 中文多模态对话数据集
中文多模态对话数据集
写在前面
早起刷arxiv,刷到一篇中文多模态对话数据集,分享给大家,全名为《TikTalk: A Multi-Modal Dialogue Dataset for Real-World Chitchat》,即一个真实闲聊多模态数据集,共包括38703个视频和相应367670个对话。
paper: https://arxiv.org/pdf/2301.05880.pdf
github: https://github.com/RUC-AIMind/TikTalk
介绍
随着大量预训练语言模型在文本对话任务中的出色表现,以及多模态的发展,在对话中引入多模态信息已经引起了大量学者的关注。目前已经提出了各种各样的多模态对话数据集,主要来自电影、电视剧、社交媒体平台等,但这些数据与真实世界的日常聊天对话之间还是存在一些差距。
- 对话形式过于同质化。 视频中的现场评论缺乏明确背景,更偏向于评论,并充斥着重复的数据用来活跃气氛。而从影视剧中提取出来的对话内容或解说员根据指定图片提出的对话内容,都不是现实对话场景中自然生成的聊天,而是为了推动情节发展设计的一些人物台词或高度依赖形象。
- 缺乏对话的时间顺序。 现实世界的多模态对话场景可能包含具有时间顺序的不同上下文,而目前大多数数据集中的静态图片所能提供的信息有限,限制了对话参与者在主题方面的多样性。并且不同的语言语境中存在着独特的表达方式和流行文化,很难进行翻译或迁移到其他语言。
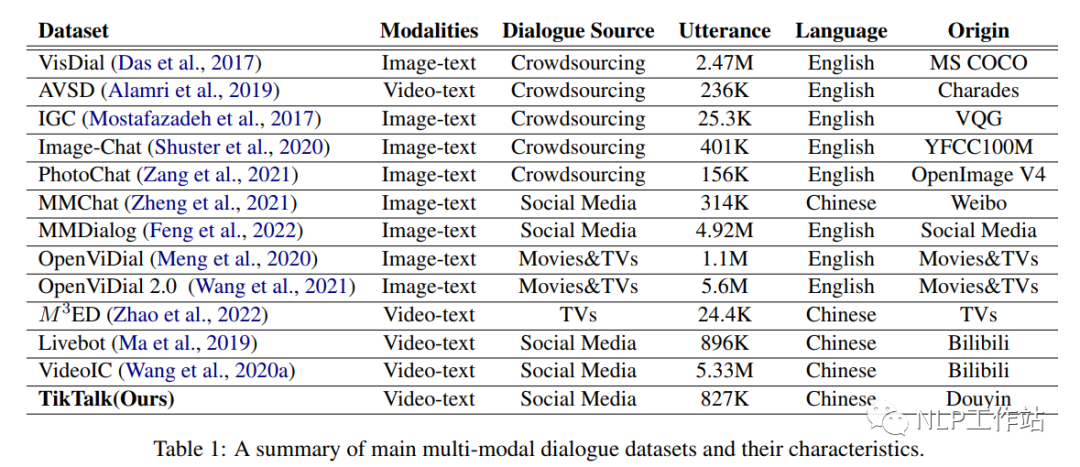 因此,该论文提出了具有独特特色的中文多模态对话数据集-TikTalk。TikTalk是基于视频的真实世界人类聊天语料库,是开放域的,并由用户自发生成非故意创建的数据集。其中,与图像、音频和外部知识相关的回复占比分别为42%、10%和34%,如图1(a)所示,聊天源于视频内容,图1(b)中的“其他表演”和舞蹈分析需要一些外部知识,图1(c)中的对话建立在音频内容之上。
因此,该论文提出了具有独特特色的中文多模态对话数据集-TikTalk。TikTalk是基于视频的真实世界人类聊天语料库,是开放域的,并由用户自发生成非故意创建的数据集。其中,与图像、音频和外部知识相关的回复占比分别为42%、10%和34%,如图1(a)所示,聊天源于视频内容,图1(b)中的“其他表演”和舞蹈分析需要一些外部知识,图1(c)中的对话建立在音频内容之上。 最后采用排名、相关性和多样性三种度量指标对现有生成模型进行分析,发现模型与人类表现仍有很大差距,在TikTalk数据集上有相当大的改进空间。
最后采用排名、相关性和多样性三种度量指标对现有生成模型进行分析,发现模型与人类表现仍有很大差距,在TikTalk数据集上有相当大的改进空间。
TikTalk Dataset
TikTalk数据集从抖音上采集,其抖音拥有超过25个大类的视频,如教育、美食、游戏、旅游、娱乐等。每个视频都有作者提供的标题和用户的评论。用户可以在视频和一级评论下进行进一步的讨论,这接近于现实世界面对面的多模态聊天场景。
Data Construction
该论文收集了2021年在抖音上发布的视频,以及标题、评论和回复。为了保护隐私,没有抓取任何用户信息。由于视频基数大,视频质量良莠不齐,大部分视频只有一级评论,无法构成对话语料库。由于视频高赞、评论高赞表示用户评分高,因此在爬取数据时通过点赞数过滤低质量的视频和评论。
数据清理时,用正则表达式过滤掉句子中无用的内容,例如:“@某人”、重复的词语、以及一些不道德的言论等;此外,评论中带有的表情符号,通常可以表明用户的情绪,因此,从对话中提取它们,并作为附加信息。
Data Statistics
该论文共爬取153340个视频,最终获取38703个视频和367670个对话来构建TikTalk数据集。将训练集、验证集和测试集按照35703、1000和2000进行划分,详细统计数据见表2。 可以看出,视频平均长度为34.03s,提供了丰富的视频和音频信息;每段对话的平均轮数为2.25,由于对话的文本上下文较短,回复更有可能来自视频或外部知识。
可以看出,视频平均长度为34.03s,提供了丰富的视频和音频信息;每段对话的平均轮数为2.25,由于对话的文本上下文较短,回复更有可能来自视频或外部知识。
Data Analysis
TikTalk数据集有如下几个特征:
- 高度自发和自由 ,对话是由用户观看视频后发起,没有任何的预先的意图及指导,类似于现实世界中的日常闲聊。
- 多种模式 ,对话上下文包括相关的图像、音频和文本,提供了更多样化的信息来源,同时也对聊天场景进行了更多的限制,提高了回答的可信度标准。
- 开放领域的 ,由于社交平台是开放域的,讨论话题也十分丰富。
观察数据发现,对话回复中经常包含与上下文信息相关的词语,例如:图1(a)中的“it”为视频中的“海鸥”,图1(c)中讨论了音频描述的故事,图1(b)中的回复中为上下文观点,并分析了视频外的其他节目,与个人经验及常识相关。因此,该论文分析了数据及中数据与各种信息相关的响应占比,包括视频中的视觉内容和音频内容、文本内容及隐形的外部知识。采用众包的方式进行数据标注,并选择另外其他三个具有代表性的对话数据集(每个数据集随机选取300个样本)进行对比。
从回复中提取名词和代词,要求标注人员判断这些词语或完整的回复是否是指:(1)视频上下文;(2)音频上下文;(3)文本上下文;(4)隐藏外部知识;(5)其他。并且,回复可以涉及多种模式的信息。
四种数据的比较如图2(a)所示。TikTalk数据除去文本上下文和外部知识后,信息源占比最高,表示视频中的图像和音频可以提供更多的信息。来自外部知识的回复比例最高(约33%,说明),说明多模态上下文更丰富时,会引入更多与当前对话相关的新信息。 进一步探究IGC和TikTalk之间的差异,研究当对话轮数数增加时,IGC和TikTalk对不同上下文的依赖性,如图2(b)和(c)所示。IGC数据集中图像与对话的比例显著下降,而TikTalk数据集中没有这种趋势。可能是因为IGC的每个对话中只使用一个图像,随着时间的推移,可用的信息越来越少。
进一步探究IGC和TikTalk之间的差异,研究当对话轮数数增加时,IGC和TikTalk对不同上下文的依赖性,如图2(b)和(c)所示。IGC数据集中图像与对话的比例显著下降,而TikTalk数据集中没有这种趋势。可能是因为IGC的每个对话中只使用一个图像,随着时间的推移,可用的信息越来越少。
Experiments
采用三个自动指标(相关性、排序、多样性),从多个角度评估模型在TikTalk上的性能,
- 相关性 :针对模型生成的回复,与5个金标准计算BLEU-2、BLEU-4 、Meteor、Rouge-L和CIDEr。
- 排序 :每段对话构建一个100个样本的候选集,其中包括5个金标准和95个随机选择的错误回复。在推理阶段,模型根据生成每个回复的对数似然分数降序对候选集进行排序。计算Recall@K和Mean Rank。
- 多样性 :计算回复的Dist-1和Dist-2指标。
从不同的任务和设置中评估一些最先进的对话模型,包括:Livebot、DialoGPT、Maria、Maria-Audio、Maria-C3KG等。为了适应TikTalk的特点,在现有的基于图像的对话模型中引入音频和外部知识作为输入,并分别对模型的性能进行评估。
实验结果如表3所示,可以看出TikTalk与以前的任务和数据集有很大不同,需要更强大的多模态对话模型。 从测试集和上述基线模型生成结果中选择了一些数据示例,对比结果如图3所示。由于视频场景和用户个性的多样性,TikTalk数据集需要复杂的理解和推理能力。虽然部分基线偶尔可以产生一些合理的响应,但它们远远不能满足现实世界多模式对话的期望。
从测试集和上述基线模型生成结果中选择了一些数据示例,对比结果如图3所示。由于视频场景和用户个性的多样性,TikTalk数据集需要复杂的理解和推理能力。虽然部分基线偶尔可以产生一些合理的响应,但它们远远不能满足现实世界多模式对话的期望。
-
数据集
+关注
关注
4文章
1220浏览量
25183 -
自然语言
+关注
关注
1文章
291浏览量
13557
发布评论请先 登录
相关推荐

关于多模态机器学习综述论文
2021 OPPO开发者大会:多终端对话式智能助手

DocumentAI的模型、任务和基准数据集
多模态GPT:国内发布一款可以在线使用的多模态聊天机器人!

多模态上下文指令调优数据集MIMIC-IT

VisCPM:迈向多语言多模态大模型时代

全球首个面向网联智能车的通信与多模态感知数据集发布
更强更通用:智源「悟道3.0」Emu多模态大模型开源,在多模态序列中「补全一切」

人工智能领域多模态的概念和应用场景
从Google多模态大模型看后续大模型应该具备哪些能力





 工商网监
工商网监
评论