 大数据应用的开发流程
大数据应用的开发流程
大数据常见处理流程包括:原始数据采集、数据清洗、数据存储、统计分析、存储至数据仓库、数据导出、导入数据库、数据可视化。
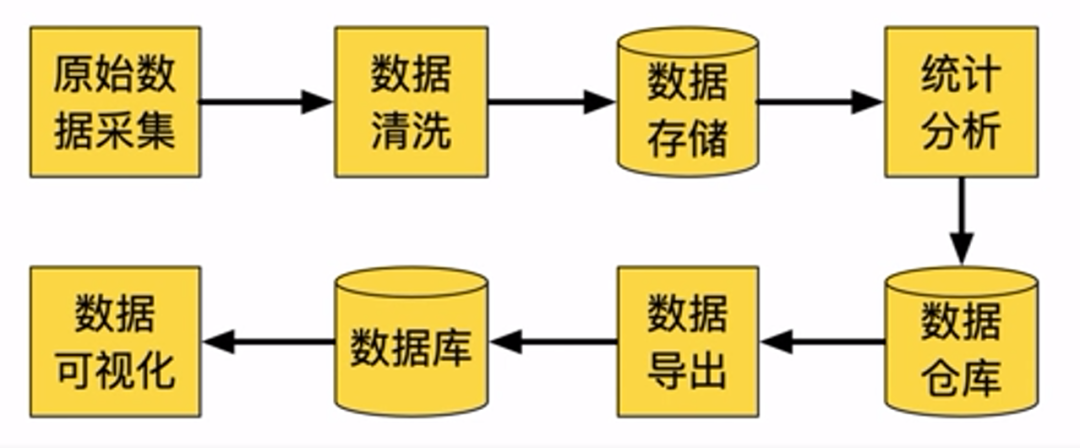
图片来源:学堂在线《大数据导论》
一、原始数据采集
原始数据采集的方式包括:爬虫程序采集、应用数据采集。
爬虫程序采集可在互联网中爬取需要的数据。
应用数据采集是指通过集群或分布式部署方式,将应用程序的日志文件存储于多个服务器中,再将日志文件数据集中存储。
二、数据清洗和数据存储
因为采集的数据中包含不符合要求的数据,如格式冲突的数据、漏项的数据、错误的数据等,所以需要数据清洗将不符合要求的数据去除。
数据清洗过程可以较简单,也可以较复杂。可以通过向数据缺失位置添加某值的方式简单完成数据清洗(含个人理解);也可以通过复杂的机器学习模型清洗数据。
数据清洗可借助ETL软件(根据百度百科:ETL是数据仓库技术)。一般,数据被清洗后,数据量较大,无法存储于计算机内存中,因此,需将数据存储于HDFS(数据存储)中或其他大数据存储方式中。
三、统计分析和数据仓库
统计分析可通过选择合适统计分析工具完成。可使用MapReduce技术实现并行统计分析,也可使用Hive数据仓库(Hive数据仓库具有数据整理、特殊查询、分析存储功能)、Python、R等进行统计分析。
统计分析的难点不在于选择统计分析工具,而在于需求和分析对象。个人理解:具体的需求和分析对象多样导致统计分析不能简单地以某一方式解决所有统计分析问题。
统计分析结束后,数据可被存储于数据仓库中,可使用Hive数据仓库搭建所需的数据仓库。数据仓库的数据不能直接向用户呈现。
四、数据导出和数据库
因为数据仓库的数据不能直接向用户呈现,所以需要将数据从数据仓库导出,并将数据导入数据库中以实现数据可视化。数据导出可使用Sqoop(Sqoop可提供数据导入功能)。
数据库一般为关系型数据库。
五、数据可视化
数据可视化的目标是使数据可被直观展示,传统图形化展示方式种类较多(根据网络资料理解:传统图形化展示方式包括条形图、排列图、饼图、环形图等)。大数据新型可视化方式包括:气泡图、数据画像、地图涂色等。
六、大数据应用案例
下文介绍Hadoop自带的MapReduce应用案例WordCount,WordCount可统计文件的词频。
(1)启动Hadoop系统服务,需启动HDFS与Yarn服务(根据百度百科:Yarn是新的Hadoop资源管理器,是通用资源管理系统)。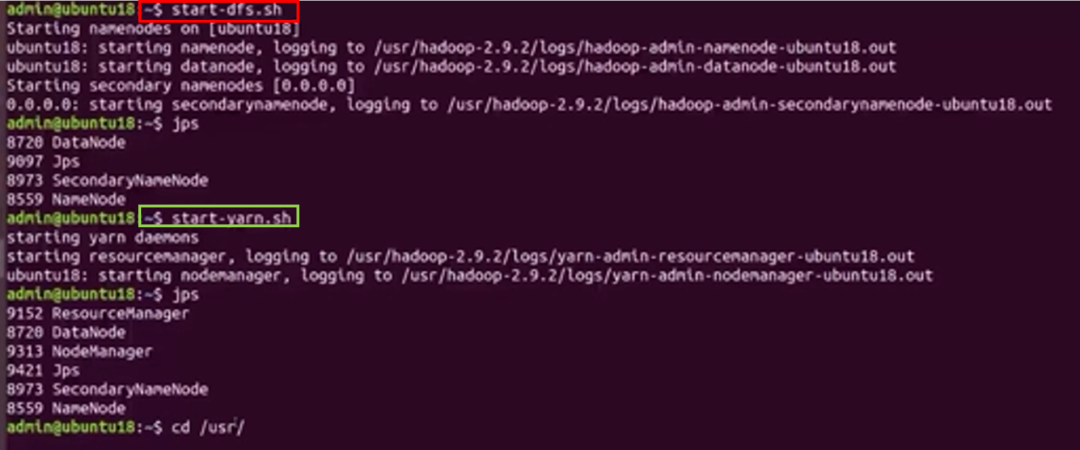
图中红框内命令为HDFS启动命令,绿框内命令为Yarn服务启动命令,图片来源:根据学堂在线《大数据导论》资料制作
(2)检查Hadoop安全模式是否为“OFF”状态,如果Hadoop安全模式的状态为“ON”,则只能读取HDFS中的数据,不能向HDFS中写入数据。
(3)准备需要处理的数据,即查看文本文件中的内容。
图中红框内命令为查看文件内容命令,绿框内为文件中的内容,图片来源:根据学堂在线《大数据导论》资料制作
(4)执行WordCount应用程序。WordCount的具体命令是hadoopjar hadoopmapreduce-examples-2.9.2.jarwordcount 被统计文件的目录名与文件名 统计结果输出文件目录名与文件名。
图中红框内为WordCount应用程序统计结果输出文件的内容,图片来源:根据学堂在线《大数据导论》资料制作
审核编辑:刘清
-
数据库
+关注
关注
7文章
3866浏览量
64965 -
机器学习
+关注
关注
66文章
8460浏览量
133379 -
python
+关注
关注
56文章
4812浏览量
85276 -
HDFS
+关注
关注
1文章
30浏览量
9694
原文标题:大数据相关介绍(11)——大数据应用的开发流程
文章出处:【微信号:行业学习与研究,微信公众号:行业学习与研究】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
大数据与云计算是干嘛的?
工程大数据平台
缓存对大数据处理的影响分析
ADS1675最大数据吞吐率是是多少?
raid 在大数据分析中的应用
emc技术在大数据分析中的角色
MCU开发流程中的注意事项
智慧城市与大数据的关系
基于Kepware的Hadoop大数据应用构建-提升数据价值利用效能
设备管理:大数据赋能开启智能新篇章

使用CYW20829的BLE进行最大数据发送应用,BLE丢失数据如何解决?
迪文串口屏ModBus开发流程






 工商网监
工商网监
评论