 一条SQL查询语句是怎么去执行的?(下)
一条SQL查询语句是怎么去执行的?(下)
3. 存储引擎
经历千辛万苦,MySQL终于算出了最终的执行计划,然后就可以直接执行了吗?
好吧。。。依然还不可以。
我们知道,表是由一行一行的记录组成的,但这只是逻辑上的概念,或者说只是看上去是这样而已。
3.1 什么是存储引擎
到底该把数据存储在什么位置,是内存还是磁盘?怎么从表里读取数据,以及怎么把数据写入具体的表中,这都是存储引擎 负责的事情。
好吧,看到这里或许你还不知道存储引擎到底是什么。毕竟存储引擎这个名字听起来太玄乎了,它的前身叫做表处理器,是不是就接地气了许多呢?
3.2 为什么需要存储引擎
因为存储的需求不同。
试想一下:
- 如果一张表,需要很高的访问速度,而不需要考虑持久化的问题,是不是最好把数据放在内存呢?
- 如果一张表,是用来做历史数据存档的,不需要修改,也不需要索引,那是不是要支持数据的压缩?
- 如果一张表用在读写并发很多的业务中,是不是要支持读写互不干扰,而且要保证比较高的数据一致性呢?
大家应该明白了,为什么要支持这么多的存储引擎,因为一种存储引擎不能提供所有的特性。
存储引擎是计算机抽象的典型代表,它的功能就是接受上层指令,然后对表中数据进行读取和写入,而这些操作对上层完全是屏蔽的。你甚至可以查阅MySQL文档定义自己的存储引擎,只要对外实现同样的接口就可以了。
存储引擎就是MySQL对数据进行读写的插件而已,可以根据不同目的随意更换(插拔)
3.3 存储引擎怎么用
3.3.1 创建表的时候指定存储引擎
在创建表的时候可以指定当前表的存储引擎,如果没有指定,默认的存储引擎为InnoDB,如果想显式指定存储引擎,可以这样
CREATE TABLE `t_user_innodb` (
`id` int(11) NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`id`)
) ENGINE=innodb DEFAULT CHARSET=utf8mb4;
3.3.2 修改表的存储引擎
ALTER TABLE 表名 ENGINE = 存储引擎名称;
3.4 存储引擎底层区别
下面我们分别创建3张设置了不同存储引擎的表, t_user_innodb 、 t_user_myisam 、t_user_memory 我们看一下不同存储引擎在底层存储方面的差异,首先找到MySQL的数据存储目录
我们看一下不同存储引擎在底层存储方面的差异,首先找到MySQL的数据存储目录
mysql> show variables like 'datadir';
+---------------+-----------------+
| Variable_name | Value |
+---------------+-----------------+
| datadir | /var/lib/mysql/ |
+---------------+-----------------+
进入到目标目录之后,找到当前数据库对应的目录(MySQL会为一个数据库创建一个同名的目录),数据库中表的存储结构如下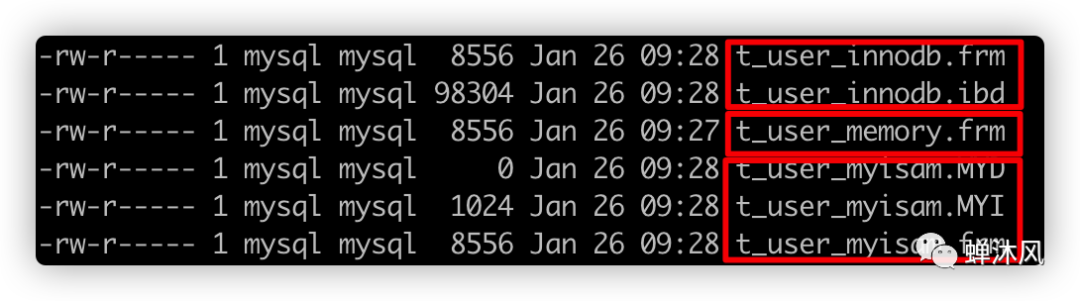 不同的存储引擎存放数据的方式不一样,产生的文件数量和格式也不一样,InnoDB文件包含2个,MEMORY文件包含1个,MYISAM文件包含3个。
不同的存储引擎存放数据的方式不一样,产生的文件数量和格式也不一样,InnoDB文件包含2个,MEMORY文件包含1个,MYISAM文件包含3个。
3.5 常见存储引擎比较
首先我们查看一下当前MySQL服务器支持的存储引擎都有哪一些。
mysql> SHOW ENGINES;
+--------------------+---------+--------------+------+------------+
| Engine | Support | Transactions | XA | Savepoints |
+--------------------+---------+--------------+------+------------+
| InnoDB | DEFAULT | YES | YES | YES |
| MRG_MYISAM | YES | NO | NO | NO |
| MEMORY | YES | NO | NO | NO |
| BLACKHOLE | YES | NO | NO | NO |
| MyISAM | YES | NO | NO | NO |
| CSV | YES | NO | NO | NO |
| ARCHIVE | YES | NO | NO | NO |
| PERFORMANCE_SCHEMA | YES | NO | NO | NO |
| FEDERATED | NO | NULL | NULL | NULL |
+--------------------+---------+--------------+------+------------+
其中,
- Support表示该存储引擎是否可用;
- DEFAULT表示当前MySQL服务器默认的存储引擎;
- Transactions表示该存储引擎是否支持事务;
- XA表示该存储引擎是否支持分布式事务;
- Savepoints表示该存储引擎是否支持事务的部分回滚。
3.5.1 MylSAM
应用范围比较小,表级锁定限制了读/写的性能,因此在Web和数据仓库配置中,通常用于只读或以读为主的工作。
特点:
- 支持表级别的锁(插入和更新会锁表),不支持事务;
- 拥有较高的插入(insert)和查询(select)速度;
- 存储了表的行数(count速度更快)。
怎么快速向数据库插入100万条数据?
可以先用MylSAM插入数据,然后修改存储引擎为InnoDB。
3.5.2 InnoDB
MySQL 5.7及更新版中的默认存储引擎。InnoDB是一个事务安全(与ACID兼容)的MySQL 存储引擎,它具有提交、回滚和崩溃恢复功能来保护用户数据。InnoDB行级锁(不升级为更粗粒度的锁)和Oracle风格的一致非锁读提高了多用户并发性。InnoDB将用户数据存储在聚集索引中,以减少基于主键的常见查询的I/O。为了保持数据完整性,InnoDB还支持外键引用完整性约束。
特点:
- 支持事务,支持外键,因此数据的完整性、一致性更高;
- 支持行级别的锁和表级别的锁;
- 支持读写并发,写不阻塞读(MVCC);
- 特殊的索引存放方式,可以减少IO,提升査询效率。
番外:InnoDB本来是InnobaseOy公司开发的,它和MySQL AB公司合作开源了InnoDB的代码。但是没想到MySQL的竞争对手Oracle把InnobaseOy收购了。后来08年Sun公司(开发Java语言的Sun)收购了MySQL AB,09年Sun公司又被Oracle收购了,所以MySQL和 InnoDB又是一家了。有人觉得MySQL越来越像Oracle,其实也是这个原因。
3.5.3 Memory
将所有数据存储在RAM中,以便快速访问。这个引擎以前被称为堆引擎。
特点:
- 把数据放在内存里面,读写的速度很快,但是数据库重启或者崩溃,数据会全部消失;
- 只适合做临时表。
3.5.4 CSV
它的表实际上是带有逗号分隔值的文本文件。csv表允许以CSV格式导入或转储数据, 以便与读写相同格式的脚本和应用程序交换数据。因为CSV表没有索引,所以通常在正常操作期间将数据保存在InnoDB表中,只在导入或导出阶段使用csv表。
特点:
- 不允许空行,不支持索引;
- 格式通用,可以直接编辑,适合在不同数据库之间导入导出。
3.5.5 Archive
专用与存档,空间经过压缩,用于存储和检索大量很少引用的信息。
特点:
- 不支持索引;
- 不支持update、delete。
3.6 如何选择存储引擎
- 如果对数据一致性要求比较高,需要事务支持,可以选择InnoDB。
- 如果数据查询多更新少,对查询性能要求比较高,可以选择MyISAM。
- 如果需要一个用于查询的临时表,可以选择Memory。
如果所有的存储引擎都不能满足你的需求,并且技术能力足够,可以根据官网内部手册用C语言开发一个存储引擎:https://dev.mvsql.com/doc/internals/en/custom-engine.html
-
服务器
+关注
关注
12文章
9596浏览量
86997 -
TCP
+关注
关注
8文章
1395浏览量
80148 -
MySQL
+关注
关注
1文章
840浏览量
27353
发布评论请先 登录
相关推荐

select语句和update语句分别是怎么执行的
简述SQL更新语句的执行流程1
简述SQL更新语句的执行流程2
一条SQL查询语句是怎么去执行的?(上)
一条SQL查询语句是怎么去执行的?(中)





 工商网监
工商网监
评论