|
from keras import layers
from keras import models
from keras.datasets import mnist
from keras.utils import to_categorical
(train_images, train_labels), (test_images, test_labels) = mnist.load_data('D:/Python36/Coding/PycharmProjects/ttt/mnist.npz')
train_images = train_images.reshape(60000, 28*28)
train_images = train_images.astype('float32') / 255
test_images = test_images.reshape(10000, 28*28)
test_images = test_images.astype('float32') / 255
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
model = models.Sequential()
model.add(layers.Dense(512, activation='relu', input_shape=(28 * 28,)))
model.add(layers.Dense(10, activation='softmax'))
model.compile(optimizer='rmsprop',loss='categorical_crossentropy',metrics=['accuracy'])
history=model.fit(train_images, train_labels, epochs=10, batch_size=128)
test_loss, test_acc = model.evaluate(test_images, test_labels)
print(test_acc,test_acc)
#0.9786 0.9786
print("history_dict%s =" %history.history)
#history_dict = {'loss': [0.25715254720052083, 0.1041663886765639, 0.06873120647072792, 0.049757948418458306, 0.037821156319851675, 0.02870141142855088, 0.02186925242592891, 0.01737390520994862, 0.01316443470219771, 0.010196967865650853],
# 'acc': [0.9253666666984558, 0.9694833333333334, 0.9794666666348775, 0.9850166666984558, 0.9886666666666667, 0.9917666666666667, 0.9935499999682108, 0.9949499999682109, 0.9960999999682109, 0.9972833333333333]} =
acc1 = history.history['acc']
loss1 = history.history['loss']
print(model.summary())
(train_images, train_labels), (test_images, test_labels) = mnist.load_data('D:/Python36/Coding/PycharmProjects/ttt/mnist.npz')
train_images = train_images.reshape((60000, 28, 28, 1))
train_images = train_images.astype('float32') / 255
test_images = test_images.reshape((10000, 28, 28, 1))
test_images = test_images.astype('float32') / 255
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
model.compile(optimizer='rmsprop',loss='categorical_crossentropy',metrics=['accuracy'])
history = model.fit(train_images, train_labels, epochs=10, batch_size=64)
test_loss, test_acc = model.evaluate(test_images, test_labels)
##0.9919 0.9919
print("history_dict =%s" %history.history)
#history_dict = {'loss': [0.1729982195024689, 0.04632370648694535, 0.031306330454613396, 0.02327785180026355, 0.01820601755216679, 0.01537780981725761, 0.011968255878429288, 0.010757189085084126, 0.008755202058390447, 0.007045005079609898],
# 'acc': [0.9456333333333333, 0.9859, 0.9903333333333333, 0.9929333333333333, 0.99435, 0.9953333333333333, 0.9962333333333333, 0.9966, 0.99735, 0.9979333333333333]}
acc2 = history.history['acc']
loss2 = history.history['loss']
print(model.summary())
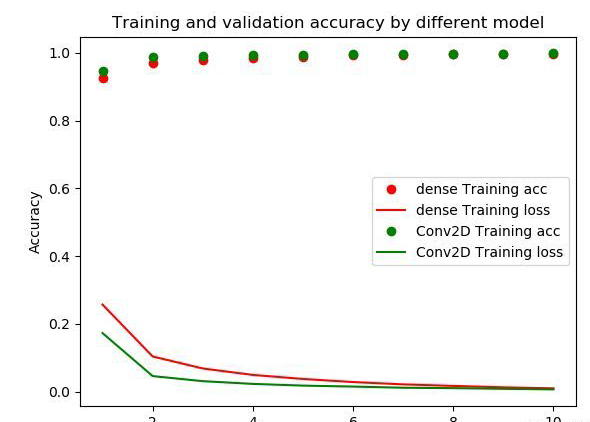
import matplotlib.pyplot as plt
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
epochs = range(1, len(acc1) + 1)
ax.plot(epochs, acc1, 'bo', label='dense Training acc',color='red')
ax.plot(epochs, loss1, 'b', label='dense Training loss',color='red')
ax.plot(epochs, acc2, 'bo', label='Conv2D Training acc',color='green')
ax.plot(epochs, loss2, 'b', label='Conv2D Training loss',color='green')
ax.legend(loc='best')
ax.set_title('Training and validation accuracy by different model')
ax.set_xlabel('Epochs')
ax.set_ylabel('Accuracy')
plt.show()
 |
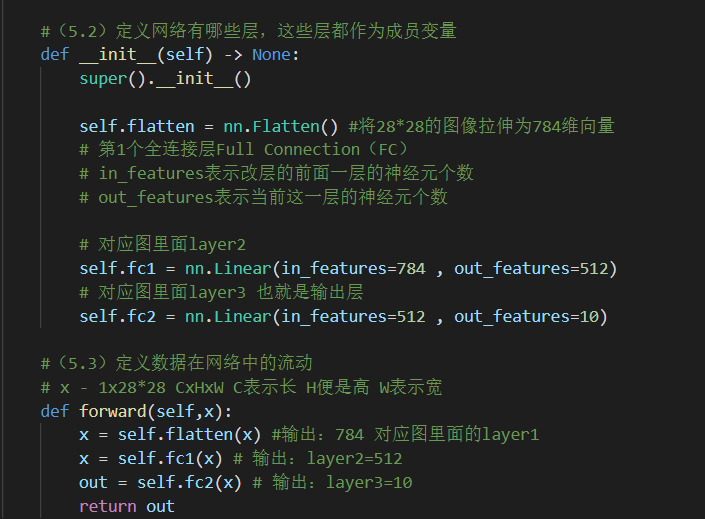
 如何区分卷积网络与全连接网络
如何区分卷积网络与全连接网络






 工商网监
工商网监
评论