 如何改进8051微控制器创建可执行高达33MIP的高性能直接替代品
如何改进8051微控制器创建可执行高达33MIP的高性能直接替代品
本文介绍了达拉斯半导体如何改进传统的8051微控制器,创建可执行高达33MIP的高性能直接替代品。多个数据指针、扩展内存寻址(高达 16MB)和闪存等附加功能提高了设备的速度和实用性。
系统设计人员知道,微控制器是任何嵌入式系统的核心,而这正是行动发生的地方。ADI公司的全资子公司达拉斯半导体一直在重新定义无处不在的8051微控制器。也许过去10年中最大的改进是在指令执行速度方面。我们的 1 个机器周期时钟处理器达到了一个非凡的性能目标 — 每个机器周期 1 个时钟,目前为每秒 33 万条指令 (MIPS)。利用这一内核,我们的安全、联网和混合信号 8051 微控制器系列继续为功能集成和创新设定标准。
为什么基于古老的 8051 指令集构建一系列创新微控制器?因为,很简单,它是世界上最受欢迎的8位微控制器架构之一。该指令集易于理解,使其成为嵌入式系统设计人员的最爱。许多指令直接针对I/O引脚,允许快速操作(位敲击)外部外设。片上外设种类繁多,组合数量几乎不受限制。此外,8051微控制器系列的开发工具广泛可用,因此开始开发应用既简单又便宜。
安全可靠
1987年,达拉斯半导体/模拟公司推出了DS5000T,这是一款基于8051指令和功能集的独立开发的微控制器。为了提供新的功能和优势,我们的工程师基于NV SRAM技术而不是EPROM进行设计。凭借其在低功耗技术方面的领先地位,存储器分区和电池备份电路直接集成到微控制器芯片上。该系统的主要优点是速度。写入大多数非易失性存储器的速度很慢,但NV SRAM可以在单个周期内高速读取或写入。这使其成为必须实时捕获数据的高速、非易失性数据记录应用的理想选择。当与外部SRAM和电池结合使用时,结果是一个完整的微控制器系统,具有高达64kB的非易失性程序和数据存储器。
NV SRAM技术使数据和程序存储器能够在系统内逐字节动态重新编程。在标准微控制器系统中,程序存储器需要从系统中物理移除(EPROM)或块擦除,从而禁止在擦除(闪存)期间访问存储器。基于NV SRAM的微控制器可以通过其串行端口从PC或设备编程器快速轻松地进行编程。驻留在ROM中的自举加载程序将程序和数据直接下载到微控制器,从而实现快速调试或现场升级。
NV SRAM的独特优势为固件安全提供了新的视角。由于引导加载程序完全控制程序加载到 NV SRAM 中,因此我们使用 40 位或 80 位加密密钥对地址和数据总线进行了加密。加载到微控制器中的任何程序或数据在存储在SRAM中之前都会自动加密。这种加密可以阻止黑客窃取微控制器中的程序或数据。在执行指令期间,微控制器获取加密的操作码,在单个机器周期内解密并执行它。使用NV SRAM允许全速读/写访问,指令解码没有延迟。
这些安全特性最终形成了DS5250,这是一款用于全球金融终端和支付系统的安全8051微控制器。这些防篡改响应微控制器集成了每机器周期 4 个时钟的 8051 内核,并对其程序存储器进行了增强的三重 DES 加密。通过添加入侵检测输入和片上篡改传感器,可自动擦除存储器作为篡改响应,进一步增强了安全性。一体式微探头屏蔽层可防止芯片篡改。同样,NV SRAM最适合高安全性应用。其高速写入时序允许微处理器比任何其他类型的存储器更快地擦除机密或敏感数据。
DS5250是唯一能够提供最高安全性同时全速执行每条指令的微控制器。
更快的速度,更低的功率
尽管 8051 处理内核从 1970 年代后期到 1980 年代的概念一直保持静止,但嵌入式系统却没有。系统设计人员通过添加新的软件功能和外设,继续改进和升级其基于 8051 的应用程序。这种“功能蠕变”突破了可用 8051 性能的极限。不幸的是,8051内核的改进未能跟上步伐,系统设计人员似乎不得不切换到另一个处理器并执行昂贵的重新设计来升级他们的系统。
性能瓶颈是 1970 年代 8051 微控制器的老式处理内核。尽管外部晶体速度接近40MHz,但传统的8051仍然需要12个时钟来执行单个机器周期。每条指令需要 1 到 4 个机器周期,这意味着一条指令可能需要少至 12 个或多达 48 个振荡器时钟。因此,吞吐量被限制在略高于 3 MIPS,即使在执行一串 1 周期 NOP 指令这样基本的东西时也是如此(图 1)。
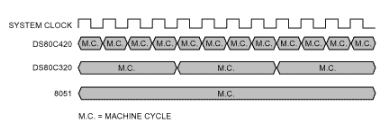
图1.减少每个机器周期的时钟数量可以在相同的指令集下实现 3 倍的性能(每个机器周期 12 对 4 对 1 个时钟)。
1991 年,我们着手重新设计 8051 微控制器以提高性能。工程团队首先分析了传统的 8051 设计。最初的每台机器周期 12 个时钟架构非常浪费;大多数指令被迫执行虚拟循环。工程师从头开始重建 CPU,使其每个机器周期只需要 4 个时钟,而不是 12 个。第二条内部数据总线消除了可能影响性能的架构瓶颈。高功率 I/O 驱动器提高了外部存储器操作期间的开关速度。所有内部外围设备(如定时器和串行端口)都以更快的时钟速度运行。但每一步都有一个绝对必要性——指令集必须与 8051 指令集保持操作码兼容。
结果呢?基于 8051 的新型微控制器的效率是原始 8051 内核的三倍,在相同的振荡器频率下,大多数指令的运行速度提高了三倍。除了内核效率的提高外,大多数器件的最大外部振荡器频率增加到33MHz或40MHz。系统设计人员以前受到较旧、速度慢得多的 8051 的阻碍,无需更改软件即可将系统升级到 10 MIPS 的最高速度。
除了速度改进之外,内核重新设计还带来了另一个好处:降低功耗。物理定律规定,数字电路消耗的功率与开关晶体管的数量和开关速率(频率)成正比。由于新内核每个机器周期使用的振荡器时钟更少,因此与传统的 8051 相比,它每秒每条指令消耗的功率要少得多。
电源管理模式通过使用软件可配置的内部时钟分频器暂时降低了微控制器的功耗。通过将机器循环速率从每个机器循环 4 个时钟降低到每个机器周期 64 或 256 个时钟,进一步降低了功耗。回切功能允许器件在收到外部中断或检测到串行端口起始位时返回到4分频模式。这使得器件能够保持低功耗状态,但在需要时可以快速恢复全速运行。图2显示了不同模式下的相对功耗。
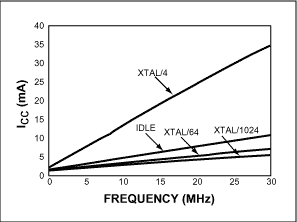
图2.在活动减少期间,我们的电源管理模式消耗的电流比空闲模式少,但仍允许 CPU 运行。
33 MIPS 及以上
1997年,达拉斯半导体/模拟公司开始设计终极性能的内核。基于 8051 的应用程序不断发展,客户要求更高的性能。工程团队将目光投向了性能峰值:一个执行 8051 指令集但每台机器周期仅使用 1 个时钟的微控制器。使用高度并行的架构和新的制造工艺,设计了一种引脚对引脚的直接替代品 8051。
其结果是新型DS89C430/DS89C450,超高性能每机器周期1时钟微控制器,能够执行高达33 MIPS(图3)。这些器件打破了以前的性能障碍,以 16 位价格提供 8 位微控制器性能。各种总线寻址模式允许用户根据特定应用设计的需要微调处理器操作。但最重要的是,它们仍然与 100 指令集 8051% 兼容,并且仍然比任何其他基于 8051 的微控制器更快地执行现有的 8051 应用。
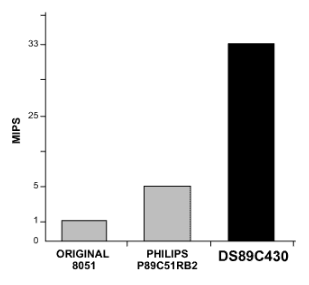
图3.DS89C430的时钟频率为33 MIPS,超越了竞争对手。
除了闪电般的内核外,DS89C430/DS89C450还集成了高达64kB的系统内可编程闪存。基于ROM的自举加载器允许在最终组装之前、期间或之后修改微控制器代码,从而提供最大的灵活性。与其他使用专有或非标准接口的微控制器不同,DS89C430自举加载程序可通过其串行端口从标准PC访问,使用任何终端仿真器软件。
快速执行时间乞求更大的程序规模
如果程序员没有足够的内存地址空间来存储他们的表达式,那么速度的优势就会丧失。传统的8051使用16位内存总线,将内存范围限制为64kB。对于某些应用程序,这种有限的内存范围就足够了。但随着应用程序代码大小和复杂性的增加,我们意识到应用程序需要一种尽可能保持 8051 兼容性的解决方案。
一些设计人员发现,通过使用组交换技术可以扩展寻址范围。I/O 线兼作地址线,以牺牲外设 I/O 为代价扩展内存。但这有两个主要缺点。首先,必须将代码分割成 64kB 或更小的块,这是一项耗时的任务,每次修改代码时都必须重做。其次,必须编写软件例程,以便在每次代码在段之间转换时手动将 I/O 行切换到适当的状态。与这些工作相关的软件开销会降低性能。
更好的解决方案是实现具有更大地址总线的设备,该总线可寻址更多内存。DS80C400具有24位地址总线,可直接寻址16MB程序存储器和16MB数据存储器。这不需要在 8051 指令集中使用任何新的操作码即可完成。提供两种模式。第一种是分页寻址模式,它结合了先进的自动库切换,大大加快了扩展内存访问的速度,同时保持与传统 8051 编译器的二进制兼容。第二种连续模式允许对整个 16MB 内存映射进行透明寻址,并且需要一个编译器来提供 24 位地址所需的额外操作数。更大的地址空间允许更快地访问更大的程序,开辟了新的可能性,如大型数学函数库、查找表,甚至Java™虚拟机,由网络微控制器支持,包括执行模拟微型网络接口(MxTNI™)运行时环境的DS80C390和DS80C400。
每一步都有一个绝对必要性——指令集必须与 8051 指令集保持操作码兼容。
数据指针性能翻倍
有必要对芯片的各个方面进行深远的改进,以避免产生性能瓶颈。最重要的改进涉及访问MOVX数据存储器。在原始8051上操纵数据存储器是一件繁琐的事情。在读取或写入目标地址之前,访问MOVX存储器的单个字节需要多个周期来加载单个16位数据指针。
DS89C430保持100%8051指令集兼容性,因此它执行现有8051应用的速度仍然比任何其他基于8051的微控制器快。
如果软件需要执行块复制操作,则效率低下会成倍增加,这涉及将数据从一个MOVX内存位置移动到另一个MOVX内存位置。单个数据指针限制迫使它在块复制操作中兼作源地址和目标地址。传统 8051 微控制器上的操作是一个复杂的多步骤过程:
将源地址加载到数据指针中。
递增或修改指向下一个基准的数据指针。
将数据从MOVX存储器获取到累加器中。
将修改后的源地址保存到存储寄存器。
将目标地址加载到数据指针中。
递增或修改指向下一个基准的数据指针。
将数据从累加器写入 MOVX 内存。
将修改后的目标地址保存到存储寄存器。
较大的地址空间允许更快地访问更大的程序,例如网络微控制器支持的 Java 虚拟机。
人们很快注意到,上述过程中几乎一半的步骤专门用于在单个数据指针中处理源地址和目标地址,这会影响整体性能。该解决方案添加了第二个数据指针,为源和目标创建专用寄存器。使用第二个数据指针,大部分数据操作可以在硬件中处理,从而减少软件开销。双数据指针可单独寻址,专用数据指针选择位指示MOVX指令期间哪个数据指针是活动数据指针。使用双数据指针执行相同的块复制操作所需的步骤要少得多。
仅执行一次初始化:
将源地址初始化为第一个数据指针。
将目标地址初始化为第二个数据指针。
主循环:
将数据提取到累加器中。
递增或修改指向下一个源基准的第一个数据指针。
将数据指针选择器切换到第二个数据指针。
将数据从累加器写入 MOVX 内存。
递增或修改指向下一个基准的数据指针。
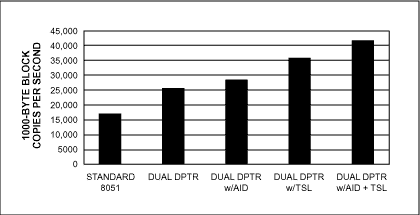
图4所示为1000MHz DS33C89上的430字节块复制例程,当双数据指针消除了处理单个数据指针的相关开销时,执行时间减少了33%。高速和超高速微控制器系列的一些成员还具有额外的可选数据指针增强功能。自动递增/递减功能(在图4中表示为AID)根据MOVX相关指令自动递增或递减数据指针,无需INC DPTR指令。自动切换功能(在图4中表示为TSL)在MOVX相关指令之后自动切换活动数据指针,消除了在数据指针之间切换的指令。图 4 显示了将所有这些功能一起考虑时的相对执行时间。请注意,启用所有功能后,DS89C430执行1000字节块复制程序的速度比原来的103微处理器快8051%。

图4.双数据指针增强功能可提高块复制操作的速度。
展望未来
随着应用对速度的要求越来越高,模拟越来越努力地超越以前的性能设计。无论是更快的堆栈访问、扩展寻址,还是原始处理速度,我们的微控制器设计都能继续满足嵌入式系统设计人员的需求。
但有竞争力的设计需要的不仅仅是速度。更复杂的应用需要更大的程序,因此我们正在扩展我们的嵌入式 8051 微控制器产品线,以包括 64kB 闪存。我们的新产品管线在设计上具有外设,以提高其嵌入式系统的功能,同时减少电路板空间。联网微控制器具有先进的功能,包括CAN、以太网和用于多层网络的1-Wire®网络连接。安全微控制器具有用于公钥加密的基于硬件的数学加速器,并支持密钥的快速归零作为篡改响应。混合信号微控制器执行实际信号处理,以制造更好的终端设备。
我们对微控制器性能的承诺不仅限于 8051 内核。我们新的MAXQ® 16位RISC微控制器系列实现了高性能功率比。实现此目的的基本方法是通过单周期指令执行。单周期指令执行通过增加指令带宽从而提高性能和/或通过降低时钟频率的能力降低功耗,使最终用户受益。所有MAXQ指令在单个时钟周期内执行,但跳远/长调用和某些扩展寄存器访问除外。虽然许多RISC微控制器声称支持单周期执行,但这通常适用于一小部分指令或寻址模式。使用MAXQ,单周期执行是常态。
此外,MAXQ架构不需要指令流水线(许多RISC微控制器通用)来实现单周期工作,因此提高了时钟周期利用率。MAXQ指令解码和执行硬件非常简单(时序也非常快),这些操作与程序获取本身进入相同的时钟周期,对最大工作频率的影响最小。为了说明消除指令流水线的好处,请考虑从流水线执行的通用RISC CPU。当程序分支发生时,CPU 使用一个或多个时钟周期(取决于管道深度)将程序提取转移到目标分支地址,并丢弃已获取的指令。显然,使用时钟周期丢弃指令而不是执行指令是浪费和不可取的,因为它会降低性能并增加功耗。虽然该操作对用户来说是不希望的,但 CPU 为重新加载管道而窃取的时钟是体系结构的产物,并且是不可避免的。MAXQ架构区别于其他8位和16位RISC微控制器,提供单周期执行,无需指令流水线(以及随之而来的浪费时钟周期)。
审核编辑:郭婷
-
微控制器
+关注
关注
48文章
7708浏览量
152567 -
嵌入式
+关注
关注
5102文章
19262浏览量
309732 -
cpu
+关注
关注
68文章
10942浏览量
213784
发布评论请先 登录
相关推荐
8051微控制器的基础知识
如何使用ISP1763作为替代品?
Commodore 6540 ROM的替代品
高速8051微控制器:引领成长与创新之路

单独下载可执行文件到MM32F5微控制器
用DS80C51/2微控制器代替Atmel TS80C320U323

单独下载可执行文件到MM32F5微控制器





 工商网监
工商网监
评论