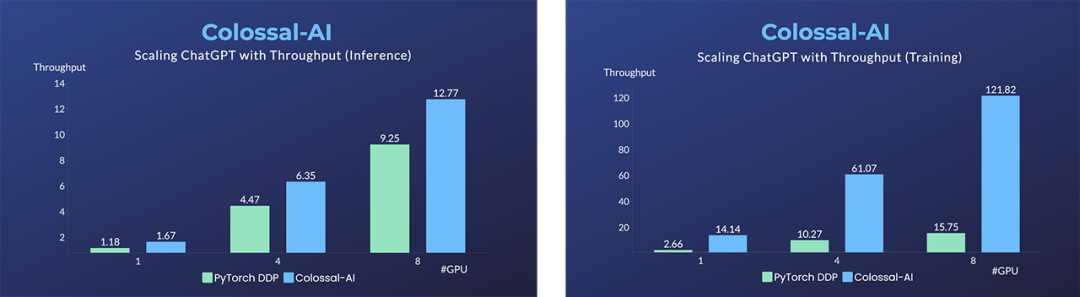 博客内容还指出,在单机多 GPU 服务器上,即便使用最高端的 A100 80GB 显卡,由于 ChatGPT 的复杂性和内存碎片,PyTorch 最大仅能启动基于 GPT-L(774M)这样的小模型的 ChatGPT。用 PyTorch 原生的 DistributedDataParallel (DDP) 进行多卡并行扩展至 4 卡或 8 卡,性能提升有限。Colossal-AI 不仅在单GPU速度上训练和推理优势明显,随着并行规模扩大还可进一步提升,最高可提升单机训练速度 7.73 倍,单 GPU 推理速度 1.42 倍;并且能够继续扩展至大规模并行,显著降低 ChatGPT 复现成本。
博客内容还指出,在单机多 GPU 服务器上,即便使用最高端的 A100 80GB 显卡,由于 ChatGPT 的复杂性和内存碎片,PyTorch 最大仅能启动基于 GPT-L(774M)这样的小模型的 ChatGPT。用 PyTorch 原生的 DistributedDataParallel (DDP) 进行多卡并行扩展至 4 卡或 8 卡,性能提升有限。Colossal-AI 不仅在单GPU速度上训练和推理优势明显,随着并行规模扩大还可进一步提升,最高可提升单机训练速度 7.73 倍,单 GPU 推理速度 1.42 倍;并且能够继续扩展至大规模并行,显著降低 ChatGPT 复现成本。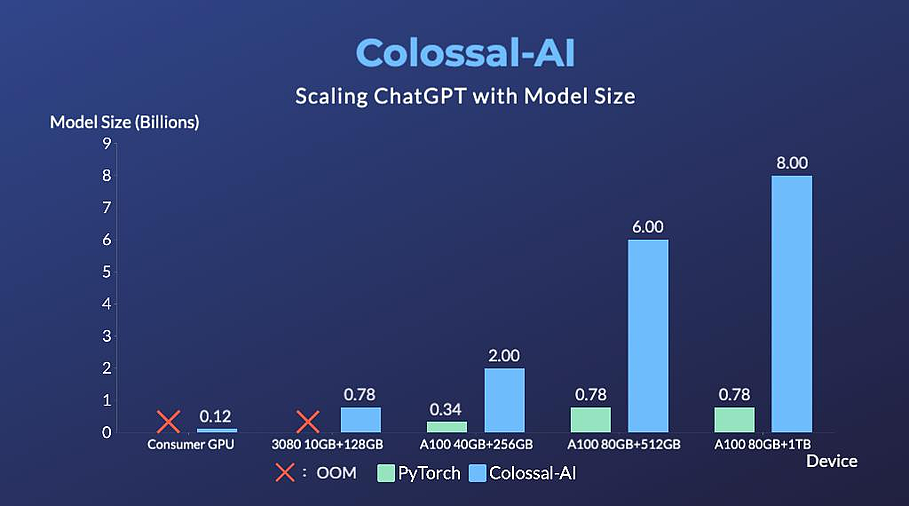 为了最大限度地降低培训成本和易用性,Colossal-AI 提供了可以在单个 GPU 上试用的 ChatGPT 培训流程。与在 14999 美元的 A100 80GB 上最多只能启动 7.8 亿个参数模型的 PyTorch 相比,Colossal-AI 将单个 GPU 的容量提升了 10.3 倍,达到 80 亿个参数。对于基于 1.2 亿参数的小模型的 ChatGPT 训练,至少需要 1.62GB 的 GPU 内存,任意单个消费级 GPU 都可以满足。
为了最大限度地降低培训成本和易用性,Colossal-AI 提供了可以在单个 GPU 上试用的 ChatGPT 培训流程。与在 14999 美元的 A100 80GB 上最多只能启动 7.8 亿个参数模型的 PyTorch 相比,Colossal-AI 将单个 GPU 的容量提升了 10.3 倍,达到 80 亿个参数。对于基于 1.2 亿参数的小模型的 ChatGPT 训练,至少需要 1.62GB 的 GPU 内存,任意单个消费级 GPU 都可以满足。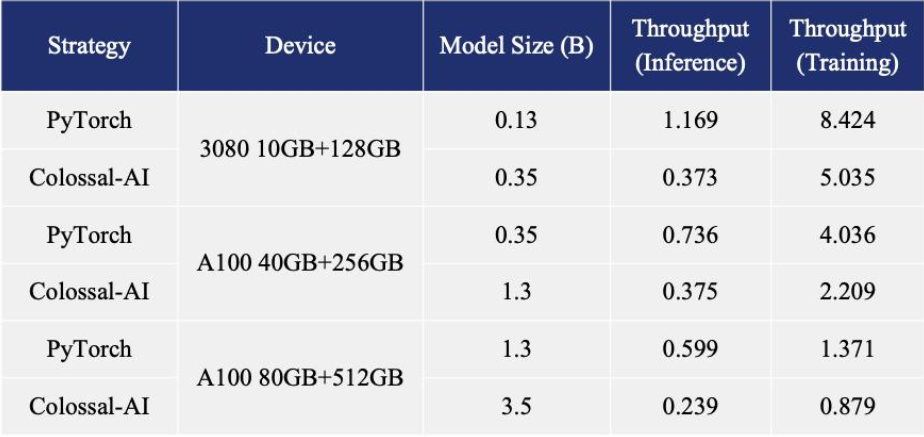 此外,Colossal-AI 还在致力于降低基于预训练大型模型的微调任务的成本。以 ChatGPT 可选的开源基础模型 OPT 为例,Colossal-AI 能够在单 GPU 上将微调模型的容量提高到 PyTorch 的 3.7 倍,同时保持高速运行。Colossal-AI 为 Hugging Face 社区的 GPT、OPT 和 BLOOM 等主流预训练模型,提供了开箱即用的 ChatGPT 复现代码。以 GPT 为例,仅需一行代码,指定使用 Colossal-AI 作为系统策略即可快速使用。
此外,Colossal-AI 还在致力于降低基于预训练大型模型的微调任务的成本。以 ChatGPT 可选的开源基础模型 OPT 为例,Colossal-AI 能够在单 GPU 上将微调模型的容量提高到 PyTorch 的 3.7 倍,同时保持高速运行。Colossal-AI 为 Hugging Face 社区的 GPT、OPT 和 BLOOM 等主流预训练模型,提供了开箱即用的 ChatGPT 复现代码。以 GPT 为例,仅需一行代码,指定使用 Colossal-AI 作为系统策略即可快速使用。
-
一个开源完整的基于 PyTorch 的 ChatGPT 等效实现流程,涵盖所有 3 个阶段,可以帮助你构建基于预训练模型的 ChatGPT 式服务。
-
提供了一个迷你演示训练过程供用户试玩,它只需要 1.62GB 的 GPU 显存,并且可能在单个消费级 GPU 上实现,单GPU模型容量最多提升10.3 倍。
-
与原始 PyTorch 相比,单机训练过程最高可提升7.73 倍,单 GPU 推理速度提升 1.42 倍,仅需一行代码即可调用。
-
在微调任务上,同样仅需一行代码,就可以在保持足够高的运行速度的情况下,最多提升单GPU的微调模型容量3.7 倍。
-
提供多个版本的单 GPU 规模、单节点多 GPU 规模和原始 1750 亿参数规模。还支持从 Hugging Face 导入 OPT、GPT-3、BLOOM 和许多其他预训练的大型模型到你的训练过程中。
博客内容还指出,在单机多 GPU 服务器上,即便使用最高端的 A100 80GB 显卡,由于 ChatGPT 的复杂性和内存碎片,PyTorch 最大仅能启动基于 GPT-L(774M)这样的小模型的 ChatGPT。用 PyTorch 原生的 DistributedDataParallel (DDP) 进行多卡并行扩展至 4 卡或 8 卡,性能提升有限。Colossal-AI 不仅在单GPU速度上训练和推理优势明显,随着并行规模扩大还可进一步提升,最高可提升单机训练速度 7.73 倍,单 GPU 推理速度 1.42 倍;并且能够继续扩展至大规模并行,显著降低 ChatGPT 复现成本。为了最大限度地降低培训成本和易用性,Colossal-AI 提供了可以在单个 GPU 上试用的 ChatGPT 培训流程。与在 14999 美元的 A100 80GB 上最多只能启动 7.8 亿个参数模型的 PyTorch 相比,Colossal-AI 将单个 GPU 的容量提升了 10.3 倍,达到 80 亿个参数。对于基于 1.2 亿参数的小模型的 ChatGPT 训练,至少需要 1.62GB 的 GPU 内存,任意单个消费级 GPU 都可以满足。此外,Colossal-AI 还在致力于降低基于预训练大型模型的微调任务的成本。以 ChatGPT 可选的开源基础模型 OPT 为例,Colossal-AI 能够在单 GPU 上将微调模型的容量提高到 PyTorch 的 3.7 倍,同时保持高速运行。Colossal-AI 为 Hugging Face 社区的 GPT、OPT 和 BLOOM 等主流预训练模型,提供了开箱即用的 ChatGPT 复现代码。以 GPT 为例,仅需一行代码,指定使用 Colossal-AI 作为系统策略即可快速使用。
from chatgpt.nn import GPTActor, GPTCritic, RewardModel
from chatgpt.trainer import PPOTrainer
from chatgpt.trainer.strategies import ColossalAIStrategy
strategy = ColossalAIStrategy(stage=3, placement_policy='cuda')
with strategy.model_init_context():
actor = GPTActor().cuda()
critic = GPTCritic().cuda()
initial_model = deepcopy(actor).cuda()
reward_model = RewardModel(deepcopy(critic.model)).cuda()
trainer = PPOTrainer(strategy, actor, critic, reward_model, initial_model,...)
trainer.fit(prompts)
审核编辑 :李倩
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
gpu
+关注
关注
28文章
4738浏览量
128940 -
服务器
+关注
关注
12文章
9158浏览量
85411 -
ChatGPT
+关注
关注
29文章
1560浏览量
7652
原文标题:开源方案低成本复现ChatGPT流程,仅需1.6GB显存即可体验
文章出处:【微信号:OSC开源社区,微信公众号:OSC开源社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
香蕉派开源社区与矽昌通信共推BPI-Wifi5 低成本路由器开源方案
香蕉派开源社区与矽昌通信共推BPI-Wifi5 低成本路由器[]()
香蕉派 BPI-Wifi5 路由器采用矽昌SF19A2890S2芯片方案设计。它是一款高性能无线路由器,适用于小微企业、家庭
发表于 11-28 10:37
低成本蓝牙串口模块解决方案
传统电子产品生产商对价格比较敏感,进口的蓝牙串口模块对厂商的成本控制有很大的压力。针对此种情况,红果电子推出了完整的低成本蓝牙串口模块解决方案,采用RG-BT10-10低成本蓝牙模块,
发表于 03-21 16:46
追求性能提升 使用8GB HBM2显存
更积极,继Altera之后赛灵思也宣布了集成HBM 2做内存的FPGA新品,而且用了8GB容量。 HBM显存虽然首发于AMD显卡上,不过HBM 2这一代FPGA厂商比GPU厂商更积极 AMD
发表于 12-07 15:54
科技大厂竞逐AIGC,中国的ChatGPT在哪?
迭代,需要大量的数据进行训练。2020年发布的GPT-3,其训练参数量已经达到了惊人的1750亿个,“大量的数据被反复‘喂’给ChatGPT。” 而且,ChatGPT的训练成本支出巨大。据Lambda
发表于 03-03 14:28
坚果Pro 3开启了促销活动最高直降500元8GB+128GB版仅需2399元
为了迎接新年,坚果手机开启新年促销活动。目前购买坚果Pro 3可享直降最高500元的活动,购买8GB+128GB坚果Pro 3仅需2399元;购买8GB+256GB版本
荣耀V30 PRO在5G网络环境下下载一部1.6GB大小的1080P电影仅需2分钟
笔者定位芍药居北里南门,在5G网络环境下,使用荣耀V30 PRO下载一部1.6GB大小的1080P电影。电影从10:23开始下载,10:25完成下载,耗时也仅2分钟,尽管是在室外下载的,但是就实际使用体验而言,这个下载速度已经相当快了。
发表于 01-07 15:30
•2232次阅读
华为Mate 20降价促销 6+128GB版仅需2199元
近日,据网友爆料,拼多多华为Mate 20降价促销,6+128GB到手仅需2199元,比首发价便宜2300元。

源2.0-M32大模型发布量化版 运行显存仅需23GB 性能可媲美LLaMA3
北京2024年8月23日 /美通社/ -- 近日,浪潮信息发布源2.0-M32大模型4bit和8bit量化版,性能比肩700亿参数的LLaMA3开源大模型。4bit量化版推理运行显存仅需





 工商网监
工商网监
评论