 新的数字表示方法将减轻AI数学计算负担
新的数字表示方法将减轻AI数学计算负担
训练支撑许多现代人工智能(AI)工具的大型神经网络都需要真实强大的计算能力。例如,OpenAI最先进的语言模型GPT-3训练就需要惊人的10亿亿次运算,其计算时间耗资约500万美元。工程师们认为他们已经找到了一种方法,通过使用不同的方式表示数字,进而减轻计算负担。
早在2017年,当时在A*STAR计算资源中心和新加坡国立大学就职的约翰•古斯塔夫森(John Gustafson)以及在星际机器人与电脑公司任职的艾萨克•约莫托(Isaac Yonemoto)就开发了一种新的数字表示方法。这些数字称为“posit”,他们提议将这些数字作为对目前使用的标准浮点算数处理器的改进表示。
现在,马德里康普顿斯大学的一个研究团队开发了首个可在硬件中实现posit标准的处理器内核,并表明,与使用标准浮点数字计算相比,基本计算任务的位对位(bit-for-bit)精度提高了4个数量级。他们在2022年9月的IEEE计算机算数研讨会上发表了其研究结果。
“如今,摩尔定律似乎已开始衰落。”康普顿斯大学ArTeCS小组的研究生研究员大卫•马拉森•金塔纳(David Mallasén Quintana)说,“所以我们需要找到其他方法来提高机器的性能。其中一种方法就是改变我们的实数编码方式,以及如何表示实数。”
用数字表示方法来突破极限的并非只有康普顿斯团队。早在2022年9月,Arm、英特尔和英伟达就形成了一项技术规范,在机器学习应用程序中,使用8位浮点数字替代通常的32位或16位浮点数字,即使用短小、低精度的格式,以降低计算精度为代价,提高计算效率和内存使用率。
实数不能在硬件中完美表示,因为实数的数量是无限的。为了适应指定的位数,许多实数必须四舍五入。posit的优势在于,这种方法表示数字的精度是沿着数轴分布的。在数轴中间,1和-1周围,posit表示的精度比浮点的高。在数轴两翼会逐渐出现较大的负数和正数,posit精度比浮点下降得更平稳。
古斯塔夫森说:“这与数字在计算中的自然分布相吻合。动态范围是合适的,在需要更高精度时,它的精度可以满足需求。浮点运算中有很多从来没有用过的位串,这是一种浪费。”
posit之所以能实现1和-1周围精度的提高,是因为该表示方法有一个额外组成部分。浮点数由3个部分组成:一个符号位(0为正,1为负),几个“尾数”(小数)位表示二进制小数点后面的数,其余的位用来定义指数(2exp)。
posit保留了浮点数的所有组成部分,但添加了一个额外的“regime”部分,即指数的指数。regime的优点在于它的位长度可以变化。对于较小的数字,它可以只需要2位,为尾数留下更高的精度。这样posit可以在1和-1周围的“甜蜜点”位置实现更高的精度。
深度神经网络通常使用被称为权重的归一化参数,因此它们是从posit获益的完美候选者。许多神经网络计算都由乘积累加运算组成。每次执行这种计算,每个求和都必须再次截断,导致精度损失。采用posit,一个名为quire的专用寄存器能够有效地执行累加步骤,减少精度损失。但目前的硬件应用的是浮点,而且到目前为止,在软件中使用posit带来的计算收益在很大程度上被格式转换的损耗掩盖了。

使用他们用现场可编程门阵列(FPGA)合成的新硬件,康普顿斯团队对32位浮点和32位posit的计算进行并列比较。
该团队还将结果与更精确但计算成本较高的64位浮点格式的结果进行比较,对结果的精度进行评估。对于矩阵乘法(神经网络训练中固有的一连串乘积累加)的精度,posit比浮点运算惊人地提高了4个数量级。
该团队还发现,提高精度并没有以计算时间为代价,只是芯片使用面积和功耗略有增加。
尽管提高数字精度是不可否认的,但确切地说,它对训练GPT-3等大型AI有怎样的影响还有待观察。
马拉森说:“posit可能会提高训练速度,因为在训练的过程中不会丢失太多信息。但这些事我们还不知道。有人已经在软件中试过了,现在也要在我们的硬件中试一下。”
其他团队正在研究实现自己的硬件,促进posit的使用。“这正是我所希望的,它被疯狂地接受了。”古斯塔夫森说,“posit数字格式爆火,正在使用posit的有几十个团队,公司和大学的团队都有。”
审核编辑:刘清
-
处理器
+关注
关注
68文章
19711浏览量
232711 -
人工智能
+关注
关注
1803文章
48406浏览量
244604 -
深度神经网络
+关注
关注
0文章
62浏览量
4657 -
OpenAI
+关注
关注
9文章
1195浏览量
7977
原文标题:新的数字表示方法将改进AI数学运算
文章出处:【微信号:bdtdsj,微信公众号:中科院半导体所】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
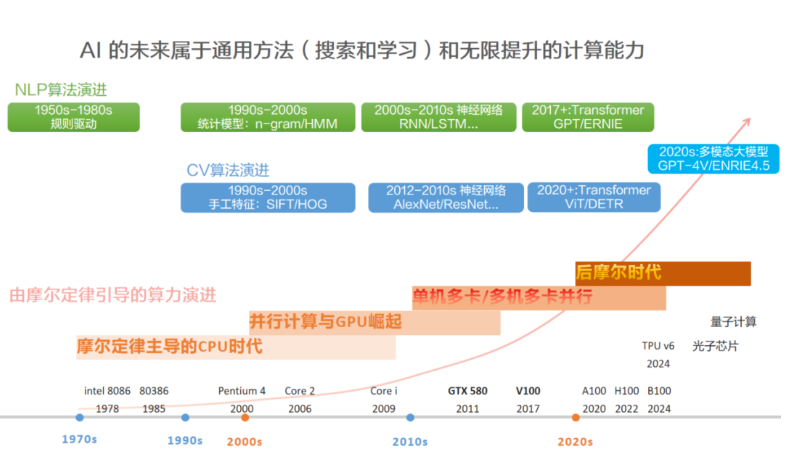
AI演进的核心哲学:使用通用方法,然后Scale Up!
(专家著作,建议收藏)电机的数学研究方法
什么是边缘计算网关?深度解析边缘计算网关的核心技术与应用场景
Banana Pi 发布 BPI-AI2N & BPI-AI2N Carrier,助力 AI 计算与嵌入式开发
贴片电感的感值代码与读取方法

数字万用表的使用方法详细图解
AI赋能边缘网关:开启智能时代的新蓝海
智慧交通AI监控视频分析应用方案

使用 AMD Versal AI 引擎释放 DSP 计算的潜力
《算力芯片 高性能 CPUGPUNPU 微架构分析》第3篇阅读心得:GPU革命:从图形引擎到AI加速器的蜕变
NVIDIA与德勤共同部署适用于医疗健康的数字AI智能体
《AI for Science:人工智能驱动科学创新》第二章AI for Science的技术支撑学习心得
数字信号包括哪些 数字信号的特点是什么
神经网络在数学建模中的应用
科学计算的下一轮创新,AI超算与数字孪生






 工商网监
工商网监
评论