 基于Transformer架构的InstructGPT介绍
基于Transformer架构的InstructGPT介绍
1. 论文信息
1.1 prompt learning
Prompt Learning是自然语言处理中的一种技术,它通过设计一些提示语(prompt)来指导模型在执行任务时进行学习和推理。Prompt Learning技术的核心思想是,在模型的输入中加入一些人工设计的提示语,这些提示语能够帮助模型更好地理解输入数据的含义和任务要求,从而提高模型在特定任务上的性能。通常情况下,提示语可以是一个问题、一段描述或者一个特定的标记序列。
1.2 GPT的介绍
GPT(Generative Pre-trained Transformer)的目标是训练出一种能够生成自然语言文本的模型。它使用了大规模的预训练数据和神经网络技术来自动学习文本数据的语言规律,进而能够生成自然流畅的文本。GPT是一种基于Transformer架构的深度学习模型,可以用于自然语言生成、文本分类、语言理解等多种任务。
GPT的目标是通过无监督学习的方式,将海量的自然语言文本转化为一种通用的语言表示形式,从而使得模型能够在不同的任务中进行迁移学习,提高模型的泛化能力。为了达到这个目标,GPT使用了预训练和微调两个阶段。在预训练阶段,GPT使用大量的无标签数据对模型进行训练,从而学习文本的语言规律;在微调阶段,GPT使用有标签数据对模型进行微调,以适应特定的任务。
GPT是“Generative Pre-trained Transformer”的缩写,是由OpenAI推出的自然语言处理模型。目前已经发布了三代版本,每一代都有其独特的特点和应用。
以下是GPT一、二、三代的对比:
GPT-1
发布于2018年,包含1.17亿个参数。
使用了12层transformer结构,可以预测下一个词。
在通用自然语言处理任务上表现出色,包括文本分类、情感分析、摘要生成等。
缺点是对于长文本生成不如人意,容易出现重复和无意义的内容。
GPT-2
发布于2019年,参数量是GPT-1的10倍,达到了1.5亿个。
使用了24层transformer结构,可以生成更长、更复杂的文本。
在多项自然语言处理任务上表现出色,并且可以生成高质量的文章、对话等。
由于生成的文本过于真实,存在滥用的风险,OpenAI没有将模型公开发布。
GPT-3
发布于2020年,参数量是GPT-2的13倍,达到了1.75万亿个。
使用了1750亿个语言模型参数,可以生成更加自然、流畅、有逻辑的文本。
在多项自然语言处理任务上表现出色,甚至可以完成类似编程的任务,例如编写简单的代码。
GPT-3也被用于自然语言生成、对话系统、问答系统等应用,具有广泛的应用前景。
总体来说,随着模型的迭代和参数量的增加,GPT的性能逐渐提高,同时也具有更广泛的应用前景。
1.3 InstructGPT
InstructGPT是一种基于GPT-3的自然语言处理模型,它是由AI2(Allen Institute for Artificial Intelligence)开发的。与GPT-3不同的是,InstructGPT专注于解决指导型对话(instructional dialogue)的任务。指导型对话是指一种对话形式,其中一个人(通常是教师或者专家)向另一个人(通常是学生或者用户)提供指导、解释和建议。在这种对话中,用户通常会提出一系列问题,而指导者则会针对这些问题提供详细的答案和指导。
InstructGPT使用了GPT-3的架构和预训练技术,但是对其进行了针对性的微调,使其能够更好地应对指导型对话任务。具体而言,InstructGPT通过对大量的指导型对话数据进行微调,使得模型能够更加准确地理解用户的问题,并且能够生成更加准确、详细的答案和指导。此外,InstructGPT还支持多轮对话,可以对用户的多个问题进行连续的回答和指导。
InstructGPT的应用场景包括在线教育、智能客服等领域,可以帮助用户更快地获取所需的知识和指导,并且能够提高教育和客服的效率。
2. 方法框架
InstructGPT是一种基于语言模型的自然语言处理技术,旨在解决指令性任务(instructional tasks),例如问答、推荐、提示、教育等领域。其技术路线主要包括以下几个步骤:
数据收集:收集大规模的指令性文本数据,包括问答、教育、用户指南等。
数据预处理:对收集的数据进行预处理,包括分词、标记化、词干提取、停用词过滤、词向量化等。
模型训练:使用预处理后的数据训练深度学习模型,通常采用基于Transformer的神经网络结构,例如GPT(Generative Pre-trained Transformer)。
模型微调:针对具体的指令性任务,对预训练模型进行微调,例如通过迁移学习或fine-tuning的方法,使得模型能够更好地适应特定的任务和领域。
模型优化:对微调后的模型进行进一步优化,包括模型压缩、量化、剪枝等技术,以提高模型的速度和效率。
应用部署:将优化后的模型部署到具体的应用场景中,例如问答系统、推荐系统、教育平台等,提供高效、准确的指令性服务。
3. InstructGPT的训练模式
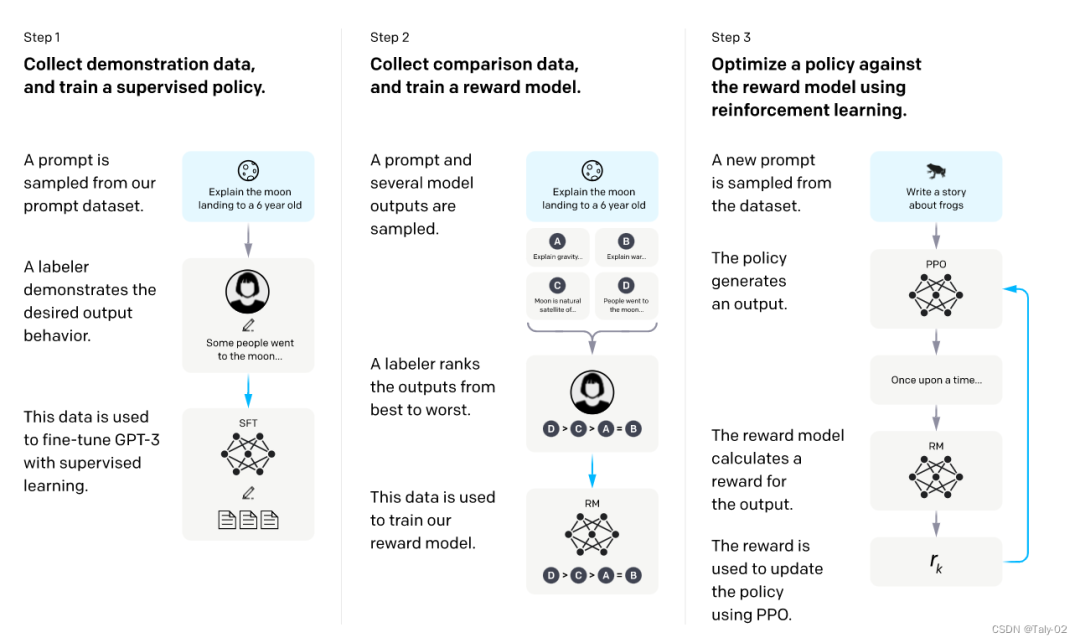
我们得想办法怎么让这个过程变得更轻松一点:
首先利用GPT-3进行初始化,希望对这个比较强大的模型先进行一些prompt learning来进行fine-tuning。先人工构造一批数据,让模型学一学,获得一个模型。
然后,我们让模型根据一系列提示输出来评估其效果。我们让模型针对每个提示生成多个输出,随后让人员对这些输出进行打分排序。虽然排序过程也需要人工干预,但相较于直接让人员编写训练数据,这种方法更为便捷。因此,这一过程能够更轻松地标注更多数据。然而,这些标注数据不能直接用于训练模型,因为它们代表了一种排序结果。但我们可以训练一个打分模型,称为“reward model”。该模型的作用在于对于每一个
接下来,我们继续训练模型,给定一些prompt,得到输出之后,把prompt和output输入给RM,得到打分,然后借助强化学习的方法,来训练该模型,如此反复迭代,最终修炼得到最终的模型,也就是最终的InstructGPT。
可以看出InstructGPT的训练模式就是先靠人类手工设计一些精华信息,然后利用模型来尝试模仿这些信息。之后根据模仿程度进行比对和打分,根据打分进行调整。最后打分机器就可以和模型配合,自动化地进行模型的迭代。这种迭代过程就是RLHF。
InstructGPT论文中,给出了上述三个步骤,涉及的训练样本也是非常多的:
SFT数据集:人类预设的13k的prompts;
RM数据集:用来训练打分模型的数据,包含33K的prompts;
PRO数据集:31K最后的数据。
前两步的prompts,来自于OpenAI的在线API上的用户使用数据,以及雇佣的标注者手写的。最后一步则全都是从API数据中采样的,下表的具体数据:
4. 对InstructGPT的展望
作为一个基于自然语言处理技术的AI语言模型,InstructGPT可以为用户提供基本的对话和回答问题的服务,但它仍存在以下不足:
缺乏真实人类的情感和情绪表达能力,无法在情感和社交领域提供有意义的支持。
缺乏真实世界知识和实际经验,对于需要领域专业知识的问题回答可能不够准确。
可能存在一些潜在的偏见和错误,这取决于模型的训练数据和算法。
随着对话时间的增加,InstructGPT的回答可能变得越来越冗长或者不够精确。
语言模型的工作基于已有的数据集,如果没有合适的数据集或者缺少某些领域的数据,模型的表现就会受到限制。
总之,InstructGPT目前还存在一些限制,尽管我们已经取得了很大进展,但仍需要进一步的研究和发展,以实现更加高效和智能的AI对话系统。
审核编辑:刘清
-
Pro
+关注
关注
0文章
95浏览量
39495 -
GPT
+关注
关注
0文章
365浏览量
15632 -
自然语言处理
+关注
关注
1文章
624浏览量
13722 -
OpenAI
+关注
关注
9文章
1184浏览量
6919
原文标题:InstructGPT介绍
文章出处:【微信号:GiantPandaCV,微信公众号:GiantPandaCV】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
基于DINO知识蒸馏架构的分层级联Transformer网络
关于深度学习模型Transformer模型的具体实现方案
如何更改ABBYY PDF Transformer+界面语言
谷歌将AutoML应用于Transformer架构,翻译结果飙升!
解析Transformer中的位置编码 -- ICLR 2021

如何使用Transformer来做物体检测?
Transformer深度学习架构的应用指南介绍
使用跨界模型Transformer来做物体检测!

InstructGPT与ChatGPT的学习与解读

ChatGPT/GPT的原理 ChatGPT的技术架构
GPT/GPT-2/GPT-3/InstructGPT进化之路
Transformer结构及其应用详解
RetNet架构和Transformer架构对比分析
基于Transformer模型的压缩方法






 工商网监
工商网监
评论