 类ChatGPT训练需高性能芯片大规模并联,高速接口IP迎红利时代
类ChatGPT训练需高性能芯片大规模并联,高速接口IP迎红利时代
近段时间,ChatGPT的火热重新掀起人工智能产业热潮,尤其是AIGC(指利用人工智能技术来生成内容)领域,已经进入到狂飙姿态,头部科技企业争分夺秒地寻求抢先发布类ChatGPT应用。
众所周知,类ChatGPT应用是一个吞金兽,微软公司为了训练ChatGPT使用了1万张英伟达的高端GPU。“从训练的角度来看,计算性能再好的GPU芯片比如A100如果无法集群在一起去训练,那么训练一个类ChatGPT的大模型可能需要上百年。因此,AI大模型的训练对高速接口IP是一个巨大的挑战,也是一个巨大的机遇。”奎芯科技市场及战略副总裁唐睿在接受电子发烧友网采访时表示。
奎芯科技成立于2021年,该公司的口号是“芯粒高速互联,海量算力源泉 ”。目前,奎芯科技已经推出的高速接口IP组合包括USB、PCIe、SATA、SerDes、MIPI、DDR、HDMI、DP、HBM等丰富的类型。
类ChatGPT带动接口IP发展
从半导体产业分布来看,IP是底层技术,接口IP同样如此,因此关键性和重要性是不言而喻的。那么在AIGC产业里,接口IP能够发挥哪些作用呢?唐睿提到了以下几点。
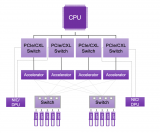
首先是芯片上的互联接口,也就是Die to Die类型的互联接口IP,包括UCIe等,用以扩充单芯片的计算能力;其次是Chip to Chip类型的互联接口IP,包括SerDes/PCIe/CXL等,能够加快芯片之间的互联和数据交换,满足更高带宽的需求;此外还有内存接口IP,包括SATA、DDR、HBM等,能够用于打造更高性能的存储产品,帮助类ChatGPT存储和交换大规模的数据;再上一层就是数据通讯接口的接口IP。因此,从训练的角度来看,类ChatGPT应用的爆发,能够带来非常大的接口IP需求。
在此前的预测里,有市场调研机构的数据显示,2022年至2026年高速互联IP的市场规模有望以75%的年复合增长率快速成长。“接口IP市场的增长一定是跟随整个高性能计算芯片大趋势的,包括芯片运算性能、内存和带宽方面的提升都需要接口IP的帮助,因此芯片用量的提升一定会带来更大的接口IP用量。”唐睿认为,“同时计算芯片性能的提升已经受限于摩尔定律放缓的影响,单芯片的性能会逐渐遇到瓶颈,那么互联组成算力集群就是一个有效的手段,这也会加快推动接口IP的发展。”
虽然产业热潮来临,不过唐睿并不担心一下子会涌入很多同行或者友商,造成国内接口IP产业内卷。“市场竞争的激烈程度会增加,但接口IP是高门槛的领域,目前国内做高速混合电路的人才其实并不多,特别是在先进制程上做高速模拟电路设计的人才更少,因此从零组建团队进入这个领域是非常困难的。”他对此讲到。
国产厂商的布局和追赶
从全球产业格局来看,在接口IP方面,目前新思科技和楷登电子等EDA厂商以及其他国际上的接口IP厂商还处于领先位置。相关数据显示,截止到2021年,国产接口IP的自给率还不足10%。
“目前,从技术上来看,国产接口IP厂商确实还处于追赶的位置,不过这种差距已经越来越小。”唐睿指出,“2023年,奎芯科技将会推出一系列性能达到国际领先水平的接口IP产品,包括HBM3以及其他领先的D2D类型的互联接口IP。”
同时,他还讲到,在服务国内客户方面,实际上也会存在很多本地化的需求,需要根据这些需求结合晶圆厂的工艺特色,提供IP解决方案。奎芯科技很多IP产品,在研发的过程中或者研发之前,就得到了客户方的问询,围绕客户的芯片架构,有非常清晰的需求。奎芯科技联合自己的下游客户成立了多个产业联盟,通过这些联盟将不同类型的计算芯片公司联合在一起,协同发展,围绕数据中心应用把国产方案搭建好,弥补国内这一块的空白。
当前,AI大模型训练所用到的算力集群基本上都是基于英伟达通用算力芯片来打造,在这方面国产通用算力芯片还存在一定的性能差距。唐睿表示,国产高性能计算芯片还是有机会的,AI大模型并不是一个近期出现的新鲜事物,近些年国内AI产业已经在跟进这一趋势,只是类ChatGPT类型应用背后的大模型参数规模更大。针对这方面的需求,国内芯片产业也早就启动了这方面的布局,包括奎芯科技所在的接口IP赛道,都在向这个方向努力。不过,从IP研发到芯片设计,再到应用落地,这中间会有一个时间差。实际上,国外的公司也是在用之前的芯片通过互联在做这方面的硬件支持。
“还需要特别提出的是,AIGC是一个软硬件结合的应用。软件方面,算法模型的体量也是一个值得研究去突破的方向。目前,国外开源的AIGC算法里,也并非只有Open AI的GPT算法,通过介绍信息来看,也有一些参数更小的模型能够实现类ChatGPT应用。我们实际上可以借鉴这些模型,以减少软件对硬件的需求压力。”唐睿最后讲到。
小结
IP对半导体产业有巨大的撬动力量,在全球范围内,约60多亿美元的IP销售额,带动的是5000亿美元的全球半导体市场销售额。对于***而言,短期内实现单芯片性能暴增的难度非常大,不过通过高速接口IP,用算力集群的方式,也能够逐步进入类ChatGPT的红利市场。
审核编辑 :李倩
原文标题:类ChatGPT训练需高性能芯片大规模并联,高速接口IP迎红利时代
文章出处:【微信号:elecfans,微信公众号:电子发烧友网】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
乾瞻科技发布车用高速接口IP系列,助力AI与自动驾驶
【「大模型启示录」阅读体验】+开启智能时代的新钥匙
使用EMBark进行大规模推荐系统训练Embedding加速

什么是协议分析仪和训练器
端到端InfiniBand网络解决LLM训练瓶颈

芯品# 高性能计算芯片
开芯院发布全球首个开源大规模片上互联网络IP“温榆河”

高性能计算集群的能耗优化

进一步解读英伟达 Blackwell 架构、NVlink及GB200 超级芯片
构建高性能计算芯片





 工商网监
工商网监
评论