 AMD要在CPU上堆叠DRAM内存,新一代捆绑销售诞生?
AMD要在CPU上堆叠DRAM内存,新一代捆绑销售诞生?
电子发烧友网报道(文/周凯扬)自从2.5D/3D封装、Chiplet、异构集成等技术出现以来,CPU、GPU和内存之间的界限就已经变得逐渐模糊。单个SoC究竟集成了哪些逻辑单元和存储单元,全凭借厂商自己的设计路线。这样的设计其实为单芯片的能效比带来了一轮新的攀升,但也极大地增加了开发难度。即便如此,还是有不少厂商在不遗余力地朝这个方向发展,最典型的莫过于AMD。
AMD的存储堆叠之路
要说玩堆叠存储,AMD确实是走得最靠前的一位,例如AMD如今在消费级和数据中心级别CPU上逐渐使用的3D V-Cache技术,就是直接将SRAM缓存堆叠至CPU上。将在今年正式落地的第四代EPYC服务器处理器,就采用了13个5nm/6nm Chiplet混用的方案,最高将L3缓存堆叠至了可怕的384MB。
在消费端,AMD的Ryzen 7 5800X3D同样也以惊人的姿态出世,以超大缓存带来了极大的游戏性能提升。即将正式发售的Ryzen 9 7950X3D也打出了128MB三级缓存的夸张参数,这些产品的出现可谓打破了过去CPU厂商拼时钟频率、拼核心数的僵局,让消费者真切地感受到了额外的体验提升。

MI300 APU / AMD
GPU也不例外,虽然AMD如今的消费级GPU基本已经放弃了HBM堆叠方案,但是在AMD的数据中心GPU,例如Instinct MI250X,却依然靠着堆叠做到了128GB的HBM2e显存,做到了3276.8GB/s的峰值内存带宽。而下一代MI300,AMD则选择了转向APU方案,将CPU、GPU和HBM全部整合在一起,以新的架构冲击Exascale级的AI世代。
其实这也是AMD收购Xilinx最大的收获之一,早在十多年前Xilinx的3DIC技术也已经为多Die堆叠打下了基础。在收购Xilinx之际,AMD也提到这次交易会扩张AMD在die堆叠、封装、Chiplet和互联技术上的开发能力。在完成Xilinx的收购后,也可以看出AMD在架构上的创新有了很大的飞跃。
在近期的ISSCC 2023上,AMD CEO苏姿丰透露了他们的下一步野心,那就是直接将DRAM堆叠至CPU上。这里的堆叠并非硅中介层互联、存储单元垂直堆叠在一起的2.5D封装方案,也就是如今常见的HBM统一内存方案,AMD提出的是直接将计算单元与存储单元垂直堆叠在一起的3D混合键封装方案。
CPU与DRAM垂直堆叠
主流服务器性能的提升速度,已经快要赶上过去的摩尔定律了。根据AMD统计的CPU供应商数据,每过2.4年主流服务器性能就会翻一倍。可限制其继续发展的不再只是放缓的摩尔定律,还有内存上带来的限制。内存墙这样的性能瓶颈,不仅在限制CPU的性能发挥,同样限制了GPU的性能发挥。
考虑到明面上解决这个问题的主力军是存储厂商,所以提出的大部分创新方案,例如存内计算等等,也都是创造算力更高的存储器产品。苏姿丰博士也指出,从她这个处理器从业者的角度来说,这一路线有些反常理,但从系统层面来说,她也可以理解该需求存在的意义。而AMD这次提出的方案,则是从计算芯片出发,将存储器堆叠整合进去。

CPU与DRAM垂直堆叠 / AMD
从AMD给出的能量效率分析来看,DIMM这样的片外内存访问能量效率在12pj/bit左右,2.5D的HBM方案在3.5pj/bit左右,而3D垂直堆叠的键合方案却可以做到0.2pj/bit,从而利用更低的功耗来做到大带宽。况且由于计算单元和存储单元的集成度更高了,传输的延迟必然也会有显著的降低。
这套方案的出现意味着至少堆叠的内存容量足够大,服务器CPU甚至可以省去DIMM内存插槽,进一步减小空间占用。但这套方案具体能做堆叠多少内存,AMD并没有给出具体的数字,如果可堆叠的内存数量与如今的L3缓存一样仅有数百兆的话,那带来的性能提升很可能不值一提。
另外就是散热问题,从AMD给出的示意图来看,他们选择了内存单元在上,计算单元在下的方案,这种3D架构很可能会对散热产生一定负面作用,但性能损失会相对较少一些。比如MI300方案中,AMD就换成了CPU和GPU单元在上,缓存和互联在下的方案。
捆绑销售嫌疑?
在消费级领域,其实CPU与内存捆绑销售已经不是什么新鲜事了,就拿苹果的M系列芯片为例。自打苹果转向Arm阵营,推出M系列芯片后,Mac生态的定制空间就基本只存在于购买前了,虽然华强北的大神们依然能够找到一些方式来扩展固态硬盘闪存,但内存基本就与SoC彻底绑定了,用户只能忍受高昂的容量定价,才不会在高负载工作时出现内存不够用的窘境。
可在服务器市场,已经有了相当成熟的DIMM内存生态,甚至未来还有CXL内存虎视眈眈,AMD这套“捆绑销售”的方案究竟能否收获良好的市场反响我们无从得知,很明显这对内存模组厂商是存在一定威胁的。但话又说回来,AMD这套方案并没有彻底断绝扩展内存的可能性,在需要超大容量的内存池时,依然可以选择传统的扩展方案,而不是死磕堆叠内存的方案。
AMD的方案更像是给到了一个片上高速方案,从当下的工艺来看,应该还难以实现大容量的堆叠。所以在CPU上垂直堆叠DRAM,更像是AMD的另一套负载加速方案。毕竟根据苏姿丰博士的说法,AMD也很清楚现有的3D V-Cache SRAM堆叠方案只能提高特定负载的性能,DRAM堆叠方案的性能加速覆盖面无疑要更广一些。
写在最后
其实ChatGPT这样的应用出现,不仅带动了一波GPU订单量的狂飙,也让HBM、DDR5这些大带宽的内存有了用武之地,让人们终于看到了打破内存墙的应用价值,而不只是将其视为一个徒增成本的性能瓶颈。
而AMD虽然提出了将内存堆叠至CPU上的技术路线,也并没有放弃对其他方案的考量,比如他们也在和三星展开HBM2上的存算一体研究。如果AMD选择将CPU堆叠内存与存算一体结合在一起的话,或许会给其数据中心产品带来更大的优势。
AMD的存储堆叠之路
要说玩堆叠存储,AMD确实是走得最靠前的一位,例如AMD如今在消费级和数据中心级别CPU上逐渐使用的3D V-Cache技术,就是直接将SRAM缓存堆叠至CPU上。将在今年正式落地的第四代EPYC服务器处理器,就采用了13个5nm/6nm Chiplet混用的方案,最高将L3缓存堆叠至了可怕的384MB。
在消费端,AMD的Ryzen 7 5800X3D同样也以惊人的姿态出世,以超大缓存带来了极大的游戏性能提升。即将正式发售的Ryzen 9 7950X3D也打出了128MB三级缓存的夸张参数,这些产品的出现可谓打破了过去CPU厂商拼时钟频率、拼核心数的僵局,让消费者真切地感受到了额外的体验提升。
MI300 APU / AMD
GPU也不例外,虽然AMD如今的消费级GPU基本已经放弃了HBM堆叠方案,但是在AMD的数据中心GPU,例如Instinct MI250X,却依然靠着堆叠做到了128GB的HBM2e显存,做到了3276.8GB/s的峰值内存带宽。而下一代MI300,AMD则选择了转向APU方案,将CPU、GPU和HBM全部整合在一起,以新的架构冲击Exascale级的AI世代。
其实这也是AMD收购Xilinx最大的收获之一,早在十多年前Xilinx的3DIC技术也已经为多Die堆叠打下了基础。在收购Xilinx之际,AMD也提到这次交易会扩张AMD在die堆叠、封装、Chiplet和互联技术上的开发能力。在完成Xilinx的收购后,也可以看出AMD在架构上的创新有了很大的飞跃。
在近期的ISSCC 2023上,AMD CEO苏姿丰透露了他们的下一步野心,那就是直接将DRAM堆叠至CPU上。这里的堆叠并非硅中介层互联、存储单元垂直堆叠在一起的2.5D封装方案,也就是如今常见的HBM统一内存方案,AMD提出的是直接将计算单元与存储单元垂直堆叠在一起的3D混合键封装方案。
CPU与DRAM垂直堆叠
主流服务器性能的提升速度,已经快要赶上过去的摩尔定律了。根据AMD统计的CPU供应商数据,每过2.4年主流服务器性能就会翻一倍。可限制其继续发展的不再只是放缓的摩尔定律,还有内存上带来的限制。内存墙这样的性能瓶颈,不仅在限制CPU的性能发挥,同样限制了GPU的性能发挥。
考虑到明面上解决这个问题的主力军是存储厂商,所以提出的大部分创新方案,例如存内计算等等,也都是创造算力更高的存储器产品。苏姿丰博士也指出,从她这个处理器从业者的角度来说,这一路线有些反常理,但从系统层面来说,她也可以理解该需求存在的意义。而AMD这次提出的方案,则是从计算芯片出发,将存储器堆叠整合进去。
CPU与DRAM垂直堆叠 / AMD
从AMD给出的能量效率分析来看,DIMM这样的片外内存访问能量效率在12pj/bit左右,2.5D的HBM方案在3.5pj/bit左右,而3D垂直堆叠的键合方案却可以做到0.2pj/bit,从而利用更低的功耗来做到大带宽。况且由于计算单元和存储单元的集成度更高了,传输的延迟必然也会有显著的降低。
这套方案的出现意味着至少堆叠的内存容量足够大,服务器CPU甚至可以省去DIMM内存插槽,进一步减小空间占用。但这套方案具体能做堆叠多少内存,AMD并没有给出具体的数字,如果可堆叠的内存数量与如今的L3缓存一样仅有数百兆的话,那带来的性能提升很可能不值一提。
另外就是散热问题,从AMD给出的示意图来看,他们选择了内存单元在上,计算单元在下的方案,这种3D架构很可能会对散热产生一定负面作用,但性能损失会相对较少一些。比如MI300方案中,AMD就换成了CPU和GPU单元在上,缓存和互联在下的方案。
捆绑销售嫌疑?
在消费级领域,其实CPU与内存捆绑销售已经不是什么新鲜事了,就拿苹果的M系列芯片为例。自打苹果转向Arm阵营,推出M系列芯片后,Mac生态的定制空间就基本只存在于购买前了,虽然华强北的大神们依然能够找到一些方式来扩展固态硬盘闪存,但内存基本就与SoC彻底绑定了,用户只能忍受高昂的容量定价,才不会在高负载工作时出现内存不够用的窘境。
可在服务器市场,已经有了相当成熟的DIMM内存生态,甚至未来还有CXL内存虎视眈眈,AMD这套“捆绑销售”的方案究竟能否收获良好的市场反响我们无从得知,很明显这对内存模组厂商是存在一定威胁的。但话又说回来,AMD这套方案并没有彻底断绝扩展内存的可能性,在需要超大容量的内存池时,依然可以选择传统的扩展方案,而不是死磕堆叠内存的方案。
AMD的方案更像是给到了一个片上高速方案,从当下的工艺来看,应该还难以实现大容量的堆叠。所以在CPU上垂直堆叠DRAM,更像是AMD的另一套负载加速方案。毕竟根据苏姿丰博士的说法,AMD也很清楚现有的3D V-Cache SRAM堆叠方案只能提高特定负载的性能,DRAM堆叠方案的性能加速覆盖面无疑要更广一些。
写在最后
其实ChatGPT这样的应用出现,不仅带动了一波GPU订单量的狂飙,也让HBM、DDR5这些大带宽的内存有了用武之地,让人们终于看到了打破内存墙的应用价值,而不只是将其视为一个徒增成本的性能瓶颈。
而AMD虽然提出了将内存堆叠至CPU上的技术路线,也并没有放弃对其他方案的考量,比如他们也在和三星展开HBM2上的存算一体研究。如果AMD选择将CPU堆叠内存与存算一体结合在一起的话,或许会给其数据中心产品带来更大的优势。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
amd
+关注
关注
25文章
5466浏览量
134063 -
DRAM
+关注
关注
40文章
2309浏览量
183427
发布评论请先 登录
相关推荐
佰维存储发布新一代LPDDR5X内存与DDR5内存模组
近日,存储领域的领先企业佰维存储推出了其新一代高效能内存——LPDDR5X。这款内存产品采用了先进的1bnm制程工艺,相较于上一代产品,其数据传输速率有了显著提升,高达8533Mbps
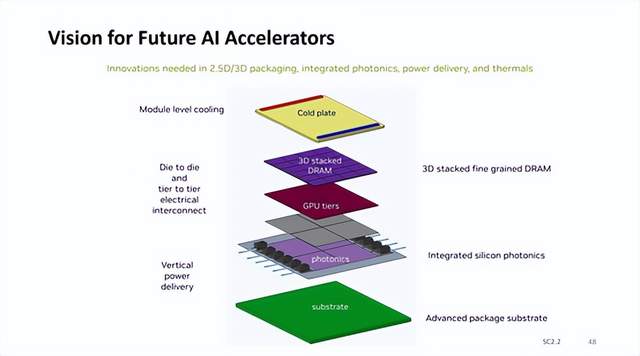
英伟达AI加速器新蓝图:集成硅光子I/O,3D垂直堆叠 DRAM 内存
加速器设计的愿景。 英伟达认为未来整个 AI 加速器复合体将位于大面积先进封装基板之上,采用垂直供电,集成硅光子 I/O 器件,GPU 采用多模块设计,3D 垂直堆叠 DRAM 内存,并在模块内直接整合
AMD发布新一代AI芯片MI325X
在旧金山举办的Advancing AI 2024大会上,AMD正式推出了其新一代AI芯片——GPU AMD Instinct MI325X。这款芯片的发布标志着AMD在人工智能领域迈出
主板自检cpu和内存灯一直来回闪
当你遇到主板自检时CPU和内存灯一直来回闪烁的情况,这通常意味着硬件检测过程中存在问题。这个问题可能涉及到多个方面,包括硬件故障、BIOS设置错误、兼容性问题等。 1. 硬件故障 1.1 CP
三星积极研发LLW DRAM内存,剑指苹果下一代XR设备市场
近日,韩媒ZDNet Korea报道,三星电子正全力投入到低延迟宽I/O(LLW DRAM)内存的研发中,旨在为未来苹果Vision Pro之后的下一代头戴式显示器(XR设备)订单做好充分准备。这
三星与海力士引领DRAM革新:新一代HBM采用混合键合技术
在科技日新月异的今天,DRAM(动态随机存取存储器)作为计算机系统中的关键组件,其技术革新一直备受瞩目。近日,据业界权威消息源透露,韩国两大DRAM芯片巨头——三星和SK海力士,都将在新一代
美光科技发布新一代GDDR7显存
在近日举行的台北国际电脑展上,美国存储芯片巨头美光科技正式发布了其新一代GDDR7显存。这款新型GPU显卡内存基于美光的1βDRAM架构,将内存
AMD重磅发布新一代AI PC芯片
AMD CEO苏姿丰于近日在台北国际电脑展(COMPUTEX)上亮相,首次发布了AMD Zen 5系列的下一代高效能运算CPU——“Ryze
超微发布新款AMD H13代CPU服务器产品
超微(Supermicro)近日宣布推出全新AMD H13代CPU服务器产品系列,再度巩固其在人工智能、云技术、存储和5G/边缘计算领域的领先地位。此次新品在性能和效率上均实现了卓越平
SK海力士HBM4E内存2025年下半年采用32Gb DRAM裸片量产
值得注意的是,目前全球三大内存制造商都还未开始量产1c nm(第六代10+nm级)制程DRAM内存颗粒。早前报道,三星电子与SK海力士预计今年内实现1c nm
华硕微星发布AGESA固件更新,确认兼容AMD新一代Ryzen处理器
近日,华硕与微星先后对 AMD 600 系列主板推出AGESA固件更新,确认了其兼容“下一代AMD Ryzen CPU”的能力;技嘉亦证实,下一代
JEDEC发布:GDDR7 DRAM新规范,专供显卡与GPU使用
三星电子和SK海力士计划在今年上半年量产下一代显卡用内存GDDR7 DRAM,这是用于图形处理单元(GPU)的最新一代高性能内存。
发表于 03-18 10:35
•705次阅读

澜起科技:DDR5第三子代RCD芯片将随新一代CPU平台规模出货
将随着支持内存速率6400MT/S的新一代服务器CPU平台的发布而开始规模出货。此外,DDR5第四子代RCD芯片的工程样片已经送样给主要的内存厂商进行评估。
深度解析HBM内存技术
HBM作为基于3D堆栈工艺的高性能DRAM,打破内存带宽及功耗瓶颈。HBM(High Bandwidth Memory)即高带宽存储器,通过使用先进封装(如TSV硅通孔、微凸块)将多个DRAM芯片进行

国产六核CPU,三屏异显,赋能新一代商显
处理器共同推出米尔MYC-YD9360核心板及开发板,赋能新一代车载智能、电力智能、工业控制、新能源、机器智能等行业发展,满足多屏的显示需求。
发表于 12-22 18:07





 工商网监
工商网监
评论