 难度系数最高之堆排序简介
难度系数最高之堆排序简介
今天来看一个比较复杂的排序,堆排序,先搞清楚原理,再写代码。
堆排序使用数据结构中的堆来完成,那么问题来了,什么是堆?
有两种,大顶堆和小顶堆,所谓大顶堆,就是任意一个双亲节点都比孩子节点大,比如图上这样的,小顶堆则反过来。

所以对于大顶堆来说,根节点一定是最大的。
比如有这样一个数组,先把它画成一颗二叉树的形式,接下来就是构建大顶堆,这个部分也是整个堆排序中最耗时的部分。

从0这个节点开始,因为节点0是最后一个有孩子的节点。
0比2小,交换一下位置。

再轮到4,8和9比较,显然是9大,把9和4交换一下位置。

最后轮到3,9比2大,9和3需要交换一下位置。

注意,因为这个节点发生了变化,所以3 8 4不再满足条件,还得继续调整。8比4大,8和3交换一下位置。

这个过程就是构建大顶堆。
于是,我们得到了最大的数字9,把它和最后一个数字做交换,然后断开,意思就是后面的操作跟9没有关系了。

接下来就是调整大顶堆,不需要再像刚才那样构建,因为这颗二叉树也只有根节点被修改了。
0和8交换,4和0交换,又得到了第二大的数字8。

不断的重复,最后就是一个有序的序列。
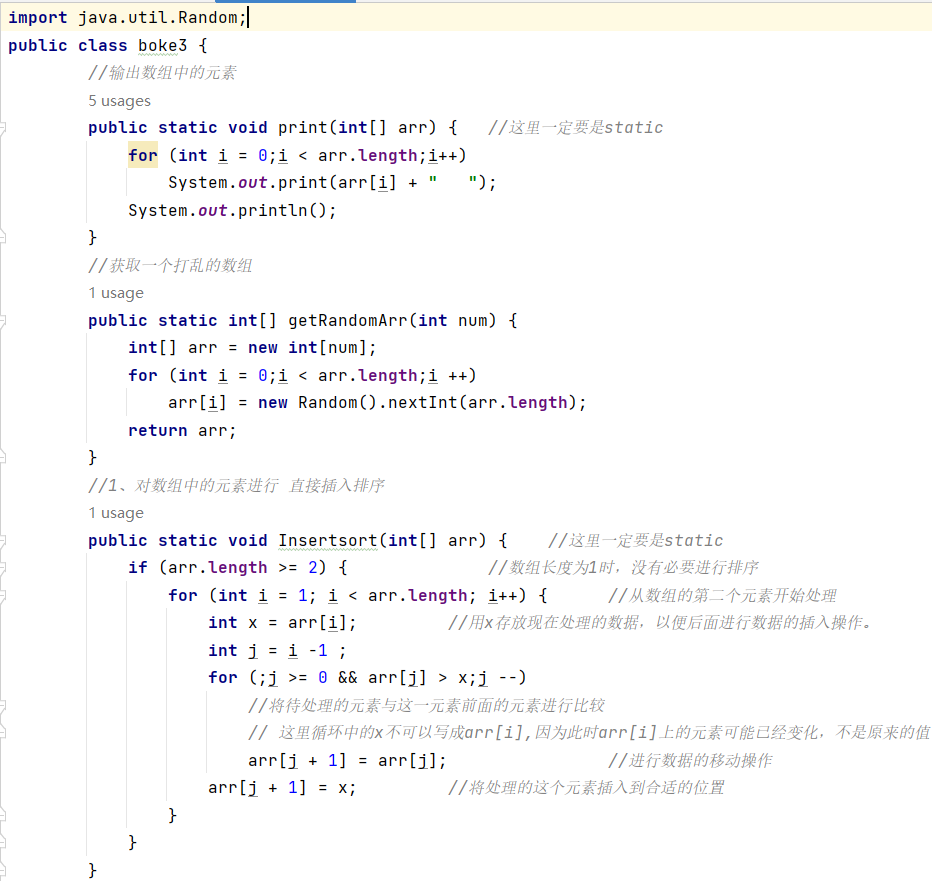
写代码之前,还得明确一个问题,虽然我们一直在操作二叉树,但是写代码的时候并不需要真的去创建一颗二叉树,我们只是在操作数组的下标,比如下标为n的节点作为根几点,那么他的左孩子就是 2n+1,右孩子就是2n+2。
#include代码确实不太容易理解,不过在这些排序算法中,越是不容易理解的,效率也就越高,还是用它和冒泡做个对比,10000个数据,差距还是很大的。void adjust_heap_sort(int *a, int root, int last) { int child; while (1) { child = 2 * root + 1; if (child > last) break; if (child + 1 <= last && a[child] < a[child + 1]) { child++; } if (a[child] > a[root]) { int num = a[root]; a[root] = a[child]; a[child] = num; } root = child; } } void heap_sort(int *a, int size) { //构建大顶堆 for (int i = size / 2 - 1; i >= 0; i--) { adjust_heap_sort(a, i, size - 1); } //调整大顶堆 for (int i = size - 1; i > 0; i--) { int num = a[0]; a[0] = a[i]; a[i] = num; adjust_heap_sort(a, 0, i - 1); } } int main() { int array[] = {3, 4, 0, 8, 9, 2}; heap_sort(array, 6); for (int i = 0; i < sizeof(array) / sizeof(array[0]); i++) { printf("%d ", array[i]); } printf(" "); return 0; }
root@Turbo:test# time ./heap_sort real 0m0.005s user 0m0.004s sys 0m0.000s root@Turbo:test# time ./bubble_sort real 0m0.606s user 0m0.554s sys 0m0.000s root@Turbo:test#
审核编辑:刘清
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
交换机
+关注
关注
21文章
2700浏览量
100937 -
二叉树
+关注
关注
0文章
74浏览量
12510
原文标题:难度系数最高-堆排序
文章出处:【微信号:学益得智能硬件,微信公众号:学益得智能硬件】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
排序算法之选择排序
选择排序: (Selection sort)是一种简单直观的排序算法,也是一种不稳定的排序方法。 选择排序的原理: 一组无序待排数组,做升序排序
c语言排序算法之选择排序法
应广大"鸟友"强烈要求,小编将会推出《排序系列》,给大家讲讲排序那些事。 那么今天首先给大家讲解最符合人类思维逻辑的超简单排序法☞《选择排序法》。 顾名
发表于 11-16 10:25
•3497次阅读
几种c语言程序的排序包括应用程序等资料免费下载
本文档的主要内容详细介绍的是几种c语言程序的排序包括应用程序好资料免费下载包括了:堆排序,改进冒泡排序,归并排序,简单插入排序,简单选择
发表于 09-29 08:00
•6次下载
C语言排序中堆排序的技巧
调整,使得子节点永远小于父节点 创建最大堆(Build Max Heap):将堆中的所有数据重新排序 堆排序(HeapSort):移除位在第一个数据的根节点,并做最大堆调整的递归运算。 C代码实现 代码看起来比较抽象,将代码运行时数据交换的过程打印出来,然后

解析数据结构的常用七大排序算法
为了让大家掌握多种排序方法的基本思想,本篇文章带着大家对数据结构的常用七大算法进行分析:包括直接插入排序、希尔排序、冒泡排序、快速排序、简单





 工商网监
工商网监
评论