 AI大模型带来改变,将加速通用人工智能的实现!
AI大模型带来改变,将加速通用人工智能的实现!
电子发烧友网报道(文/李弯弯)近日,百度飞桨总架构师于佃海公开谈到,AI预训练大模型是深度学习崛起以来,最重要的一次技术变革。
大模型不只是模型参数规模大,同时也对应着学习机制和AI开发应用范式的改变。自监督学习模式突破了数据标注的困境,可以从海量数据中学习到丰富的通用知识。
基于大模型,只需要通过模型的微调或提示等方式,就可以在广泛的下游任务中取得优异的效果,极大的降低了AI开发和应用的成本。
大语言模型的涌现能力
在自然语言处理领域,过去这些年模型的规模越来越多。之前模型参数大概在千万级别、亿级别,现在已经跳到了千亿级别。基本上游研究这些大模型的使一些计算资源比较丰富的企业和机构,有了这些预训练模型之后,下游可以把它放在一些自然语言处理的任务中。
在全球人工智能开发者先锋大会上,复旦大学计算机学院教授邱锡鹏在《ChatGPT能力分析与应用》主题演讲中表示,大型语言模型是ChatGPT的基座。
邱锡鹏教授谈到,当模型从小规模发展到大规模的时候,当发展到一定阶段,它会涌现出一些之前在小模型上观测不到的能力,也就是大家说的能力涌现。比如给几个样例,让模型学习这个任务,一个百亿级别参数规模的模型和一个千亿级别参数的模型,这两个模型的能力差异会相当大,邱锡鹏教授认为,从百亿到千亿参数规模,模型发生了能力的突变。
考察大模型的几个能力:数学建模能力、多任务理解的能力、上下文的学习理解能力,在百亿规模之后,就会发生突变。它的能力不再是线性增长。
模型使用的方式也发生了变换,因为有了大模型之后,调参非常难,它的使用范式也会发生变化。比如,早期使用预训练,调它的参数;现在语言模型很大的时候,要做什么任务,就是提示,告诉它要做什么,变成了另外一种使用范式。
举个例子,我们把要完成的任务,用一句话描述出来,输入给语言模型,语言模型就按产生下一句话的方式,生成你要的答案。这就是大型语言模型的使用方式。邱锡鹏教授认为,在Transformer这种架构下,大型语言模型标志性的分水岭是百亿规模参数。
以ChatGPT为例,在大模型下,ChatGPT涌现出的三种能力:情景学习、思维链和指令学习。这三个能力对ChatGPT最终的成功起到了重要作用。
情景学习:大模型调参不是很方便,如果要它在一个上下文语境中完成学习,这就叫情景学习。也就是给它一个任务,再给它几个例子,让它学习。情景学习赋予了大模型非常强的交互能力,情景学习也可以大幅降低下游的开发成本。
思维链:思维链的关键是打破了Scaling Law,一般而言,模型规模的放大通常会带来能力的提升。而思维链的出现,使得在一定规模之后,可以通过思维链继续放大模型的能力,而不需要进一步扩大参数规模。
指令学习:大模型达到一定规模之后,只需要给它少数的指令,它就学会了,对于没见过的指令,它也会。这些就是大模型的涌现能力,它的泛化能力会变得非常强。
文图生成主要技术路线
在ChatGPT出现之前,大模型最火的应用就是AI作画,也就是文图生成。事实上,文图生成技术从2015年到现在,一直在不断演进。据百度深圳自然语言处理部技术总监何径舟在上述大会上介绍,这之间,文图生成技术大概经历了三个技术流派。
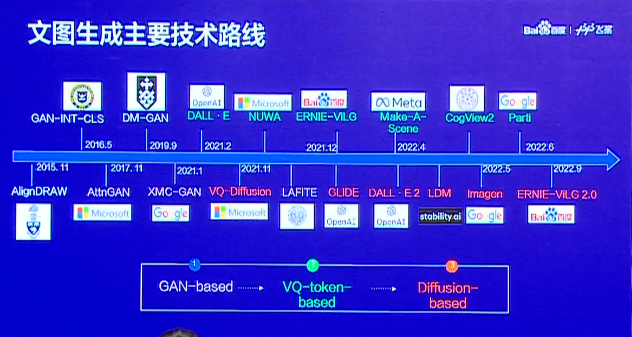
第一个是以对抗生成网络GAN-based为主的早期技术;第二个是序列生成 VQ-token-based这种方式 ;第三个是从去年开始大热的Diffusion-based扩散网络这种方案。现在常见的、在很多产品中使用的,都是这三个技术流派的延续或结合。
基于GAN的文本-图像生成模型,是四五年前最火的文图生成技术。它的优点是,整个模型的生成过程很快,在当时来看,生成的图像质量相当不错;然而它致命的缺点是,网络特别难训练,稍不小心就会训练坏,或者难以得到理想的效果。因此在之后的工作中,大家就不太实用了。
基于图像量化的序列建模。它是把图像基于离散化的方式,压缩成离散视觉token的序列,这样可以跟文本用类似的方式基于Transformer自回归生成,建模文本序列和图像序列间的关系。通过这样的方式,做文图转换,也可以做图像文本的生成。何径舟表示,文心大模型ERNIE-ViLG第一个版本就是基于VQ-token-based这种方式做的,在当时ERNIE-ViLG能够完成双向的生成和建模。
基于扩散模型的文本-图像生成模型,是现在文图生成技术的主流。它是把一个图像通过加高斯噪声的方式,一直到纯随机序列高斯噪音的分布。再通过UNet,不断反复调用它,把这个图像还原回来。这时候可以把文本的encoder加进去,指导图像还原过程。这样就实现了从文本到图像的生成过程。这是现在绝大多数最新产品和技术都采用的方案,效果非常好。
小结
过去这些年,国内外在大模型技术的研究方面不断取得突破,最近ChatGPT的出现及其体现出的惊人能力,更是让人们体会到了大模型对于人工智能发展的重要意义。从种种迹象来看,叠加情景学习、指令微调、人类反馈、强化学习等机制,可以使大模型实现超出想象的能力涌现,让人们期待的通用人工智能的实现加速。
大模型不只是模型参数规模大,同时也对应着学习机制和AI开发应用范式的改变。自监督学习模式突破了数据标注的困境,可以从海量数据中学习到丰富的通用知识。
基于大模型,只需要通过模型的微调或提示等方式,就可以在广泛的下游任务中取得优异的效果,极大的降低了AI开发和应用的成本。
大语言模型的涌现能力
在自然语言处理领域,过去这些年模型的规模越来越多。之前模型参数大概在千万级别、亿级别,现在已经跳到了千亿级别。基本上游研究这些大模型的使一些计算资源比较丰富的企业和机构,有了这些预训练模型之后,下游可以把它放在一些自然语言处理的任务中。
在全球人工智能开发者先锋大会上,复旦大学计算机学院教授邱锡鹏在《ChatGPT能力分析与应用》主题演讲中表示,大型语言模型是ChatGPT的基座。
邱锡鹏教授谈到,当模型从小规模发展到大规模的时候,当发展到一定阶段,它会涌现出一些之前在小模型上观测不到的能力,也就是大家说的能力涌现。比如给几个样例,让模型学习这个任务,一个百亿级别参数规模的模型和一个千亿级别参数的模型,这两个模型的能力差异会相当大,邱锡鹏教授认为,从百亿到千亿参数规模,模型发生了能力的突变。
考察大模型的几个能力:数学建模能力、多任务理解的能力、上下文的学习理解能力,在百亿规模之后,就会发生突变。它的能力不再是线性增长。
模型使用的方式也发生了变换,因为有了大模型之后,调参非常难,它的使用范式也会发生变化。比如,早期使用预训练,调它的参数;现在语言模型很大的时候,要做什么任务,就是提示,告诉它要做什么,变成了另外一种使用范式。
举个例子,我们把要完成的任务,用一句话描述出来,输入给语言模型,语言模型就按产生下一句话的方式,生成你要的答案。这就是大型语言模型的使用方式。邱锡鹏教授认为,在Transformer这种架构下,大型语言模型标志性的分水岭是百亿规模参数。
以ChatGPT为例,在大模型下,ChatGPT涌现出的三种能力:情景学习、思维链和指令学习。这三个能力对ChatGPT最终的成功起到了重要作用。
情景学习:大模型调参不是很方便,如果要它在一个上下文语境中完成学习,这就叫情景学习。也就是给它一个任务,再给它几个例子,让它学习。情景学习赋予了大模型非常强的交互能力,情景学习也可以大幅降低下游的开发成本。
思维链:思维链的关键是打破了Scaling Law,一般而言,模型规模的放大通常会带来能力的提升。而思维链的出现,使得在一定规模之后,可以通过思维链继续放大模型的能力,而不需要进一步扩大参数规模。
指令学习:大模型达到一定规模之后,只需要给它少数的指令,它就学会了,对于没见过的指令,它也会。这些就是大模型的涌现能力,它的泛化能力会变得非常强。
文图生成主要技术路线
在ChatGPT出现之前,大模型最火的应用就是AI作画,也就是文图生成。事实上,文图生成技术从2015年到现在,一直在不断演进。据百度深圳自然语言处理部技术总监何径舟在上述大会上介绍,这之间,文图生成技术大概经历了三个技术流派。
第一个是以对抗生成网络GAN-based为主的早期技术;第二个是序列生成 VQ-token-based这种方式 ;第三个是从去年开始大热的Diffusion-based扩散网络这种方案。现在常见的、在很多产品中使用的,都是这三个技术流派的延续或结合。
基于GAN的文本-图像生成模型,是四五年前最火的文图生成技术。它的优点是,整个模型的生成过程很快,在当时来看,生成的图像质量相当不错;然而它致命的缺点是,网络特别难训练,稍不小心就会训练坏,或者难以得到理想的效果。因此在之后的工作中,大家就不太实用了。
基于图像量化的序列建模。它是把图像基于离散化的方式,压缩成离散视觉token的序列,这样可以跟文本用类似的方式基于Transformer自回归生成,建模文本序列和图像序列间的关系。通过这样的方式,做文图转换,也可以做图像文本的生成。何径舟表示,文心大模型ERNIE-ViLG第一个版本就是基于VQ-token-based这种方式做的,在当时ERNIE-ViLG能够完成双向的生成和建模。
基于扩散模型的文本-图像生成模型,是现在文图生成技术的主流。它是把一个图像通过加高斯噪声的方式,一直到纯随机序列高斯噪音的分布。再通过UNet,不断反复调用它,把这个图像还原回来。这时候可以把文本的encoder加进去,指导图像还原过程。这样就实现了从文本到图像的生成过程。这是现在绝大多数最新产品和技术都采用的方案,效果非常好。
小结
过去这些年,国内外在大模型技术的研究方面不断取得突破,最近ChatGPT的出现及其体现出的惊人能力,更是让人们体会到了大模型对于人工智能发展的重要意义。从种种迹象来看,叠加情景学习、指令微调、人类反馈、强化学习等机制,可以使大模型实现超出想象的能力涌现,让人们期待的通用人工智能的实现加速。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
AI
+关注
关注
87文章
31151浏览量
269479 -
大模型
+关注
关注
2文章
2491浏览量
2867
发布评论请先 登录
相关推荐
嵌入式和人工智能究竟是什么关系?
与人工智能的结合,无疑是科技发展中的一场革命。在人工智能硬件加速中,嵌入式系统以其独特的优势和重要性,发挥着不可或缺的作用。通过深度学习和神经网络等算法,嵌入式系统能够高效地处理大量数据,从而
发表于 11-14 16:39
《AI for Science:人工智能驱动科学创新》第6章人AI与能源科学读后感
幸得一好书,特此来分享。感谢平台,感谢作者。受益匪浅。
在阅读《AI for Science:人工智能驱动科学创新》的第6章后,我深刻感受到人工智能在能源科学领域中的巨大潜力和广泛应用。这一章详细
发表于 10-14 09:27
AI for Science:人工智能驱动科学创新》第4章-AI与生命科学读后感
。
4. 对未来生命科学发展的展望
在阅读这一章后,我对未来生命科学的发展充满了期待。我相信,在人工智能技术的推动下,生命科学将取得更加显著的进展。例如,在药物研发领域,AI技术将帮助
发表于 10-14 09:21
《AI for Science:人工智能驱动科学创新》第二章AI for Science的技术支撑学习心得
非常高兴本周末收到一本新书,也非常感谢平台提供阅读机会。
这是一本挺好的书,包装精美,内容详实,干活满满。
关于《AI for Science:人工智能驱动科学创新》第二章“AI
发表于 10-14 09:16
《AI for Science:人工智能驱动科学创新》第一章人工智能驱动的科学创新学习心得
,无疑为读者铺设了一条探索人工智能(AI)如何深刻影响并推动科学创新的道路。在阅读这一章后,我深刻感受到了人工智能技术在科学领域的广泛应用潜力以及其带来的革命性变化,以下是我个人的学习
发表于 10-14 09:12
名单公布!【书籍评测活动NO.44】AI for Science:人工智能驱动科学创新
!
《AI for Science:人工智能驱动科学创新》 这本书便将为读者徐徐展开AI for Science的美丽图景,与大家一起去了解:
人工智能究竟帮科学家做了什么?
发表于 09-09 13:54
报名开启!深圳(国际)通用人工智能大会将启幕,国内外大咖齐聚话AI
8月28日至30日,2024深圳(国际)通用人工智能大会暨深圳(国际)通用人工智能产业博览会将在深圳国际会展中心(宝安)举办。大会以“魅力AI·无限未来”为主题,致力于打造全球通用人工智能
发表于 08-22 15:00
阿丘科技成功入选“北京市通用人工智能产业创新伙伴计划”,AI+工业视觉实力再获肯定
成式AI技术、垂直行业视觉大模型等创新探索,成功入选“应用伙伴”。聚焦AI+工业场景,入选应用伙伴“北京市通用人工智能产业创新伙伴计划”由北京市经济和信息化局、北京

千方科技成功入选“北京市通用人工智能产业创新伙伴计划”
日前,“2024全球数字经济大会人工智能专题论坛”在京举办,会上正式发布了新一批“北京市通用人工智能产业创新伙伴计划”成员名单(以下简称“伙伴计划”)。千方科技凭借在交通、物联、城市治理等关键场景中

人工智能模型有哪些
人工智能(Artificial Intelligence, AI)作为21世纪最具影响力的技术之一,正以前所未有的速度改变着我们的生活、工作乃至整个社会结构。AI
九章云极DataCanvas公司入选北京市通用人工智能产业创新伙伴计划
作为北京市标杆人工智能企业,九章云极DataCanvas公司将持续发挥产业优势,继续坚持将自主创新的AI技术注入产业,以大模型应用为终极服务目标,通过包括大

大模型应用之路:从提示词到通用人工智能(AGI)
铺平道路。 基于AI大模型的推理功能,结合了RAG(检索增强生成)、智能体(Agent)、知识库、向量数据库、知识图谱等先进技术,我们向实现真正的AGI(
嵌入式人工智能的就业方向有哪些?
。 国内外科技巨头纷纷争先入局,在微软、谷歌、苹果、脸书等积极布局人工智能的同时,国内的BAT、华为、小米等科技公司也相继切入到嵌入式人工智能的赛道。那么嵌入式AI可就业的方向有哪些呢? 嵌入式
发表于 02-26 10:17





 工商网监
工商网监
评论