 PyTorch入门-1
PyTorch入门-1
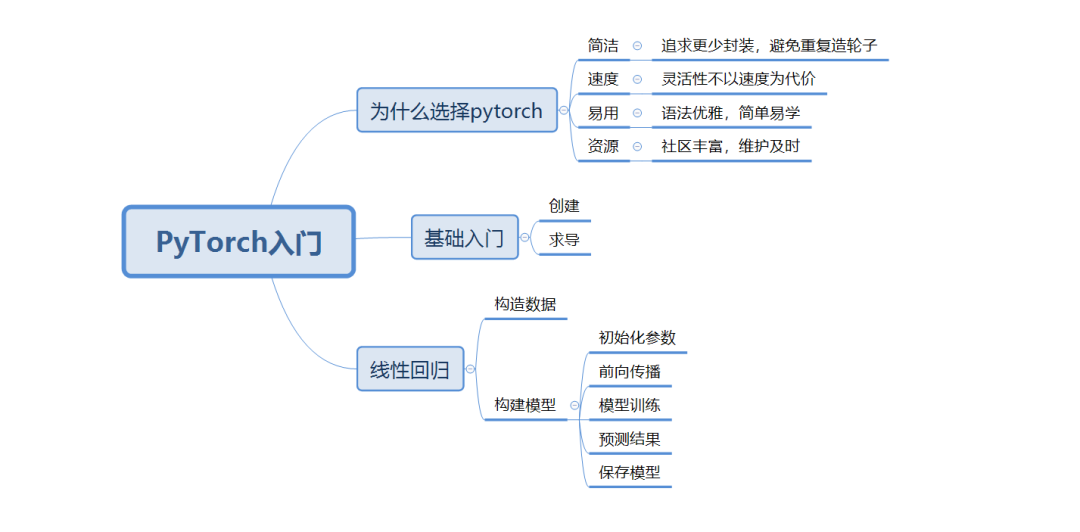
1.为什么选择PyTorch
1)简洁:追求更少封装,避免重复造轮子
2)速度:灵活性不以速度为代价
3)易用:语法优雅,简单易学
4)资源:社区丰富,维护及时
2.基础入门
1)安装(pip install torch)
2)创建tensor(PyTorch重要的数据结构)
3)自动求导
import numpy as np
import torch
#创建3行4列tensor,设置自动求导
x = torch.randn(3,4,requires_grad=True)
#输出结构
x

#初始化b
b = torch.randn(3,4,requires_grad=True)
#计算t
t = x + b
#求和
y = t.sum()
#反向传播计算
y.backward()
#输出b梯度
b.grad

实战一个例子(计算过程如下):
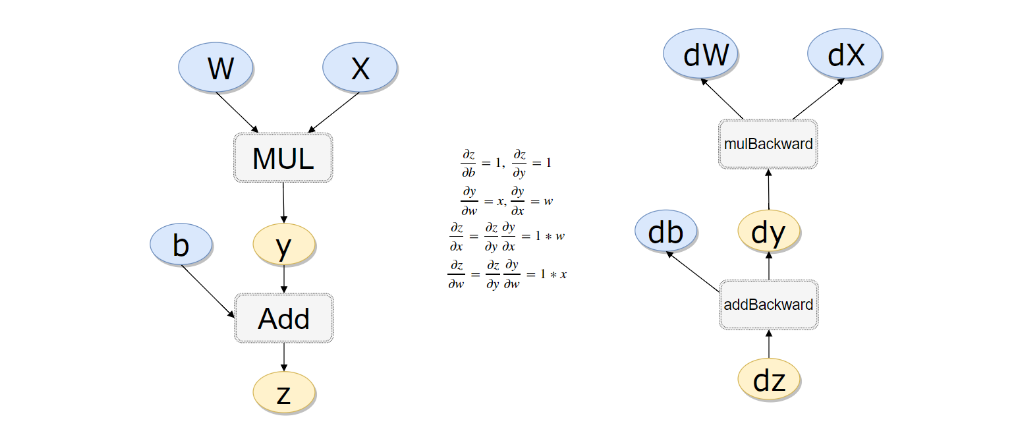
#计算流程
x = torch.rand(1)
b = torch.rand(1, requires_grad = True)
w = torch.rand(1, requires_grad = True)
y = w * x
z = y + b
#如果不清空会累加起来
z.backward(retain_graph=True)
#w梯度
w.grad

#b梯度
b.grad

3.搭建线性回归模型
1)构造数据
2)初始化参数
3)前向传播
4)模型训练
5)预测结果
6)保存模型
#初始化x值
x_values = [i for i in range(11)]
#转换为ndarray
x_train = np.array(x_values, dtype=np.float32)
#维度转换
x_train = x_train.reshape(-1, 1)
#查看形状,(11,1)
x_train.shape
#计算y值
y_values = [2*i + 1 for i in x_values]
#转换为ndarray
y_train = np.array(y_values, dtype=np.float32)
#维度转换
y_train = y_train.reshape(-1, 1)
#查看形状,(11,1)
y_train.shape
import torch
import torch.nn as nn
#线性回归模型(本质是一个不加激活函数的全连接层)
class LinearRegressionModel(nn.Module):
#初始化参数
def __init__(self, input_dim, output_dim):
super(LinearRegressionModel, self).__init__()
self.linear = nn.Linear(input_dim, output_dim)
#前向传播
def forward(self, x):
out = self.linear(x)
return out
#输入维度
input_dim = 1
#输出维度
output_dim = 1
#初始化模型
model = LinearRegressionModel(input_dim, output_dim)
#轮数
epochs = 1000
#学习率
learning_rate = 0.01
#随机梯度下降算法
optimizer = torch.optim.SGD(model.parameters(),
lr=learning_rate)
#定义均方损失函数
criterion = nn.MSELoss()
#遍历每一轮(这里使用CPU进行训练,建议使用GPU速度快)
for epoch in range(epochs):
#计算轮数
epoch += 1
#注意转换成tensor
inputs = torch.from_numpy(x_train)
labels = torch.from_numpy(y_train)
#梯度要清零每一次迭代
optimizer.zero_grad()
#前向传播
outputs = model(inputs)
#计算损失
loss = criterion(outputs, labels)
#返向传播
loss.backward()
#更新权重参数
optimizer.step()
#每50轮输出损失值
if epoch % 50 == 0:
print('epoch {}, loss {}'.format(epoch, loss.item()))

#预测训练数据集
predicted = model(torch.from_numpy(x_train).requires_grad_()).data.numpy()
#输出结果,跟我们真实y值几乎没有差别
predicted

#保存模型
torch.save(model.state_dict(), 'model.pkl')
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
速度
+关注
关注
1文章
33浏览量
15687 -
资源
+关注
关注
0文章
59浏览量
18016 -
pytorch
+关注
关注
2文章
808浏览量
13628
发布评论请先 登录
相关推荐
如何往星光2板子里装pytorch?
如题,想先gpu版本的pytorch只安装cpu版本的pytorch,pytorch官网提供了基于conda和pip两种安装方式。因为咱是risc架构没对应的conda,而使用pip安装提示也没有
发表于 09-12 06:30
Pytorch入门教程与范例
的深度学习框架。 对于系统学习 pytorch,官方提供了非常好的入门教程 ,同时还提供了面向深度学习的示例,同时热心网友分享了更简洁的示例。 1. overview 不同于 theano
发表于 11-15 17:50
•5525次阅读
PyTorch官网教程PyTorch深度学习:60分钟快速入门中文翻译版
“PyTorch 深度学习:60分钟快速入门”为 PyTorch 官网教程,网上已经有部分翻译作品,随着PyTorch1.0 版本的公布,这个教程有较大的代码改动,本人对教程进行重新翻
基于PyTorch的深度学习入门教程之PyTorch的安装和配置
神经网络结构,并且运用各种深度学习算法训练网络参数,进而解决各种任务。 本文从PyTorch环境配置开始。PyTorch是一种Python接口的深度学习框架,使用灵活,学习方便。还有其他主流的深度学习框架,例如Caffe,TensorFlow,CNTK等等,各有千秋。笔者
基于PyTorch的深度学习入门教程之PyTorch简单知识
本文参考PyTorch官网的教程,分为五个基本模块来介绍PyTorch。为了避免文章过长,这五个模块分别在五篇博文中介绍。 Part1:PyTorch简单知识 Part2:
基于PyTorch的深度学习入门教程之PyTorch的自动梯度计算
本文参考PyTorch官网的教程,分为五个基本模块来介绍PyTorch。为了避免文章过长,这五个模块分别在五篇博文中介绍。 Part1:PyTorch简单知识 Part2:
基于PyTorch的深度学习入门教程之使用PyTorch构建一个神经网络
前言 本文参考PyTorch官网的教程,分为五个基本模块来介绍PyTorch。为了避免文章过长,这五个模块分别在五篇博文中介绍。 Part1:PyTorch简单知识 P
基于PyTorch的深度学习入门教程之训练一个神经网络分类器
前言 本文参考PyTorch官网的教程,分为五个基本模块来介绍PyTorch。为了避免文章过长,这五个模块分别在五篇博文中介绍。 Part1:PyTorch简单知识 Part2:
基于PyTorch的深度学习入门教程之DataParallel使用多GPU
前言 本文参考PyTorch官网的教程,分为五个基本模块来介绍PyTorch。为了避免文章过长,这五个模块分别在五篇博文中介绍。 Part1:PyTorch简单知识 Part2:
基于PyTorch的深度学习入门教程之PyTorch重点综合实践
前言 PyTorch提供了两个主要特性: (1) 一个n维的Tensor,与numpy相似但是支持GPU运算。 (2) 搭建和训练神经网络的自动微分功能。 我们将会使用一个全连接的ReLU网络作为
深度学习框架pytorch入门与实践
深度学习框架pytorch入门与实践 深度学习是机器学习中的一个分支,它使用多层神经网络对大量数据进行学习,以实现人工智能的目标。在实现深度学习的过程中,选择一个适用的开发框架是非常关键





 工商网监
工商网监
评论