 Cadence HPC全系列解决方案介绍
Cadence HPC全系列解决方案介绍
Cadence 的低功耗、3D-IC 和人工智能 / 机器学习(AI / ML)技术可支持超大规模计算的数据之旅 —— 从存储和传输,到传感器和设备的数据处理要求;从近 / 远边缘处理,到本地云数据中心的工作负载优化计算。
高性能计算
新一代电子系统将显著影响我们的日常生活。从智能汽车应用、网络连接,到智能家居安全和防护领域、航空航天和国防,乃至医疗等更多领域,这些和我们日常生活相关的一切都是互联的。它们在边缘运行的大量传感器生成了海量数据。
我们要如何传输、处理、分析和存储这些数据?同时确保数据安全无虞?
答案就是采用高性能计算(High Performance Computing,简称 HPC)。
关于高性能计算
高性能计算(简称 HPC)是一项进行高速计算和数据处理的技术。HPC 作为计算机科学的一个分支,研究集群架构、并行算法和相关软件基础,通过分布式计算实现单台计算机无法达到的运算速度。
算力是高性能计算的第一要素,要达到每秒万亿次级的计算速度,对系统的处理器、内存带宽、运算方式、系统 I / O、存储等方面的要求都十分高,在满足算力的同时,低延迟、低功耗和数据的安全性也是行业关注的重点。
高性能计算中,计算、存储、网络三个部件不可或缺:
计算中心:
高性能 CPU + GPU 相结合,是发展高性能计算的基石。
网络中心:
计算服务器通过网络连接到一个集群,软件程序和算法同时在集群中的服务器上运行。集群通过网络连接数据存储。
存储中心:
要以最佳性能运行,每个组件都必须与其他组件保持同步,存储组件必须能够在处理数据时尽快将数据馈送和载入计算服务器。
如今,高性能计算现已迈入百亿亿次时代,HPC、云计算、AI 技术的相互融合,使得数据价值能够被更充分地挖掘。各个新兴行业应用的发展引起数据量激增,给芯片开发领域带来了诸多挑战。
HPC 高速发展给芯片开发
带来哪些挑战?
如何应对数据大爆发
在针对数据中心服务器的 CPU 需要增加更高的计算密度。
在芯片架构方面需要利用多 die 互联,提供更多对外接口。
使用小芯片(Chiplet)和 2.5D / 3D-IC 封装来解决设计尺寸接近或超过光罩尺寸导致的良率问题。
如何应对更高的存储需求
DDR5 / HBM2e 内存处理
PCIe Gen6 / CXL2.0 / UCIe 高速接口
此时,Cadence 在计算软件领域超过 30 年的专业技术积累和多年与客户密切合作的经验便派上了用场。
针对上述挑战,Cadence 提供设计、验证、实现的各个环节的解决方案,帮助客户优化适用于超大规模应用的 IP、芯片和系统。提供行业领先的虚拟云计算、快速的验证引擎以及智能的验证应用,让客户以低成本在短时间内找到并修复更多漏洞。解决针对 SoC 芯片架构复杂度增加带来的芯片设计挑战。
Cadence HPC 解决方案
请点击文章底部“阅读原文”
查看Cadence HPC 全系列解决方案
▷针对SoC芯片架构复杂度增加带来的芯片设计挑战Cadence Design IP提供高性能、低延迟的网络基础设施和存储解决方案:
- 40G UltraLink D2D PHY
- 112G - XSR PAM4 IP
- UCIe PHY and Controller
- DDR / LPDDR / HBM Phy and Controller
▷针对 SoC 设计规模超大带来的芯片验证效率降低,Cadence 提供更快的仿真速度、更大的设计容量:
- Xcelium MC / ML
- Dynamic Duo(Palladium / Protium)
▷针对 SoC 系统级性能分析以及软硬件协同验证挑战,Cadence 提供:
- System Performance Analyzer分析和解决系统性能瓶颈
- Helium virtual platform 提供由软件驱动的软硬件协同验证
▷针对边缘计算的低功耗和热需求:
- Palladium DPA.
- Xcelium Powerplay back
- Joules + Innovas power analysis and optimization
▷针对从边缘到云端的数据中心及 IoT 应用:
- SBSA 提供 Arm System Ready 架构认证解决方案
▷针对计算密度增加带来的芯片规模超出光罩尺寸:
- Cadence Integrity 3D-IC 平台
Cadence HPC 解决方案
成功案例
Nvidia 与 Cadence 合作应对超大规模 SoC 芯片设计和验证的巨大挑战
NVIDIA 作为 GPU 的发明者和人工智能计算的引领者世界上最大的 SoC 芯片的缔造者之一,随着芯片和系统复杂性的增长,NVIDIA 需要利用与时俱进的硬件仿真技术来应对芯片、系统和软件方面的挑战。
Cadence 的 Palladium Z2 和 Protium X2(系统动力双剑 Dynamic Duo)使得 NVIDIA 能够将设计从硬件仿真加速器转移到基于 FPGA 的系统,NVIDIA 的工程师可以轻松、从容地从 Palladium 硬件仿真加速平台转移到基于 FPGA 的 Protium 系统。
NVIDIA 的工程师现在可以在 4 个小时内,处理一个数十亿门级的设计,对之进行编译并创建一个硬件仿真模型,然后将其导入硬件仿真加速器,而在不久之前,完成同样的过程还需要 48 小时甚至 72 小时现在,只需 4 个小时。这是硬件仿真技术领域的一项突破性技术。
凭借 Cadence 的解决方案,您可以在超大规模计算设计中实现性能与低功耗、能耗和成本的最佳平衡。优化软硬件、系统级热、流动性和热效应。凭借 3D-IC 集成超越摩尔定律,以更短的周转时间实现最复杂的设计。
如您需了解更多这部分的内容请点击“阅读原文”了解Cadence HPC 全系列解决方案。
注:注册成功且通过 Cadence 审核的用户可获得完整版 PPT 资料。审核通过后 Cadence 会将 PPT 发送至您的邮箱,提供您的公司邮箱地址通过审核的几率更大哦。
审核编辑:汤梓红
-
Cadence
+关注
关注
65文章
921浏览量
142077 -
人工智能
+关注
关注
1791文章
47183浏览量
238258 -
HPC
+关注
关注
0文章
315浏览量
23754 -
高性能计算
+关注
关注
0文章
82浏览量
13385
原文标题:Cadence HPC 全系列解决方案
文章出处:【微信号:gh_fca7f1c2678a,微信公众号:Cadence楷登】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
高效节能的AI和HPC电源解决方案 MPS开放式加速器模块(OAM)电源系统
云计算hpc的主要功能是什么
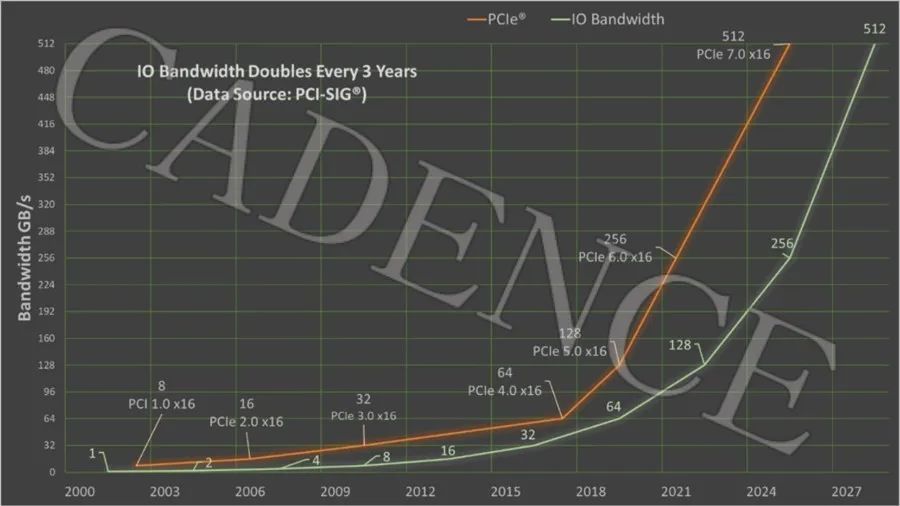
Cadence展示完整的PCIe 7.0 IP解决方案
亿纬锂能闪耀SNEC 2024,展现全系列储能解决方案
美光全系列车规级解决方案已通过高通汽车平台验证
芯驰科技发布新一代区域控制器(ZCU)全系列协同解决方案







 工商网监
工商网监
评论