 大脑视觉信号被Stable Diffusion复现成图像!
大脑视觉信号被Stable Diffusion复现成图像!
“现在Stable Diffusion已经能重建大脑视觉信号了!”
就在昨晚,一个听起来细思极恐的“AI读脑术”研究,在网上掀起轩然大波:

这项研究声称,只需用fMRI(功能磁共振成像技术,相比sMRI更关注功能性信息,如脑皮层激活情况等)扫描大脑特定部位获取信号,AI就能重建出我们看到的图像!

例如这是一系列人眼看到的图像,包括戴着蝴蝶结的小熊、飞机和白色钟楼:

AI看了眼人脑信号后,立马就给出这样的结果,属实把该抓的重点全都抓住了:

再发展一步,这不就约等于哈利波特里的读心术了吗??

更有网友感到惊叹:如果说ChatGPT开放API是件大事,那这简直称得上疯狂。
所以,这究竟是怎么一回事?
用Stable Diffusion可视化人脑信号
这项研究来自日本大阪大学,目前已经被CVPR 2023收录:

High-resolution image reconstruction with latent diffusion models from human brain activity
研究希望能从人类大脑活动中,重建高保真的真实感图像,来理解大脑、并解读计算机视觉模型和人类视觉系统之间的联系。
要知道,此前虽然有不少脑机接口研究,致力于从人类大脑活动中读取并重建信号,如意念打字等。
然而,从人类大脑活动中重建视觉信号——具有真实感的图像,仍然挑战极大。
例如这是此前UC伯克利做过的一项类似研究,复现一张人眼看到的飞机片段,但计算机重建出来的图像却几乎看不出飞机的特征:

△图源UC伯克利研究Reconstructing Visual Experiences from Brain Activity Evoked by Natural Movies
这次,研究人员重建信号选用的AI模型,是这一年多在图像生成领域地位飞升的扩散模型。
当然,更准确地说是基于潜在扩散模型(LDM)——Stable Diffusion。
整体研究的思路,则是基于Stable Diffusion,打造一种以人脑活动信号为条件的去噪过程的可视化技术。
它不需要在复杂的深度学习模型上进行训练或做精细的微调,只需要做好fMRI(功能磁共振成像技术)成像到Stable Diffusion中潜在表征的简单线性映射关系就行。
它的概览框架是这样的,看起来也非常简单:
仅由1个图像编码器、1个图像解码器,外加1个语义解码器组成。
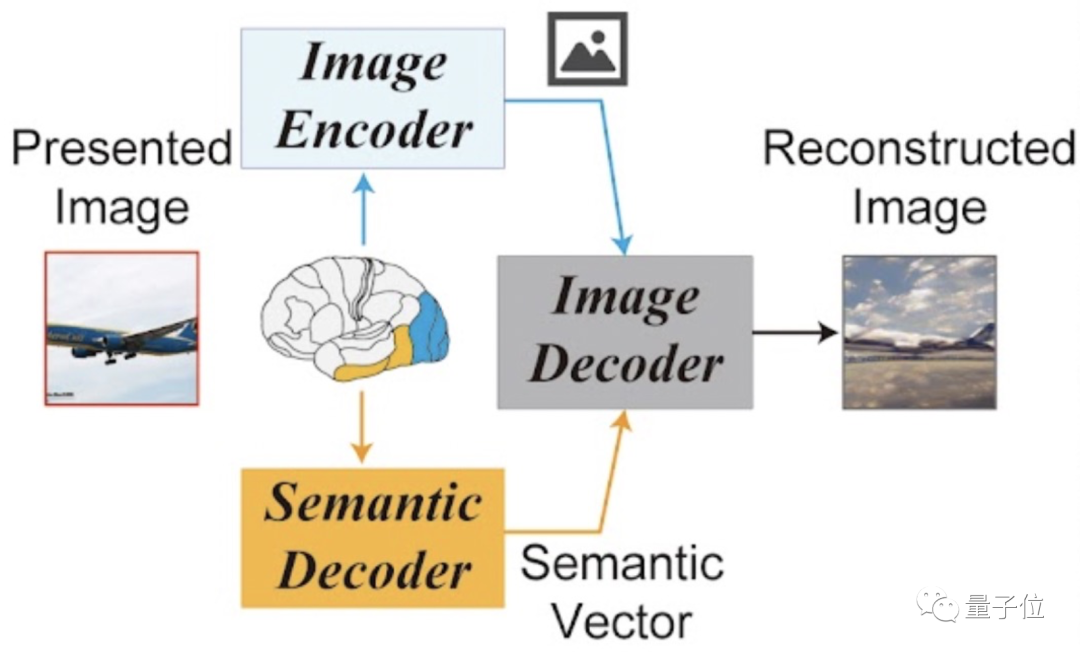
具体怎么work?
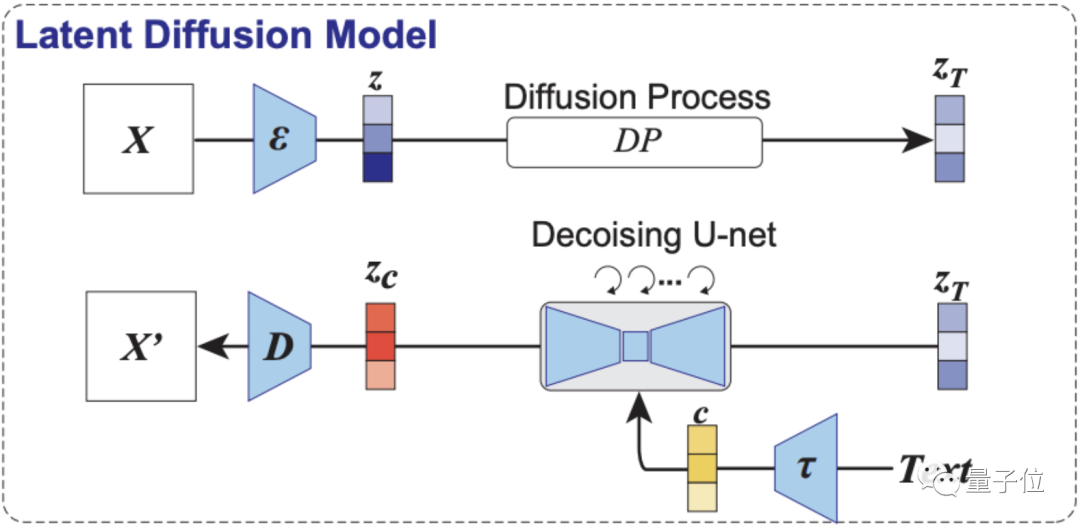
如下图所示,第一部分为本研究用到的LDM示意图。
其中ε代表图像编码器,D代表图像解码器,而τ是一个文本编码器(CLIP)。
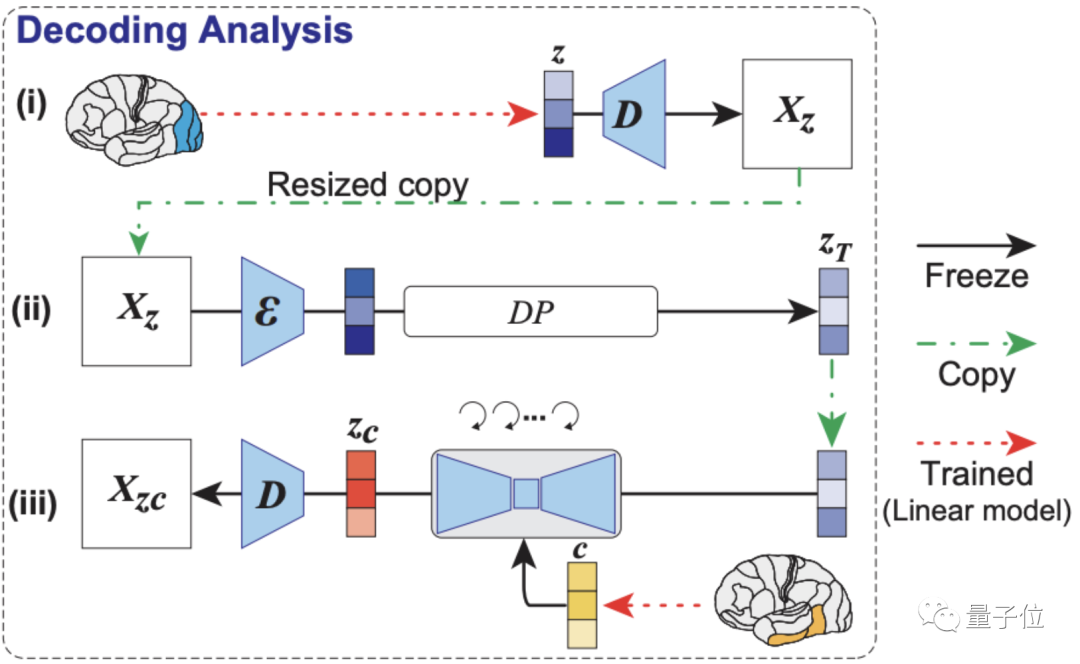
重点是解码分析,如下图所示,模型依次从大脑早期(蓝色)和较高(黄色)视觉皮层内的fMRI信号中,解码出重建图像(z)和相关文本c的潜在表征。
然后将这些潜在表征当作输入,就可以得到模型最终复现出来的图像Xzc。
最后还没有完,如编码分析示意图,作者还构建了一个编码模型,用来预测LDM不同组件(包括图像z、文本c和zc)所对应的fMRI信号,它可以用来理解Stable Diffusion的内部过程。
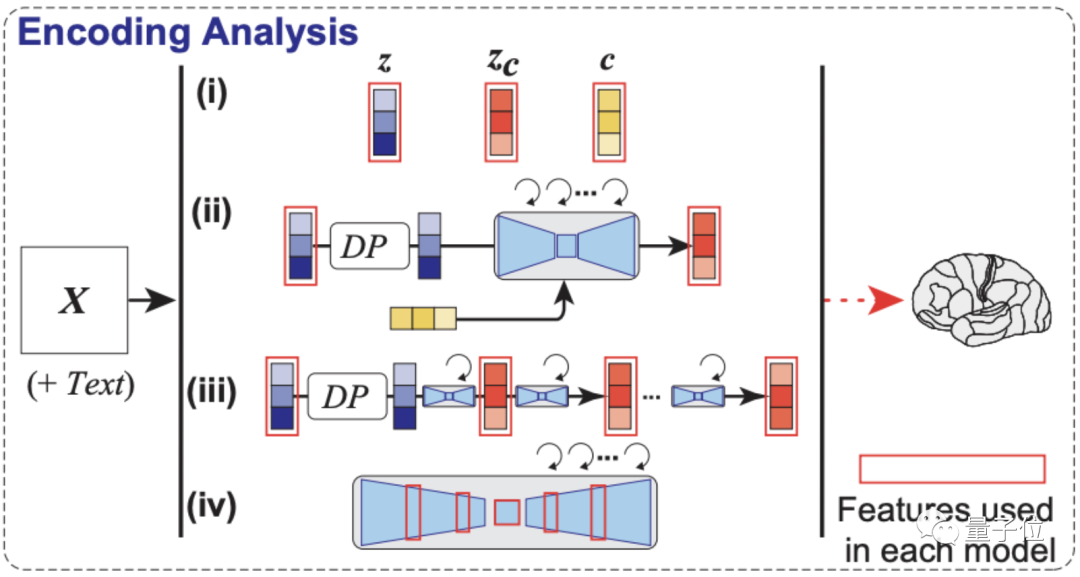
可以看到,采用了zc的编码模型在大脑后部视觉皮层产生的预测精确度是最高的。(zc是与c进行交叉注意的反向扩散后,z再添加噪声的潜在表征)
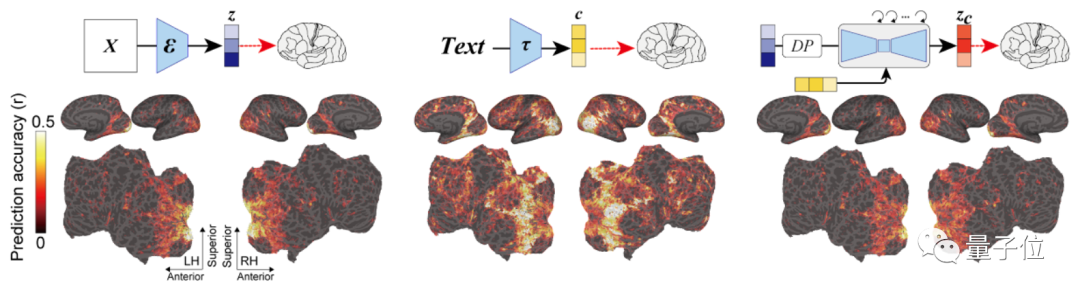
相比其它两者,它生成的图像既具有高语义保真度,分辨率也很高。

还有用GAN重建人脸图像的
看完这项研究,已经有网友想到了细思极恐的东西:
这个AI虽然只是复制了“眼睛”所看到的东西。
但是否会有一天,AI能直接从人脑的思维、甚至是记忆中重建出图像或文字?
“语言的用处不再存在了”

于是有网友进一步想到,如果能读取记忆的话,那么目击证人的证词似乎也会变得更可靠了:

还别说,就在去年真有一项研究基于GAN,通过fMRI收集到的大脑信号重建看到的人脸图像:

不过,重建出来的效果似乎不怎么样……
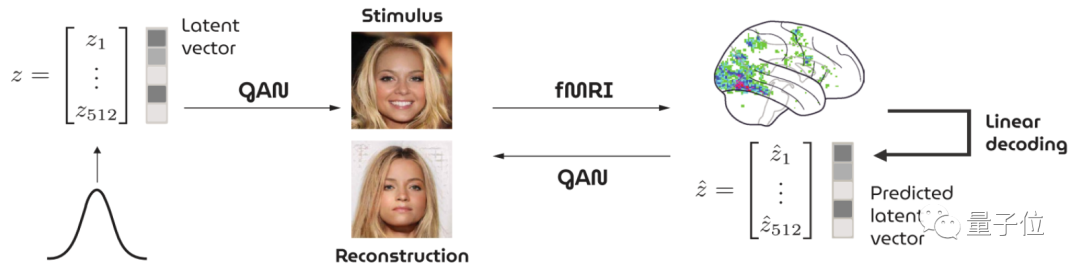
显然,在人脸这种比较精细的图像生成上,AI“读脑术”还有很长一段路要走。
对于这种大脑信号重建的研究,也有网友提出了质疑。
例如,是否只是AI从训练数据集中提取出了相似的数据?
对此有网友回复表示,论文中的训练数据集和测试集是分开的:

作者们也在项目主页中表示,代码很快会开源。可以先期待一下~

作者介绍
本研究仅两位作者。
一位是2021年才刚刚成为大阪大学助理教授的Yu Takagi,他主要从事计算神经科学和人工智能的交叉研究。
最近,他同时在牛津大学人脑活动中心和东京大学心理学系利用机器学习技术,来研究复杂决策任务中的动态计算。
另一位是大阪大学教授Shinji Nishimoto,他也是日本脑信息通信融合研究中心的首席研究员。
研究方向为定量理解大脑中的视觉和认知处理,谷歌学术引用3000+次。
那么,你觉得这波AI重建图像的效果如何?
审核编辑 :李倩
-
成像技术
+关注
关注
4文章
290浏览量
31459 -
人工智能
+关注
关注
1791文章
47274浏览量
238473
原文标题:CVPR 2023 | 大脑视觉信号被Stable Diffusion复现成图像!"AI读脑术"来了!
文章出处:【微信号:CVer,微信公众号:CVer】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐

图像采集卡不断发展和改进,为视觉系统提供更大的价值

图像采集卡:增强视觉数据采集
示波器的波形存储与复现,再也不怕瞬时信号抓不住了

实操: 如何在AirBox上跑Stable Diffusion 3

计算机视觉和图像处理的区别和联系

机器视觉中图像采集卡的功能与应用

UL Procyon AI 发布图像生成基准测试,基于Stable Diffusion
韩国科研团队发布新型AI图像生成模型KOALA,大幅优化硬件需求
机器视觉图像采集卡:关键的图像处理设备

OpenAI视频模型Sora的架构及应用场景
Stability AI试图通过新的图像生成人工智能模型保持领先地位

人工视觉仍然需要图像采集卡






 工商网监
工商网监
评论