 重建AST
重建AST
利用antlr完成了语法分析之后,就需要进行语义分析了。
词法与语法分析相对固定,利用工具就可以完成,但语义分析则需要设计这么语言或者脚本的人员来完善它。
语义即语言最终需要表达的含义。
我们先来看一个自然语言例子,以我们熟悉的中文为例:我是程序猿!首先我们通过词法分析工具将他拆分开:我,是,程序猿。通过语法分析将它建立成一个AST节点
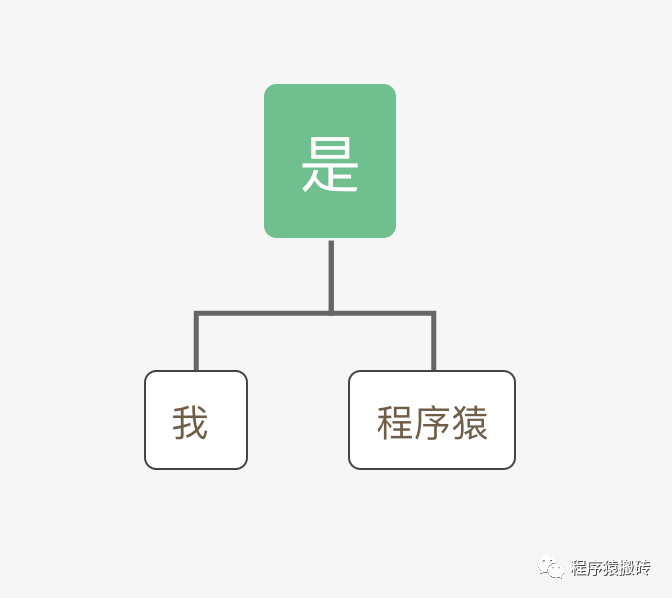
接下来我们通过两种不能的算法将它运算一下看看会得到什么样的结果。
第一种算法:左子节点+根节点+右子节点,运算结果是“我是程序猿”。
第二种算法:右子节点+根节点+左子节点,运算结果是“程序猿是我”。
可以得出,不同的运算规则得到的结果的含义是不一样的,这也是为什么语义分析需要设计人员自己来实现了。但是我们不能随意运算,运算也要符合规则。如果运算规则是:根节点+左子节点+右子节点则得出的结果就是错误的了。
从上面的自然语言例子不难得出,我们设计用于与计算机打交道的语言也是一样的,计算机的目的是计算。
一元表达式,二元表达式,三元表达式他们都有一个根节点是计算符号,子节点是需要计算的表达式。
给这个节点赋予怎么样的含义完成取决于设计这们语言的人。
我已经将第三节中的语法分析规则与词法分析规则进行了完善:
「将原来的点取值改成了方括号取值,完善了小括号优先级语法。具体规则代码如下:」
lexer grammar DynamicDSLLexer;
//关键字
If: 'if';
FOR: 'for';
WHILE: 'while';
IN: 'in';
/// 基础数据类型
Int: 'int';
Double: 'double';
Float: 'float';
String: 'string';
Bool: 'bool';
//字面量
IntLiteral: [0-9]+;
DoubleLiteral: [0-9]+ Dot [0-9]+;
StringLiteral: ('"' .*? '"') | ('\\'' .*? '\\''); //字符串字面量
True: 'true';
False: 'false';
//操作符
AssignmentOP: '=';
RelationalOP: '>' | '>=' | '<' | '<=';
Star: '*';
Plus: '+';
Sharp: '#';
SemiColon: ';';
Dot: '.';
Comm: ',';
LeftBracket: '[';
RightBracket: ']';
LeftBrace: '{';
RightBrace: '}';
LeftParen: '(';
RightParen: ')';
//标识符
Id: [a-zA-Z_] ([a-zA-Z_] | [0-9])*;
//空白字符,抛弃
WS: [ \\t\\r\\n]+ -> skip;
grammar DynamicDSLScript;
import DynamicDSLLexer;
/// 表达式,按右边产生式的顺序来依次优先推导
expression:
primary
| LSB = '[' expression RSB = ']'
| expression LSB = '[' expression RSB = ']'
| LB = '(' expression RB = ')'
| expression LB = '(' expression RB = ')'
| FOR Id IN Id
| declare = (Int | Double | Float | String | Bool) Id assign = '=' expression // 申明变量并赋值
| declare = (Int | Double | Float | String | Bool) Id /// 申明变量,没有赋值
| Id assign = '=' expression /// 赋值,需要查变量是否申明
| expression postfix = ('++' | '--')
| prefix = ('++' | '--') expression
| expression bop = ('*' | '/' | '%') expression
| expression bop = ('+' | '-') expression
| expression bop = ('<' | '<=' | '>' | '>=') expression
| expression bop = ('==' | '!=') expression
| expression bop = ('&&' | '||') expression
| expression bop = '?' expression bop = ':' expression;
primary:
Id
| StringLiteral
| IntLiteral
| DoubleLiteral
| TF = (True | False);
我们来看这样一个例子: (3+5) *(123-5) / 2 + [object][age] 分的语法分析结果是这样的:

这是antlr分析出来的结果,现在我们需要对这个分析结果进行重建,将antlr分析的AST重建成更容易理解与运算的AST。重建后的结果如下:

每一个节点都是我们在语法规则文件中定义的一种推导规则,要计算根节点,就必须先计算子节点,通过递归的方式从子节点到根节点运算的过程就是:深度优先遍历。通过对这个AST进行深度优先遍历,得到最终的运算符。
A:加减乘除运算就是将左右的结果作对应的运算
B: []取舍则是将先取值运算的作为后取值运算的子节点,所以它的推导式是这样的:
| LSB = '[' expression RSB = ']'
| expression LSB = '[' expression RSB = ']'
首先尝试推导是否是一个独立的[]运算,比如这样[object]。
我们在这里赋予它的含义是,从栈帧上下文中去寻找名称为object的变量,并取出它的值。
如果是连续的[]运算,比如[object][age]则我们使用上面的第一条推导式发现推导是失败的,
接着尝试第二条推导式,首先将[age]推导出来成为一个节点,接着[object]继续重新按第一条再次推导,发现推导成功,再将这个节点作用[age]推导出来的子节点。
在求值的时候就会优先求子节点[object]得到的结果作为[age]节点的上下文变量环境继续寻找名称是age的变量的值。
Antlr的语法推导是按定义的顺序进行推导的,首先推导定义在前面的规则,推导失败再继续推导后面的规则。
推导成功立即建立一个AST节点,推导未完成的部分继续进行推导并成功后变成此节点的子节点。
每增加一种推导规则我们就增加一种运算节点。
接下来,我们将利用C++来完成对AST的节点实现,实现一个简单的节点与数据类型模型。完成AST的C++实现与运算。
如果你觉得有用,请分享给更多的人。
-
语义
+关注
关注
0文章
21浏览量
8659 -
ANTLR
+关注
关注
0文章
3浏览量
5738 -
语法分析
+关注
关注
0文章
2浏览量
970
发布评论请先 登录
相关推荐
2009伊拉克重建展
2010黎巴嫩重建展|黎巴嫩重建工程展|黎巴嫩重建展
2011伊拉克重建展
AST3TQ评估板旨在促进AST3TQ系列TCXO和VCTCXO的电气性能测试
ASMT-JR30-AST01 3W迷你大功率LED

ASMT-AR30-AST00 3W大功率LED

ASMT-AR00-AST00 1W大功率LED

ASMT-AR00-AST01 1W大功率LED

ASMT-JR10-AST01 1W迷你大功率LED







 工商网监
工商网监
评论