 Arm Mobile Studio 2022.4实现自动性能监控等功能
Arm Mobile Studio 2022.4实现自动性能监控等功能
Arm Mobile Studio(https://developer.arm.com/Tools%20and%20Software/Arm%20Mobile%20Studio)在过去几个版本中进行了多项增强,以支持游戏开发人员更轻松的进行性能分析。随着我们的最新版本2022.4现在可以下载,我们采取了一些大胆的举措-我们的所有专业功能现在都是免费的,所有人都可以使用。我们还考虑到新用户的体验,改进了工具的性能,并添加了分析光追内容的新功能,您可以开始测试下一代设备的性能。
以下是最新版本的一些亮点,以及今年早些时候发布的一些您可能错过的亮点。
现在所有人都可以使用专业CI功能
不再需要购买Arm Mobile Studio专业许可证才能在持续集成(CI)工作流中使用这些工具。因为我们相信所有游戏工作室都可以使用可扩展的性能分析,所以我们在免费版本中提供了所有的专业功能。
为了确保您的移动游戏拥有广泛的受众,您需要对尽可能多的设备进行性能测试。为设备群中的每个设备手动执行此操作非常耗时和昂贵。此外,您应该在整个开发过程中定期测试内容。与在发布周期结束时再修补问题相比,在出现问题时就修复问题要容易得多。
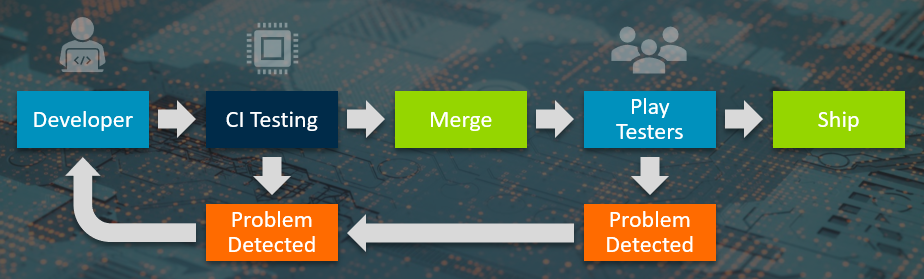
在headless模式下运行Arm Mobile Studio工具,作为连续集成系统的一部分,可以跨多个设备进行自动性能测试。每天晚上都要运行这个程序,并获得每日性能反馈,并可以跟踪性能随时间的变化。您可以将报告数据导出为CSV和JSON格式的可读文件,以便在自定义数据分析中使用。使用它可以使用任何兼容的数据库和可视化工具(如ELK堆栈)构建性能仪表板。
你可以阅读我们的教程(https://developer.arm.com/documentation/102543/latest/Overview)以帮助您进行设置。
Android版本变体支持
现在,您可以在运行“eng”或“userdebug”操作系统版本的Android设备上评测不可调试的应用程序版本。有关这些构建变体的详细信息,请参阅Android文档(https://source.android.com/docs/setup/create/new-device#build-variants)。
Arm Mobile Studio工具支持最新的Arm CPU和GPU:
-
Cortex-X3
(https://www.arm.com/products/cortex-x)
-
Cortex-A715
(https://developer.arm.com/Processors/Cortex-A715)
-
Immortalis-G715
(https://developer.arm.com/Processors/Immortalis-G715)
-
Mali-G715
(https://developer.arm.com/Processors/Mali-G715)
-
Mali-G615
(https://developer.arm.com/Processors/Mali-G615)
DWARF5调试支持
Streamline中的软件评测现在支持使用DWARF5调试格式的应用程序二进制文件。
Streamline中的Mali时间线事件
您现在可以在Streamline中监视Mali时间线事件。这有助于您确定GPU调度问题,其中non-fragment和fragment队列在整个或部分帧中串行运行。理想情况下,这两个工作负载应该重叠。如果您看到一个队列空闲而另一个处于活动状态的区域,则可能存在序列化问题。为了识别可能导致管道等待的问题,可以将计数器样本与渲染过程和计算分派相关联。有关更多信息,请参阅我们推荐的工作负载流水线(https://developer.arm.com/documentation/102521/0100)和流水线瓶颈(https://developer.arm.com/documentation/102521/0100/Pipeline-Bottlenecks)的最佳实践。
Mali时间线事件显示为时间线视图底部的自定义活动图。
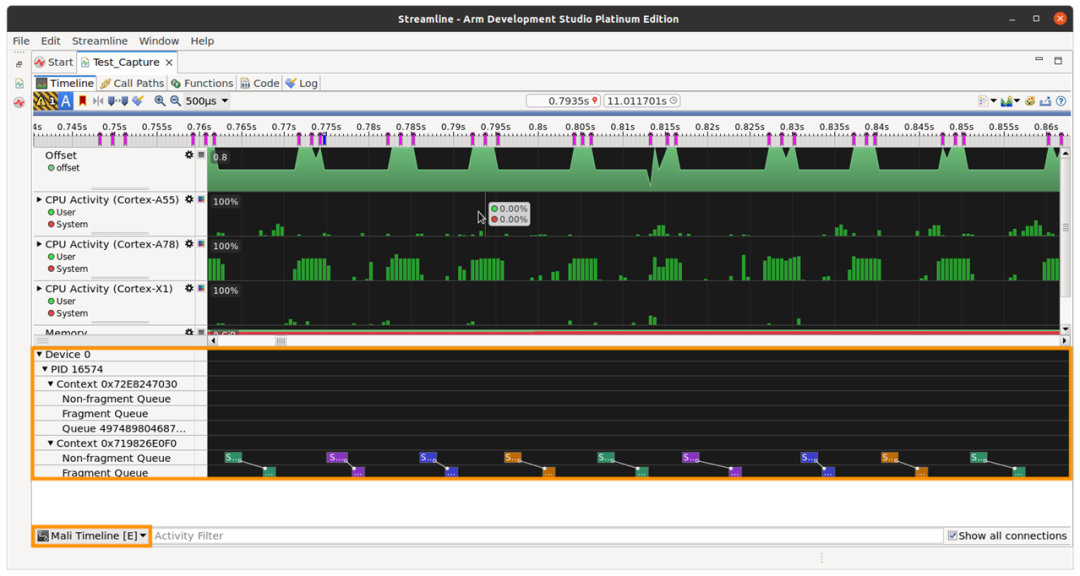
有关如何捕获Mali时间线事件的说明,请参阅Streamline用户指南(https://developer.arm.com/documentation/101816/latest/Capture-a-Streamline-profile/Counter-Configuration/Enable-Mali-Timeline-Events)。
注意:此功能需要具有Android Perfetto服务(https://perfetto.dev/)和兼容的Mali设备驱动程序版本r40p0或更高版本的Android 10设备。
性能增强
在Arm,我们明白工具的可用性至关重要。这就是为什么在每个版本中,我们都会分配一些工程时间,以使我们的工具运行得更快。这一次,对于Streamline,对于包含大量应用程序调试信息的软件配置文件,我们显著改进了分析时间和内存占用。
分析一个具有大约3GB调试信息的示例Unreal Engine项目所需的时间已从25分钟降至2.5分钟。
对于OpenGL ES和Vulkan,Performance Advisor从移动设备上运行的应用程序收集帧边界和屏幕截图数据的机制得到了显著增强。这种新的实现提高了可靠性并减少了对目标应用程序的性能影响。
注意:对于OpenGL ES应用程序,我们现在只能使用层(layer)驱动程序收集数据,这需要Android 10或更高版本。要在早期版本的Android设备上使用Performance Advisor,您需要从应用程序手动发出所需的帧边界注释。有关如何执行此操作的说明,请参阅Performance Advisor用户指南(https://developer.arm.com/documentation/102009/latest/Adding-semantic-input-to-the-reports/Send-and-include-annotations-from-application-code/Send-annotations-from-your-application-code)。
保存屏幕截图
捕获慢帧屏幕截图(目前仅限OpenGL ES)时,如果上一个屏幕截图仍在保存,Performance Advisor将跳过屏幕截图。这消除了应用程序中积压的屏幕截图导致的性能问题。此外,当在未压缩模式下运行时,屏幕截图现在保存为.bmp图像,而不是未压缩的.png图像。这将捕获和写入屏幕截图所需的时间从250毫秒减少到80毫秒以下,从而减少了对应用程序的性能影响。
Performance Advisor区域分析
如果应用程序使用区域标记(https://developer.arm.com/documentation/102009/latest/Adding-semantic-input-to-the-reports/Send-annotations-from-your-application-code)来指定感兴趣的时间区域,则这些区域在Performance Advisor的帧速率分析图表上可见。此外,每个区域的数据将单独报告。这有助于为报告提供上下文。但是,如果应用程序具有多个区域,则报告的数据可能会变得过于精细,从而使报告难以阅读。
在此版本中,如果某些区域较短或嵌套在其他区域之下,您现在可以选择从Performance Advisor报告中省略这些区域。这为您提供了对区域分析方式的更多控制。
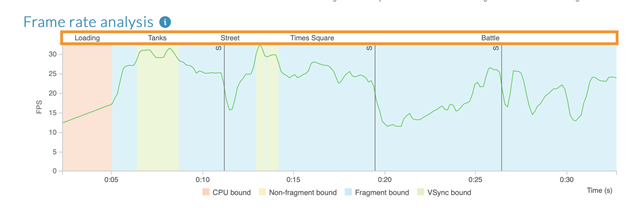
生成报告时,使用以下新的pa命令选项(https://developer.arm.com/documentation/102009/latest/Command-line-options/The-pa-command)忽略区域:----region-report-min-length=length
报告中省略给定最小长度以下的区域。
----region-report-max-depth=level
报告中省略区域层次结构中比给定级别更深的区域。
Mali脱机编译器增强功能
我们对用于着色器分析的性能报告工具Mali Offline Compiler进行了多项增强。
光线(Ray)查询性能反馈
新的Immortalis-G715在移动设备中引入了硬件加速光线跟踪(https://community.arm.com/arm-community-blogs/b/graphics-gaming-and-vr-blog/posts/developing-ray-tracing-content-for-mobile-games),同时支持Vulkan光线查询和完整光线跟踪管道。在此版本中,Mali Offline Compiler使用光线查询和所有光线跟踪管道阶段为内容提供反馈。
以下示例报告已识别出碎片着色器中的慢速光线跟踪:
Mali Offline Compiler v7.8.0 (Build aeadf0)
Copyright (c) 2007-2022 Arm Limited. All rights reserved.
Configuration
=============
Hardware: Immortalis-G715 r0p0
Architecture: Valhall
Driver: r41p0-00rel0
Shader type: Vulkan Fragment
Main shader
===========
Work registers: 64 (100% used at 50% occupancy)
Uniform registers: 10 (15% used)
Ray traversal contexts: 16 objects
Stack spilling: 32 bytes
16-bit arithmetic: 0%
A LS V T Bound
Total instruction cycles: 4.70 64.60 0.03 0.00 LS
Shortest path cycles: 0.47 19.00 0.03 0.00 LS
Longest path cycles: N/A N/A N/A N/A N/A
A = Arithmetic, LS = Load/Store, V = Varying, T = Texture
Shader properties
=================
Has uniform computation: true
Has side-effects: false
Modifies coverage: false
Uses late ZS test: false
Uses late ZS update: false
Reads color buffer: false
Has slow ray traversal: true
Note: This tool shows only the shader-visible property state.
API configuration may also impact the value of some properties.
在主着色器部分,报告显示编译器分配的光线遍历上下文的数量。每个光线查询或光线跟踪管道遍历至少需要一个遍历上下文。然而,上下文可能由具有非重叠生存期的多个遍历共享。有时,单个源查询或遍历可能需要多个上下文。多上下文遍历比单个上下文遍历慢。
着色器(shader properties)部分报告,如果着色器正在使用至少一个光线遍历,则着色器具有缓慢的光线遍历。这迫使编译器回退到较慢的多上下文遍历行为。
《Mali Offline Compiler用户指南》中添加了必须遵循的Vulkan ray查询最佳实践指南,以避免缓慢的遍历路径(https://developer.arm.com/documentation/101863/0708/Using-Mali-Offline-Compiler/Performance-analysis/Shader-properties)。
顶点着色器(Vertex Shaders)的内存分区建议
从Bifrost架构开始的Mali GPU将用户着色器分为两部分,一部分计算位置,另一部分计算所有非位置属性。在几何体剔除之前只需要位置,因此非位置属性着色器仅对可见顶点运行。为了最小化冗余内存访问,Mali 最佳实践(https://developer.arm.com/documentation/101897/latest/Vertex-shading/Attribute-layout)建议您将两个着色器所需的输入属性拆分为两个压缩流。Mali 离线编译器顶点着色器性能报告用于实现Bifrost架构或更新版本的Arm GPU,现在报告属性流的建议内存分区。
Recommended attribute streams
=============================
Position attributes
- position (location=dynamic)
Non-position attributes
- None
预期着色器核心线程占用率
Mali Offline Compiler现在报告了预期的着色器核心线程占用率以及寄存器计数。这减少了对线程占用信息参考外部数据表的需要。
Main shader
===========
Work registers: 64 (100% used at 50% occupancy)
Uniform registers: 10 (15% used)
Ray traversal contexts: 16 objects
Stack spilling: 32 bytes
16-bit arithmetic: 0%
更多Mali脱机编译器功能
以下是我们对Mali Offline Compiler的一些更新:
-
所有实现Valhall体系结构的Arm GPU的性能报告现在都报告了基于微体系结构感知成本模型的单一运算成本。使用--detailed命令行选项,每个算术指令类型的组件成本仍然可用。
-
Bifrost和Valhall架构GPU的加载/存储单位成本模型已得到改进,现在正确地反映了统一加载和堆栈访问的较低访问成本。
-
将Bifrost和Valhall架构GPU的编译器后端更新为r41p0
-
更新了Khronos glslangValidator前端,用于将GLSL源代码编译为SPIR-V IR,以支持SPIR-V 1.6功能。
-
通过指定--name命令行选项,直接从GLSL源代码编译的Vulkan着色器现在可以使用“main()”以外的入口点。
-
增加了对SPIR-V计算内核的OpenCL 3.0支持。
-
添加了过滤功能以删除性能报告中的重复编译器警告。
总结
我们希望您在这个版本中找到一些增强性能分析工作流的东西。无论您是小型独立开发人员,还是大型游戏工作室,Arm Mobile studio都具有帮助您的游戏在各种设备上表现出色的功能。通过我们的免费版,将性能分析按比例构建到您的开发工作流中现在更容易访问。性能分析现在更快了,您可以更好地控制收集的数据。
我们预计搭载最新Immortalis-G715 GPU的移动设备将于2023年上市。Mali离线编译器硬件加速光线跟踪的新功能有助于深入了解未来移动硬件如何处理光线跟踪内容。
审核编辑 :李倩
-
ARM
+关注
关注
134文章
9059浏览量
366974 -
监控
+关注
关注
6文章
2183浏览量
55114 -
应用程序
+关注
关注
37文章
3250浏览量
57630
原文标题:Arm Mobile Studio 2022.4实现自动性能监控等功能 - 极术社区
文章出处:【微信号:Ithingedu,微信公众号:安芯教育科技】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
安科瑞APM520/4G面板式物联网电表 具有全电量测量、电能统计、电能质量分析等功能
如何用zabbix监控网站性能
自动配料设备远程监控物联网解决方案
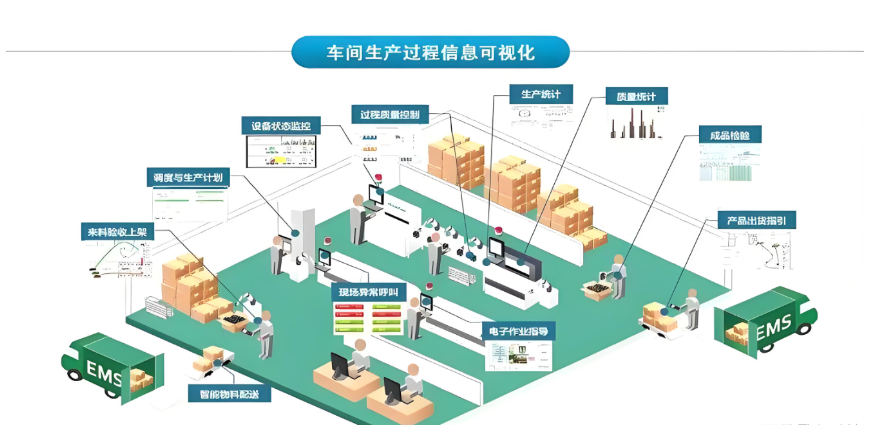
MES系统如何实现生产车间的实时监控、精准调度
监控报警系统方案Sub-1G无线收发芯片
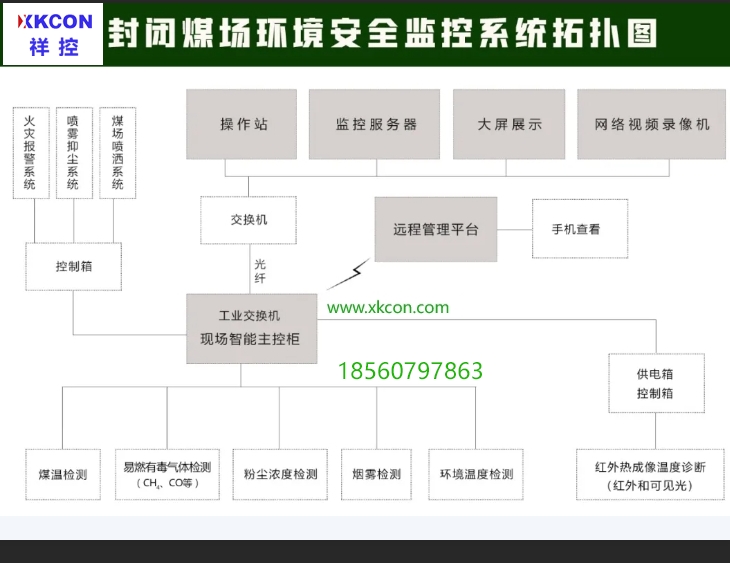
具备数据采集、储存和传输,数据处理、分析及报警,应急智能处置等功能的XKCON祥控封闭储煤场安全监测系
实现工厂自动化,工业路由器的强大功能

无线采发仪,轻松实现数据接力:NLM5xx可作为无线中继器,连接不同设备,实现数据转发、汇总等功能
基于GD32H759的嵌入式运动控制高效解决方案
无人化与自动化升级改造工程 变电站远程智能辅助监控系统
工厂设备远程监控系统是什么?工厂设备远程监控系统的功能特点
对智能家居的远程控制是如何实现的呢?哪些芯片起到主要作用?
PLC转MQTT物联网上位机监控系统如何实现
自动化PLC通过工业物联网平台实现远程监控和远程维护
直流电机性能测试系统功能特点






 工商网监
工商网监
评论