 ERNIE 3.0 Tiny新模型,压缩部署“小”“快”“灵”!欢迎在 NGC 飞桨容器中体验 PaddleNLP 最新版本
ERNIE 3.0 Tiny新模型,压缩部署“小”“快”“灵”!欢迎在 NGC 飞桨容器中体验 PaddleNLP 最新版本
PaddleNLP 又带着新功能和大家见面了。本次更新,为大家带来文心 ERNIE 3.0 Tiny 轻量级模型,刷新了中文小模型的 SOTA 成绩;通过模型裁剪、量化感知训练、Embedding 量化等压缩方案,能够进一步提升模型推理速度、降低模型大小、显存占用。欢迎广大开发者使用 NVIDIA 与飞桨联合深度适配的 NGC 飞桨容器,在 NVIDIA GPU 上体验 ERNIE 3.0 Tiny。
ERNIE 3.0 Tiny 与配套压缩部署方案介绍
ERNIE 3.0 Tiny
近年来,随着深度学习技术的迅速发展,大规模预训练范式通过一次又一次刷新各种评测基线证明了其卓越的学习与迁移能力。在这个过程中,研究者们发现通过不断地扩大模型参数便能持续提升深度学习模型的威力。然而,参数的指数级增长意味着模型体积增大、所需计算资源增多、计算耗时更长,而这无论出于业务线上响应效率的要求还是机器资源预算问题,都给大模型落地带来了极大的挑战。
如何选择最优模型?如何在保证效果的前提下压缩模型?如何适配 GPU、CPU 等多硬件的加速?如何在低资源场景下落地大模型?如何让加速工具触手可及?这是行业内亟待解决的课题。2022 年 6 月,文心大模型中的轻量化技术加持的多个文心 ERNIE 3.0 Tiny 轻量级模型(下文简称文心 ERNIE 3.0 Tiny v1)开源至飞桨自然语言处理模型库 PaddleNLP 中,该模型刷新了中文小模型的 SOTA 成绩,配套模型动态裁剪和量化推理方案,被学术与工业界广泛使用。
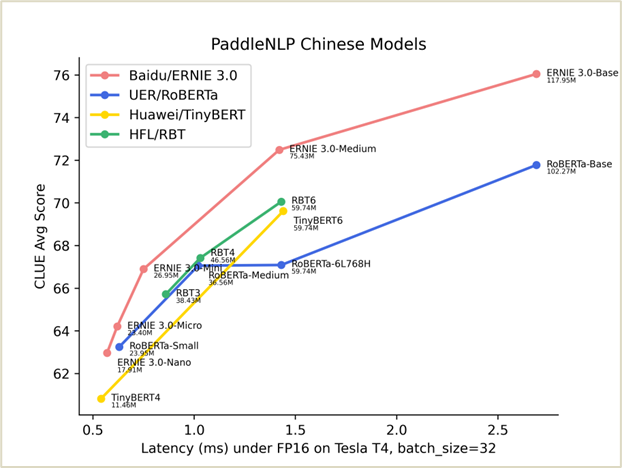
图:GPU 下 ERNIE 3.0 Tiny 轻量级模型时延与效果图
图中,越偏左上方的模型越优秀,可以看到 ERNIE 3.0 轻量级模型在同等规模的开源模型中,综合实力领先其他同类型轻量级模型。与 RoBERTa-Base 相比,12L768H 的 ERNIE 3.0-Base 平均精度绝对提升了 1.9 个点,比同等规模的 BERT-Base-Chinese 提升 3.5 个点;6L768H 的 ERNIE 3.0-Medium 相比 12L768H 的 UER/Chinese-RoBERTa ,在节省一倍运算时间基础上,获得比两倍大的 RoBERTa 更好的效果。
近日,文心 ERNIE 3.0 Tiny 升级版–––文心 ERNIE 3.0 Tiny v2 也开源了!相较于 v1,文心 ERNIE 3.0 Tiny v2 在 Out-domain(域外数据)、Low-resource(小样本数据)的下游任务上精度显著提升,并且 v2 还开源了 3L128H 结构,5.99M 参数量的小模型,更适用于低资源场景。
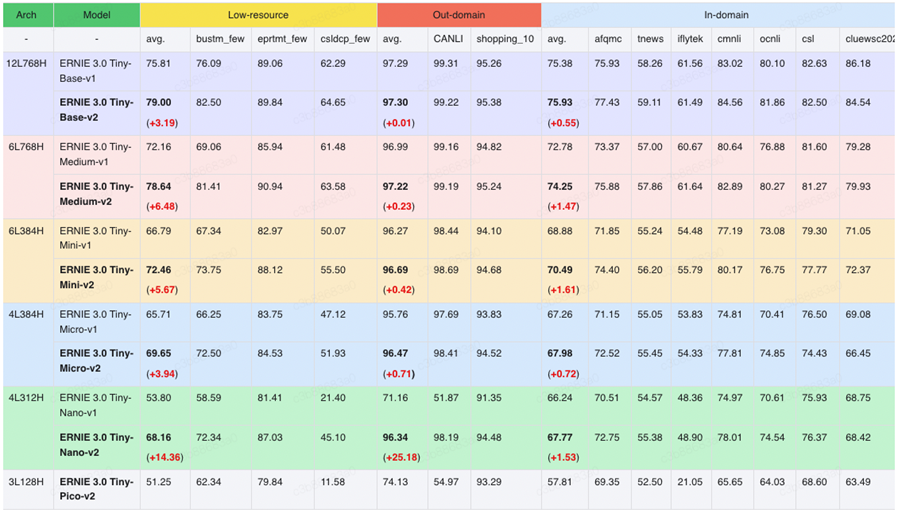
表:ERNIE 3.0 Tiny v2 效果更优
文心 ERNIE 3.0 Tiny v2 包含一系列不同尺寸的中文预训练模型,方便不同性能需求的应用场景使用:
-
文心ERNIE 3.0 Tiny-Base-v2(12-layer, 768-hidden, 12-heads)
-
文心ERNIE 3.0 Tiny-Medium-v2(6-layer, 768-hidden, 12-heads)
-
文心ERNIE 3.0 Tiny-Mini-v2(6-layer, 384-hidden, 12-heads)
-
文心ERNIE 3.0 Tiny-Micro-v2(4-layer, 384-hidden, 12-heads)
-
文心ERNIE 3.0 Tiny-Nano-v2(4-layer, 312-hidden, 12-heads)
-
文心ERNIE 3.0 Tiny-Pico-v2(3-layer, 128-hidden, 2-heads)
除以上中文模型外,本次还发布了英文版文心 ERNIE 3.0 Tiny-Mini-v2,适用于各类英文任务。
在 PaddleNLP 中,可一键加载以上模型。

开源地址:https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/ernie-tiny
语义理解模型压缩、部署方案
由文心大模型蒸馏得到的文心 ERNIE 3.0 Tiny v2 可以直接在下游任务上微调应用,如果想要进一步压缩模型体积,降低推理时延,可使用 PaddleNLP 开源的语义理解模型压缩、部署方案。
结合飞桨模型压缩工具 PaddleSlim,PaddleNLP 发布了语义理解压缩、部署方案,包含裁剪、量化级联压缩,如下图所示:

以上各类压缩策略以及对应的推理功能如果从零实现非常复杂,飞桨模型压缩工具库 PaddleSlim 和飞桨高性能深度学习端侧推理引擎 Paddle Lite 提供了一系列压缩、推理工具链。飞桨 AI 推理部署工具 FastDeploy 对其进一步封装,使开发者可以通过更简单的 API 去实现模型压缩、推理部署流程,适配多领域模型,并兼容多硬件。PaddleNLP 依托以上工具,提供 NLP 模型数据处理、训练、压缩、部署全流程的最佳实践。
基于 PaddleNLP 提供的的模型压缩 API,可大幅降低开发成本。压缩 API 支持对 ERNIE、BERT 等 transformer 类下游任务微调模型进行裁剪和量化。只需要简单地调用 compress()即可一键启动裁剪量化流程,并自动保存压缩后的模型。
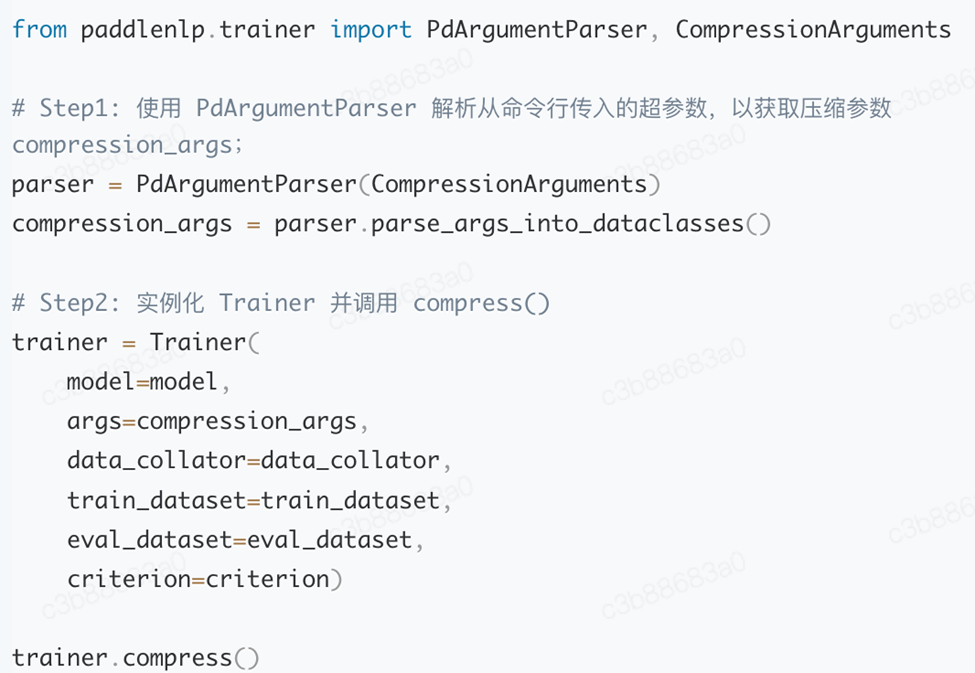
下面会对压缩方案(词表裁剪、模型宽度裁剪、量化感知训练、词表量化)与部署工具进行介绍。
词表裁剪
ERNIE 3.0 Tiny 预训练模型的词表参数量在总参数量中占比很大。在内存有限的场景下,推荐在下游任务微调之前,按照词频对词表进行裁剪,去除出现频次较低的词,这样能够减少分词后 [UNK] 的出现,使精度得到最大限度保持。例如,某数据集 4w 大小的词表,高频出现的词不到 1w 个,此时通过词表裁剪可以节省不少内存。
模型宽度裁剪
基于 DynaBERT 宽度自适应裁剪策略,通过知识蒸馏的方法,在下游任务中将 ERNIE 3.0 Tiny 的知识迁移到宽度更窄的学生网络中,最后得到效果与教师模型接近的学生模型。一般来说,对于 4 到 6 层的 NLU 模型,宽度裁剪 1/4 可基本保证精度无损。
量化感知训练
模型量化是一种通过将训练好的模型参数、激活值从 FP32 浮点数转换成 INT8 整数来减小存储、加快计算速度、降低功耗的模型压缩方法。目前主要有两种量化方法:
• 静态离线量化:使用少量校准数据计算量化信息,可快速得到量化模型;
• 量化感知训练:在模型中插入量化、反量化算子并进行训练,使模型在训练中学习到量化信息 。
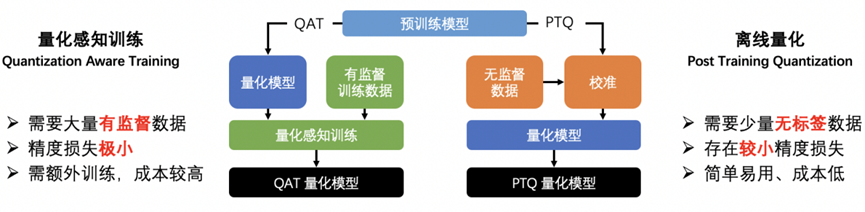
图:量化感知训练 vs 离线量化
在对 ERNIE 3.0 Tiny 的压缩中,更推荐使用量化感知训练的方式。通常情况下,使用量化感知训练的方法能够比使用静态离线量化取得更高的精度。这是因为在量化感知训练之前,压缩 API 在模型的矩阵乘算子前插入量化、反量化算子,使量化带来的误差可以在训练过程中被建模和优化,能够使模型被量化后精度基本无损。
Embedding 量化
为了能进一步节省显存占用,可对模型的 Embedding 权重进行 INT8量化,并将精度的损失保持在 0.5%之内。
部署
模型压缩后,精度基本无损。到此,算法侧的工作基本完成。为了进一步降低部署难度,可以使用飞桨 FastDeploy 对模型进行部署。
FastDeploy 是一款全场景、易用灵活、极致高效的 AI 推理部署工具,提供开箱即用的部署体验。FastDeploy 为 NLP 任务提供了一整套完整的部署 Pipeline,提供文心 ERNIE 3.0 Tiny 模型从文本预处理、推理引擎 Runtime 以及后处理三个阶段所需要的接口模块,开发者可以基于这些接口模块在云、边、端上部署各类常见的 NLP 任务,如文本分类、序列标注、信息抽取等。
FastDeploy 中的 Paddle Lite 后端基于算子融合和常量折叠对深度模型进行优化,无缝衔接了 Paddle Lite 的 FP16 和 INT8 的推理能力,可使模型推理速度大幅提升。其集成的高性能 NLP 处理库 FastTokenizer(视觉领域集成了高性能 AI 处理库 FlyCV),能够对分词阶段进行加速,适配 GPU、CPU 等多硬件。
FastDeploy 项目地址:https://github.com/PaddlePaddle/FastDeploy
文心大模型
随着数据井喷、算法进步和算力突破,效果好、泛化能力强、通用性强的预训练大模型(以下简称“大模型”),成为人工智能发展的关键方向与人工智能产业应用的基础底座。
百度文心大模型源于产业、服务于产业,是产业级知识增强大模型。百度通过大模型与国产深度学习框架融合发展,打造了自主创新的 AI 底座,大幅降低了 AI 开发和应用的门槛,满足真实场景中的应用需求,真正发挥大模型驱动 AI 规模化应用的产业价值。
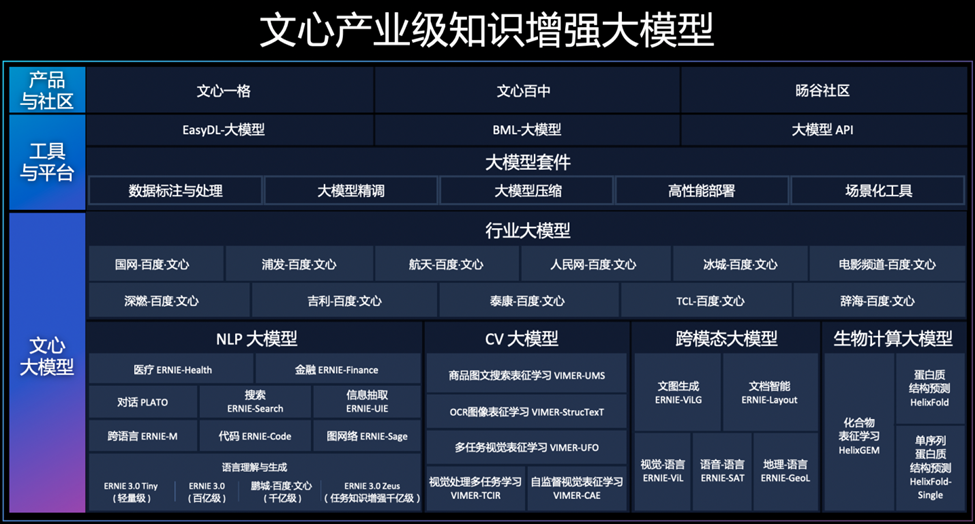
文心大模型包含基础通用大模型及面向重点领域和重点任务的大模型,同时有丰富的工具与平台支撑高效便捷的应用开发。学习效率高,可解释性好,大幅降低AI开发与应用门槛。
从技术研发到落地应用,大模型的发展已经进入产业落地的关键期,欢迎前往文心大模型官网了解详情:https://wenxin.baidu.com/。也欢迎使用NGC,体验文心大模型。
加入 PaddleNLP 技术交流群,体验 NVIDIA NGC + PaddleNLP
入群方式:微信扫描下方二维码,关注公众号,填写问卷后进入微信群随时进行技术交流。

NGC 飞桨容器介绍
如果您希望体验 PaddleNLP 的新特性,欢迎使用 NGC 飞桨容器。NVIDIA 与百度飞桨联合开发了 NGC 飞桨容器,将最新版本的飞桨与最新的NVIDIA的软件栈(如CUDA)进行了无缝的集成与性能优化,最大程度的释放飞桨框架在 NVIDIA 最新硬件上的计算能力。这样,用户不仅可以快速开启 AI 应用,专注于创新和应用本身,还能够在 AI 训练和推理任务上获得飞桨+NVIDIA 带来的飞速体验。
最佳的开发环境搭建工具 - 容器技术
-
容器其实是一个开箱即用的服务器。极大降低了深度学习开发环境的搭建难度。例如你的开发环境中包含其他依赖进程(redis,MySQL,Ngnix,selenium-hub等等),或者你需要进行跨操作系统级别的迁移
-
容器镜像方便了开发者的版本化管理
-
容器镜像是一种易于复现的开发环境载体
-
容器技术支持多容器同时运行
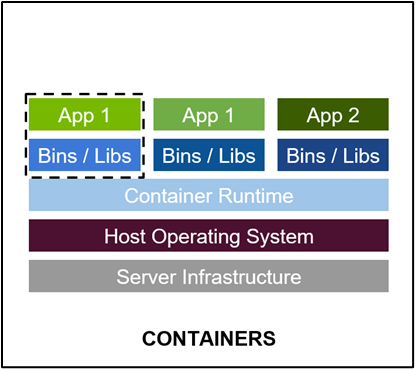
最好的 PaddlePaddle 容器
NGC 飞桨容器针对 NVIDIA GPU 加速进行了优化,并包含一组经过验证的库,可启用和优化 NVIDIA GPU 性能。此容器还可能包含对 PaddlePaddle 源代码的修改,以最大限度地提高性能和兼容性。此容器还包含用于加速 ETL (DALI, RAPIDS),、训练(cuDNN, NCCL)和推理(TensorRT)工作负载的软件。
PaddlePaddle 容器具有以下优点:
-
适配最新版本的 NVIDIA 软件栈(例如最新版本CUDA),更多功能,更高性能
-
更新的 Ubuntu 操作系统,更好的软件兼容性
-
按月更新
-
满足 NVIDIA NGC 开发及验证规范,质量管理
通过飞桨官网快速获取
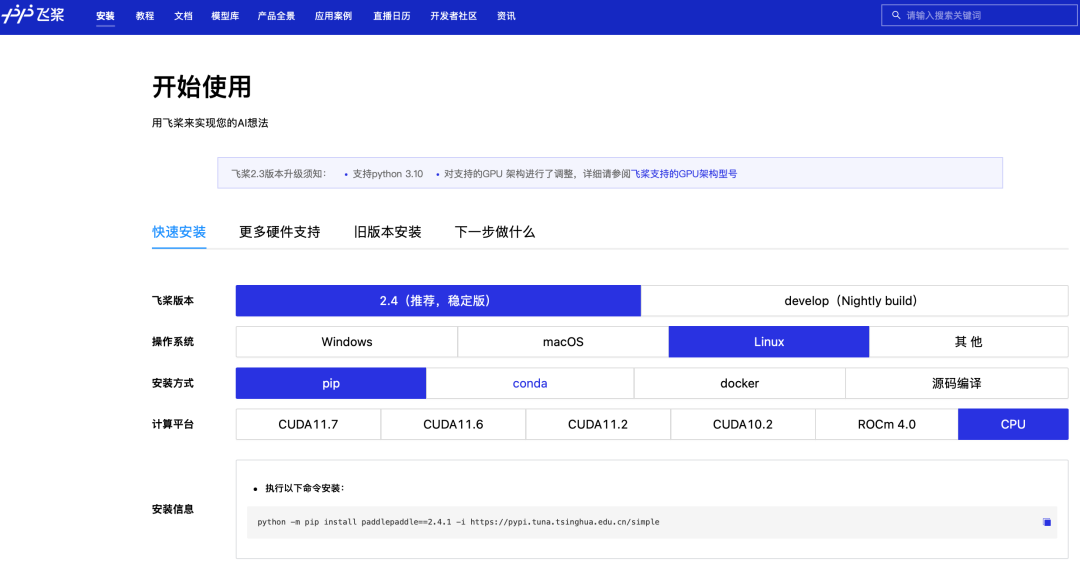
环境准备
使用 NGC 飞桨容器需要主机系统(Linux)安装以下内容:
-
Docker 引擎
-
NVIDIA GPU 驱动程序
-
NVIDIA 容器工具包
有关支持的版本,请参阅 NVIDIA 框架容器支持矩阵 和 NVIDIA 容器工具包文档。
不需要其他安装、编译或依赖管理。无需安装 NVIDIA CUDA Toolkit。
NGC 飞桨容器正式安装:
要运行容器,请按照 NVIDIA Containers For Deep Learning Frameworks User’s Guide 中 Running A Container一章中的说明发出适当的命令,并指定注册表、存储库和标签。有关使用 NGC 的更多信息,请参阅 NGC 容器用户指南。如果您有 Docker 19.03 或更高版本,启动容器的典型命令是:
dockerrun--gpusall--shm-size=1g--ulimitmemlock=-1-it--rm
nvcr.io/nvidia/paddlepaddle:22.08-py3
*详细安装介绍 《NGC 飞桨容器安装指南》
https://www.paddlepaddle.org.cn/documentation/docs/zh/install/install_NGC_PaddlePaddle_ch.html
【飞桨开发者说|NGC飞桨容器全新上线 NVIDIA产品专家全面解读】
https://www.bilibili.com/video/BV16B4y1V7ue?share_source=copy_web&vd_source=266ac44430b3656de0c2f4e58b4daf82
飞桨与 NVIDIA NGC 合作介绍
NVIDIA 非常重视中国市场,特别关注中国的生态伙伴,而当前飞桨拥有超过 535 万的开发者。在过去五年里我们紧密合作,深度融合,做了大量适配工作,如下图所示。

今年,我们将飞桨列为 NVIDIA 全球前三的深度学习框架合作伙伴。我们在中国已经设立了专门的工程团队支持,赋能飞桨生态。
为了让更多的开发者能用上基于 NVIDIA 最新的高性能硬件和软件栈。当前,我们正在进行全新一代 NVIDIA GPU H100 的适配工作,以及提高飞桨对 CUDA Operation API 的使用率,让飞桨的开发者拥有优秀的用户体验及极致性能。
以上的各种适配,仅仅是让飞桨的开发者拥有高性能的推理训练成为可能。但是,这些离行业开发者还很远,门槛还很高,难度还很大。
为此,我们将刚刚这些集成和优化工作,整合到三大产品线中。其中 NGC 飞桨容器最为闪亮。
NVIDIA NGC Container – 最佳的飞桨开发环境,集成最新的 NVIDIA 工具包(例如 CUDA)


点击 “阅读原文” 或扫描下方海报二维码,即可免费注册 GTC23,在 3 月 24 日 听 OpenAI 联合创始人与 NVIDIA 创始人的炉边谈话,会议将由 NVIDIA 专家主持,配中文讲解和实时答疑,一起看 AI 的现状和未来!
原文标题:ERNIE 3.0 Tiny新模型,压缩部署“小”“快”“灵”!欢迎在 NGC 飞桨容器中体验 PaddleNLP 最新版本
文章出处:【微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
-
英伟达
+关注
关注
22文章
3743浏览量
90825
原文标题:ERNIE 3.0 Tiny新模型,压缩部署“小”“快”“灵”!欢迎在 NGC 飞桨容器中体验 PaddleNLP 最新版本
文章出处:【微信号:NVIDIA-Enterprise,微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
IBM发布面向企业的人工智能模型新版本
品英Pickering最新版本的微波开关设计工具, 增强了仿真能力和原理图设计功能

经纬恒润INTEWORK-TPA 新版本正式发布

需要自定义量产烧录软件,esptool.py最新版本(v2.1)不支持ESP8285如何解决?
百度发布文心大模型4.0 Turbo与飞桨框架3.0,引领AI技术新篇章
谷歌DeepMind发布人工智能模型AlphaFold最新版本
CANoe新版本18正式发布

用的IAR For STM8最新版本3.10.2 ,编译提示错误的原因?
请问最新版本的FOC SDK不支持ACIM电机吗?
OpenVINO™ C# API部署YOLOv9目标检测和实例分割模型
关于博达透传工具新版本升级公告

STM32CubeMX安装最新版本V6.9,Motor Control Workbench生成项目工程总是显示STM32CubeMX not found的原因?
STMCWB最新版本是否支持绝对值编码器?只能通过MCLIB库手动增加吗?
TSMaster 2024年1月最新版本,新功能太实用






 工商网监
工商网监
评论