 ChatGPT的逻辑推理能力是如何学到的?
ChatGPT的逻辑推理能力是如何学到的?
看到ChatGPT的华丽诞生,心情很复杂,既高兴、惊喜,也感到恐慌,高兴和惊喜的是没有预料到这么快就见证了自然语言处理(NLP)技术的重大突破,体验到通用技术的无限魅力。恐慌的是ChatGPT几乎可以高质量地完成NLP中的大多数任务,逐渐认识到很多NLP的研究方向遇到了极大挑战。
总体而言,ChatGPT最令人非常惊艳的是它的通用性,相比于GPT-3需要通过设计非常精巧的提示来实现效果并不太好的各种NLP能力,ChatGPT已经让用户感受不到提示的存在。作为一个对话系统,ChatGPT让用户自然提问便可实现从理解到生成的各种任务,而且性能在开放领域几乎都达到了当前最佳水平,很多任务超越了针对特定任务单独设计的模型,并且在代码编程领域表现卓越。具体而言,自然语言理解能力(尤其是用户意图理解能力)十分突出,无论是问答、聊天、分类、摘要、翻译等任务,尽管回复不一定完全正确,但是几乎都能够领会用户意图,理解能力远超预期。相比于理解能力,ChatGPT的生成能力更加强大,可以针对各种问题生成具有一定逻辑且多样化的长文本。总的来说,ChatGPT表现出的更多是惊艳,是通向AGI的初步阶段,一些技术瓶颈解决后会更加强大。
对于ChatGPT表现案例的总结已经非常多了,这里主要总结一下自己对ChatGPT技术问题的一些思考,算是与ChatGPT断断续续交互两个多月的一个简单总结。由于无法了解ChatGPT的具体实现技术和细节,所以几乎都是主观猜想,肯定有很多不对的地方,欢迎一起探讨。
1. ChatGPT的通用性为何做得如此之好?
只要使用过ChatGPT,我们就会发现它不是一个传统意义上的人机对话系统,实际是一个以自然语言为交互方式的通用语言处理平台。2020年的GPT-3虽然拥有了通用能力的雏形,但是需要精心设计提示语来触发相应功能,而ChatGPT允许用户采用非常自然的提问就可以准确识别意图完成各种功能。传统方法往往先进行用户意图识别,再针对不同意图调用相应功能的处理模块,例如通过用户数据识别出摘要或翻译意图,再调用文本摘要或机器翻译模型。传统方法在开放域的意图识别准确率不够理想,而且不同功能模块各自为战无法共享信息,难以形成强大的NLP通用平台。ChatGPT突破了各自为战的模式,不再区分不同功能,统一认为是对话过程中的一种特定需求。那么,ChatGPT的通用性为何做得如此之好呢?一直在思考这个问题,由于没有条件实验证实,所以仅能猜想。根据Google的Instruction Tuning研究工作FLAN,当模型达到一定规模(e.g. 68B)且Instruction任务的类型达到一定数目(e.g. 40),模型就涌现出对新意图的识别能力。OpenAI从其开放的API中收集了全球用户各种任务类型的对话数据,根据意图分类和标注,然后在175B参数GPT-3.5上进行Instruction Tuning,自然就涌现出了通用的意图识别能力。
2. 为什么面向对话的微调没有遭遇灾难性遗忘问题?
灾难性遗忘问题一直是深度学习中的一个挑战,经常因为在某个任务上训练后就丧失了在其他任务上的性能。例如,一个30亿参数的基础模型,先在自动问答数据上进行微调,然后在多轮对话数据上进行微调,结果会发现模型的问答能力大幅度下降。ChatGPT似乎不存在这个问题,其在基础模型GPT-3.5上进行了两次微调,第一次依据人工标注的对话数据进行微调,第二次根据人类反馈的强化学习进行微调,微调使用的数据很少,尤其是人类反馈的打分排序数据更少,微调后竟然仍然表现出强大的通用能力,而并没有完全过拟合到对话任务。这是个非常有趣的现象,也是我们没有条件验证的现象。猜测可能有两方面的原因,一方面是ChatGPT使用的对话微调数据实际可能包含了非常全面的NLP各种任务,正如InstructGPT中对用户使用API的问题分类可以发现,很多都不是简单的对话,还有分类、问答、摘要、翻译、代码生成等等,因此,ChatGPT实际是对若干任务同时进行了微调;另一方面,可能当基础模型足够大之后,在较小数据上的微调不会对模型产生很大影响,可能仅在基础模型参数空间非常小的邻域中优化,所以不会显著影响基础模型的通用能力。
3. ChatGPT的大范围上下文连续对话能力是如何做到的?
使用ChatGPT时就会发现它一个让人十分惊讶的能力,即使和ChatGPT交互了十多轮,它仍然还记得第一轮的信息,而且能够根据用户意图比较准确地识别省略、指代等细粒度语言现象。这些对我们人来说似乎不算问题,但是在NLP的研究历史中,省略、指代等问题一直是一个难以逾越的挑战。此外,在传统对话系统中,对话轮次多了之后,话题的一致性难以保障。但是,ChatGPT几乎不存在这个问题,即使轮次再多,似乎都可以保持对话主题的一致性和专注度。猜测这个能力可能有三方面的来源。首先,高质量的多轮对话数据是基础和关键,正如Google的LaMDA,OpenAI也采用人工标注的方式构造了大量高质量多轮对话数据,在此之上进行的微调将会激发模型的多轮对话能力。其次,基于人类反馈的强化学习因为提升了模型回复的拟人性,也会间接增强模型多轮对话的一致性能力。最后,模型对8192个语言单元(Token)的显式建模能力使其几乎可以记忆普通人一整天的对话数据,在一次对话交流中很难超出这个长度,因此,所有对话历史都已经被有效记忆,从而可以显著提升连续多轮对话的能力。
4. ChatGPT的交互修正能力是如何炼成的?
交互修正能力是智能的一种高级体现,对我们来人说稀松平常的事情却是机器的痛点。在交流过程中,被指出问题后我们会立刻意识到问题所在并及时准确地修正相关信息。对于机器而言,意识到问题、识别问题范围并更正对应信息的每一步都不是一件容易的事情。ChatGPT出现之前尚未看到过具有较强交互修正能力的通用模型。与ChatGPT交互后就会发现,无论是用户更改自己之前的说法还是指出ChatGPT的回复中存在的问题,ChatGPT都能够捕捉到修改意图,并准确识别出需要修改的部分,最后能够做出正确的修正。目前为止,没有发现任何模型相关的因素与交互修正能力直接相关,也不相信ChatGPT具有实时学习的能力,一方面是重启对话后ChatGPT可能还会犯相同错误,另一方面是基础大模型的优化学习从来都是从高频数据中总结频繁模式,一次对话无论如何也难以更新基础模型。相信更多的是基础语言大模型的一种历史信息处理技巧,不太确定的因素可能包括:(1)OpenAI人工构建的对话数据中包含一些交互修正的案例,微调后拥有了这样的能力;(2)人工反馈的强化学习使得模型输出更加符合人类偏好,从而在信息修正这类对话中表现得更加遵循人类的修正意图;(3)可能大模型达到一定规模(e.g. 60B)之后,原始训练数据中的交互修正案例就被学到了,模型交互修正的能力自然就涌现出来了。
5. ChatGPT的逻辑推理能力是如何学到的?
当我们询问ChatGPT一些逻辑推理相关的问题时,它并不是直接给出答案,而是展示出详细的逻辑推理步骤,最后给出推理结果。虽然鸡兔同笼等很多案例表明ChatGPT并没有学会推理本质,而仅仅学会了推理的表面逻辑,但是展示的推理步骤和框架基本是正确的。一个语言模型能够学习到基本的逻辑推理模式已经极大超越了预期,其推理能力溯源是非常有趣的一个问题。相关对比研究发现,当模型足够大,并且程序代码与文本数据混合训练时,程序代码的完整逻辑链就会迁移泛化到语言大模型,从而大模型就拥有了一定的推理能力。这种推理能力的习得有点神奇,但是也能理解,可能代码注释是从逻辑代码到语言大模型推理能力迁移泛化的桥梁。多语言能力应该也是类似的道理。ChatGPT的训练数据绝大部分是英文,中文数据占比极少,然而我们发现ChatGPT的中文能力虽然比不上英文,但是也非常强大。训练数据中的一些中英对照的平行数据可能就是英文能力迁移到中文能力的桥梁。
6. ChatGPT是否针对不同下游任务采用不同的解码策略?
ChatGPT有许多惊艳的表现,其中一个是它可以针对同一个问题生成多种不同的回复,显得很睿智。比如,我们不满意ChatGPT的回答,可以点击“重新生成”按钮,它立刻会生成另一种回复,若还是不满意可以继续让其重新生成。这一点在NLP领域并不神秘,对于语言模型来说是它的一个基本能力,也就是采样解码。一个文本片段的后面可能接不同的词语,语言模型会计算每个词语出现的概率,如果解码策略选择概率最大的词语输出,那么每次结果都是确定的,就无法生成多样性回复。如果按照词汇输出的概率分布进行采样,例如,“策略”的概率是0.5,“算法”的概率是0.3,然后采样解码输出“策略”的可能性就是50%,输出“算法”的可能性就是30%,从而保证了输出的多样性。因为采样过程是按照概率分布进行的,即使输出结果多样,但是每一次都是选择概率较大的结果,所以多种结果看起来都相对比较合理。对比不同类型的任务时,我们会发现ChatGPT的回复多样性针对不同下游任务差别比较大。针对“如何”、“为什么”等“How”、“Why”型任务时,重新生成的回复与之前的回复无论是表达方式还是具体内容具有较大差异,针对机器翻译、数学应用题等“What”型任务时,不同回复之间的差异非常细微,有时几乎没有变化。如果都是依据概率分布的采样解码,为何不同回复之间的差异如此之小。猜测一种理想情况可能是“What”型任务基础大模型学习到的概率分布非常尖锐(Sharp),例如学到的“策略”概率为0.8,“算法”概率为0.1,所以大多数时候采样到相同的结果,也就是前面例子中80%的可能性都会采样到“策略”;“How”、“Why”型任务基础大模型学习到的概率分布比较平滑(Smooth),例如“策略”概率为0.4,“算法”概率为0.3,所以不同时候可以采样到差异性较大的结果。如果ChatGPT能够学习到任务相关的非常理想的概率分布,那确实非常厉害,基于采样的解码策略就可以适用于所有任务。通常,关于机器翻译、数学计算、事实性问答等答案比较确定或者100%确定的任务,一般采用基于贪婪解码,也就是每次输出概率最高的词语。如果希望输出相同语义的多样性输出,大多采用基于柱搜索的解码方法,但较少采用基于采样的解码策略。从与ChatGPT的交互看,所有任务它似乎都采用了基于采样的解码方法,真是暴力美学。
7. ChatGPT能否解决事实可靠性问题?
答案缺乏可靠性是目前ChatGPT面临的最大挑战。特别是针对事实性和知识性相关的问答,ChatGPT有时候会一本正经地胡编乱造,生成虚假信息。即使让它给出来源和出处或者参考文献,ChatGPT通常也会生成一个不存在的网址或者从未发表过的文献。不过,ChatGPT通常会给用户一种比较好的感觉,也就是很多事实和知识它似乎都知道。实际上,ChatGPT就是一个语言大模型,语言大模型本质就是一种深度神经网络,深度神经网络本质就是一种统计模型,就是从高频数据中习得相关模式。很多常见的知识或事实,在训练数据中出现频率高,上下文之间的模式比较固定,预测的词语概率分布就比较尖锐,熵比较小,大模型容易记住,并在解码过程中输出正确的事实或知识。但是,有很多事件和知识即使在非常庞大的训练数据中也很少出现,大模型便无法学习到相关模式,上下文之间的模式比较松散,词语预测的概率分布比较平滑,熵比较大,大模型在推理过程中容易产生不确定性的随机输出。这是包括ChatGPT在内所有生成式模型的固有问题。如果仍然延续GPT系列架构,基础模型不做改变,从理论上讲是难以解决ChatGPT回复的事实可靠性问题。和搜索引擎的结合目前看是非常务实的一种方案,搜索引擎负责搜索可靠的事实信息来源,ChatGPT负责总结和归纳。如果希望ChatGPT解决事实回答的可靠性问题,可能需要进一步提升模型的拒识能力,也就是过滤掉模型确定无法回答的那些问题,同时还需要事实验证模块来验证ChatGPT回复的正确性。希望下一代GPT能够在这个问题上取得突破。
8. ChatGPT能否实现实时信息的学习?
ChatGPT的交互修正能力使得它看起来似乎拥有了实时的自主学习能力。正如上述讨论,ChatGPT可以依据用户提供的修改意图或者更正信息,立刻修正相关回复,表现出实时学习的能力。实则不然,学习能力体现的是学到的知识是普适的,可以运用在其他时间和其他场合,但是ChatGPT并没有展现出这个能力。ChatGPT只是在当前的对话中能够根据用户反馈进行了修正,当我们重启一个对话,测试相同的问题时,ChatGPT还会犯相同或类似的错误。一个疑问是为何ChatGPT不将修改后正确的信息存储到模型中呢?这里有两方面的问题。首先,用户反馈的信息并不一定是正确的,有时候故意引导ChatGPT做出不合理的回答,只是因为ChatGPT在基于人类反馈的强化学习中加深了对用户的依赖程度,所以ChatGPT在同一个对话过程中会非常相信用户的反馈。其次,即使用户反馈的信息是正确的,但因为可能出现频率不高,基础大模型不能根据低频数据更新参数,否则大模型就会对某些长尾数据进行过拟合从而失去通用性。所以,让ChatGPT实时进行学习非常困难,一种简单直观的方案就是每经过一段时间就利用新的数据微调ChatGPT。或者采用触发机制,当多个用户提交相同或相似反馈时触发模型的参数更新,从而增强模型的动态学习能力。
-
人工智能
+关注
关注
1791文章
47273浏览量
238449 -
nlp
+关注
关注
1文章
488浏览量
22035 -
ChatGPT
+关注
关注
29文章
1560浏览量
7646
发布评论请先 登录
相关推荐
大型语言模型的逻辑推理能力探究
机器人核心技术之一的自主导航该如何实现
科技大厂竞逐AIGC,中国的ChatGPT在哪?
不到1分钟开发一个GPT应用!各路大神疯狂整活,网友:ChatGPT就是新iPhone
基于逻辑推理的网络攻击想定生成系统
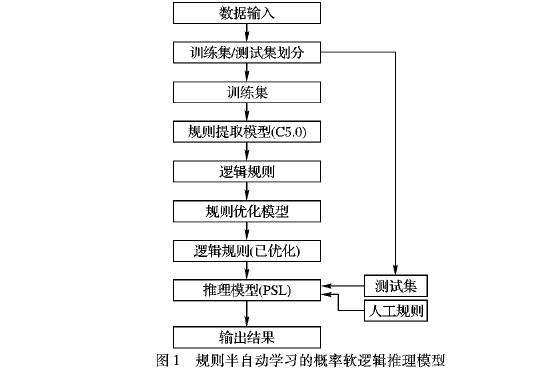
规则半自动学习的概率软逻辑推理模型
人工智能中的自动逻辑推理的算法介绍

ChatGPT破圈之后的思考
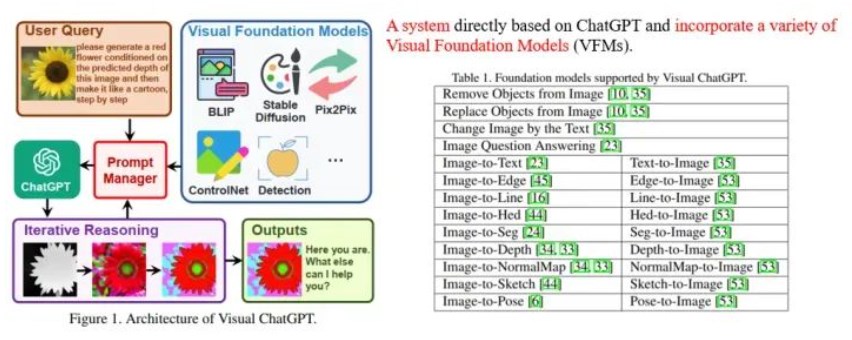
利用大语言模型做多模态任务
GPT-4没有推理能力吗?
人工智能的概念是什么

ChatGPT是一个好的因果推理器吗?

基于归结反演的大语言模型逻辑推断系统






 工商网监
工商网监
评论