 【AI简报20230304期】 ChatGPT API 正式发布、2023年中国人工智能产业趋势报告
【AI简报20230304期】 ChatGPT API 正式发布、2023年中国人工智能产业趋势报告
嵌入式 AI
1. 2023年中国人工智能产业趋势报告
原文:
http://k.sina.com.cn/article_1716314577_664ce1d1001017mhf.html
1.概述
易观人工智能AMC模型显示,图像分类与图像语义分割类应用已经较为成熟且有着较为稳定的市场空间,文本处理、语音识别与双模态等应用正逐渐实现对于市场的渗透。强化学习、因果学习、语言大模型等相关应用通过技术的迭代成功走出实验室,正不断摸索其商业模式。图神经网络、多模态泛化与自监督学习等应用正加速跨越从试验研发到产业落地的难关,对扩散模型、量子AI、具身智能等的研究也将孕育智能程度更高、通用性更强的应用。建议短期关注处于市场启动期与高速发展期之间的应用成熟情况,长期关注处于探索期与市场启动期的应用研发进展。
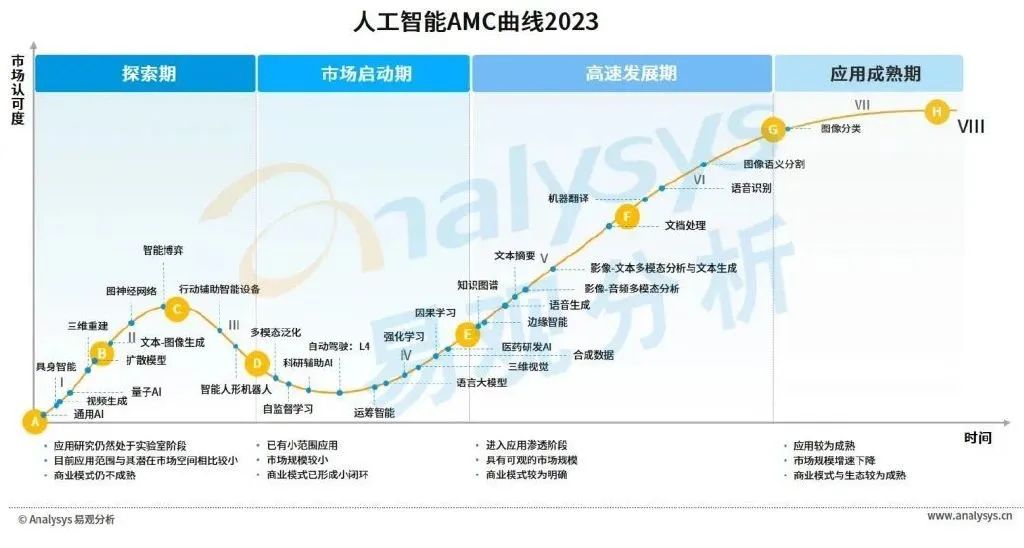
2.基础设施篇
趋势1
人工智能发展需求将快速提升数据众包产业规模与专业性
趋势2
我国将形成芯片-人工智能产业内循环
趋势3
加速对边缘智能的探索需不同类型参与方进行紧密合作
3.算法模型篇
趋势4
文本-图像生成模型将出现针对细分领域需求的定制化产品
趋势5
大规模语言模型在专业领域的商业化方向仍需持续探索
趋势6
强化学习应用或将在科研与产业研发领域率先商业化
趋势7
图神经网络各类应用的商业价值均将大幅提升
趋势8
扩散模型将在年内应用于设计、建筑、广告等行业
4.产业应用篇
趋势9
产业界将出现更多结合算法模型原理进行设计的智能化应用
趋势10
科研人工智能作为国家战略其重要性将进一步提升
趋势11
智能设备在工业领域的应用渗透率将快速提升
趋势12
消费领域对行动辅助的需求或将促进相关智能设备先行发展
2. ChatGPT API 今日正式发布,中国厂商往何处去?
原文:
https://mp.weixin.qq.com/s/ClhnJZkU1P9cEGfJ7CZDHA
价格一折
OpenAI在官网发布,ChatGPT 向外界开放了API,并且开放的是已经实装应用到 ChatGPT 产品中的 “gpt-3.5 - turbo” 模型,可以说是拿出了压箱底的招牌武器。不仅如此,在定价上,OpenAI 仅收取每1000个 token 0.002美元的价格,是原先 GPT-3.5 模型价格的1/10。价格之低,令不少业者大跌眼镜,以为自己小数点后多看了一个“0”。
此外,OpenAI还推出了另一个新的Whisper API,该API是由人工智能驱动的语音转文本模型,该模型去年9月推出,并可以通过API进行使用,这也为开发者提供了更灵活的互动方式。
先前, ChatGPT 有点小贵的价格还令一些使用者颇有微词,并且前股东马斯克也曾多次在推特上指责 ChatGPT 闭源的行为,已经让 OpenAI 从一家非盈利公司,变成了微软控制下的“走狗”。而这次API发布之人们才发现,OpenAI 或许真的有着一颗“普惠”的心。
ChatGPT 为什么选择在今天,以一个如此低廉的价格开放 API?他们直言:通过一系列系统层面的优化,12月以来,团队将 ChatGPT 的成本降低了90%,而这些被节省了的费用,则可以被团队用来惠及更多的开发者。
过去有消息称,ChatGPT完成单次训练大概需要一个月的时间,花费1200万美元左右的成本。而训练效率的提升,无疑使AI也完成了巨大的“降本增效”。
4天前,OpenAI的创始人——山姆·奥特曼就曾在推特上表示:一种新的摩尔定律马上即将成为现实——每过18个月,宇宙中的智能数量就会翻上一番。
此言一出,引得业内争议不断。今天看来,或许是为了今天ChatGPT API 的发布造势。
在官网中,他们写道:“开发者们现在可以在他们的App和产品中,通过我们的 API 将 ChatGPT 整合其中。”
中国公司们准备好了吗?
ChatGPT 开放 API利好开发者,但对那些新进加入 ChatGPT 赛道的创业者,此时也被迫感受到了一丝寒意。
入局本就落后于人,少了先发优势,不少人团队还没完全建成,壮志豪言刚刚出口,而抬头一看,ChatGPT已经一骑绝尘,想要望其项背,都还需不少苦工。
而对于大厂,OpenAI 此举也是敲山震虎——百度、阿里这样的大厂,想做类ChatGPT 产品,怎么才能做得比本尊更好,投入也更少?
AI科技评论认为,对于中国的厂商来说,ChatGPT 开放 API,也并不全然代表失去了未来生存和盈利的机会。
百度的“文心一言”、阿里的“通义”、华为的“盘古”、IDEA的“封神榜”、澜舟的“孟子”、智源的“悟道”……在这个赛道上有所积累的玩家不少。技术层面,他们的路径并不相同,实力上也各有千秋;如何完成更高效、廉价、贴合市场的工程化,是摆在他们面前“弯道超车”的绝佳机遇。
从“模型、算力、数据、场景”的四个因素角度上来看,大模型的算法壁垒,并没有外界看来的如此不可逾越,随着时间推移和研究进步,算法性能很可能逐渐趋同;而算力方面,则是真金白银的投入,资本和资源的比拼。
如果抛开算法、算力两大方面,在数据和场景上,中国厂商则有很大的优势。
IDEA研究院的讲席科学家张家兴博士,曾在一次演讲中做过类比:投入了数百名正式员工、上千名标注员,用了3年时间,OpenAI 从 GPT-3 再到 ChatGPT,持续对一项模型进行修改,并未对模型结构进行过创新。
正如搜索引擎公司,调用数万名员工、数千标注员,二十年如一日地打磨优化,最终只为了将引擎做得至臻至美。
大投入、长坚持,是未来一家成功AI公司,最珍贵的品质——若非如此,AI就做不好工程化落地的工作,而这也是中国AI公司面前最大的机会。
在数据上,越来越多业者发现,要用AI讲好中国故事,首先需要的是中国本土原生的数据集,这样才能更贴近中文的使用,也更贴近中国的市场环境。
如果再聊到政治环境,数据脱敏、以及对于涉黄、违法、涉政内容的风险管控,也是大模型工程化落地,所不得不关注的核心难题。
做数据集的收集,中国厂商自然近水楼台;而到了实际操作中,中国厂商在人力资源和成本上,也相较OpenAI要更有优势。
而寻找场景和技术产品化,更是中国厂商的强项。文章先前还提到的,那些将 ChatGPT 镜像做成产品,赚取用户差价的“掮客”,早在王小川、王慧文宣布入局之前,就以这种思路,赚取到了“ChatGPT”的第一桶金。
要想全民进入AIGC时代,AI产品化的进步,可以说与AI技术的进步同等重要——技术不仅要有用,还得“能用”,让用户用得舒服。有国内巨大市场作为后盾,AI产品一旦起势,就很容易形成马太效应,在用户中形成强大的影响力。
ChatGPT如同一只鲇鱼钻进了池子,用风卷残云之势搅动乾坤。面临如此强敌,中国的竞争者们也必须动起来,才能在激烈的竞逐中获得一席之地。
评价这件事时,张家兴说道:“OpenAI是一群相信通用人工智能AGI会实现的人,当我们在焦虑如何做出中国ChatGPT的时候,他们已经在探索AGI的下一步,同时把当下的成熟技术推向落地,这才是ChatGPT API发布这件事情真正的含义。”
3. 微软亚研院:Language Is Not All You Need
原文:
https://mp.weixin.qq.com/s/n7ziKJeVzEzVB1w1kpsn4g
还记得这张把谷歌AI搞得团团转的经典梗图吗?
现在,微软亚研院的新AI可算是把它研究明白了。
拿着这张图问它图里有啥,它会回答:我看着像鸭子。
但如果你试图跟它battle,它就会改口:看上去更像兔子。并且还解释得条条是道:
图里有兔子耳朵。

是不是有点能看得懂图的ChatGPT内味儿了?
这个新AI名叫Kosmos-1,谐音Cosmos(宇宙)。AI如其名,本事确实不小:图文理解、文本生成、OCR、对话QA都不在话下。
甚至连瑞文智商测试题都hold住了。
而具备如此能力的关键,就写在论文的标题里:Language is not all you need。
多模态大语言模型
简单来说,Kosmos-1是一种把视觉和大语言模型结合起来的多模态大语言模型。
在感知图片、文字等不同模态输入的同时,Kosmos-1还能够根据人类给出的指令,以自回归的方式,学习上下文并生成回答。
研究人员表示,在多模态语料库上从头训练,不经过微调,这个AI就能在语言理解、生成、图像理解、OCR、多模态对话等多种任务上有出色表现。
比如甩出一张猫猫图,问它这照片好玩在哪里,Kosmos-1就能给你分析:猫猫戴上了一个微笑面具,看上去就像在笑。

Kosmos-1的骨干网络,是一个基于Transformer的因果语言模型。Transformer解码器作为通用接口,用于多模态输入。
用于训练的数据来自多模态语料库,包括单模态数据(如文本)、跨模态配对数据(图像-文本对)和交错的多模态数据。
值得一提的是,虽说“Language is not all you need”,但为了让Kosmos-1更能读懂人类的指示,在训练时,研究人员还是专门对其进行了仅使用语言数据的指令调整。
具体而言,就是用(指令,输入,输出)格式的指令数据继续训练模型。
关于更多的细节,请点击查看原文。
4. 没错!真·14cm制程
原文:
https://mp.weixin.qq.com/s/OW7Rsa3Oz0FcuzLt7oYOIg
两年时间,一个90后体制内小哥下班之后只干三件私务,那就是:
手搓CPU!手搓CPU!还是***手搓CPU!
而这个小哥也不陌生,他名叫林乃卫,相信很多读者之前也看过量子位写的[《B站焊武帝爆火出圈:纯手工拼晶体管自制CPU,耗时半年,可跑程序》
时隔一年半,如今千呼万唤始出来,就来康康这爆肝两年的自研CPU终极形态到底是什么?
“底层逻辑、架构、指令集均是自主研发”
话不多说,直接先来看手搓出来的“CPU终极形态”的参数如何:
-
频率:13kHz,超频最大33kHz;
-
ROM:64kB,支持热更新,16位ROM寻址、16位静态数据寻址;
-
内存:系统内存256B、应用内存64kB;
-
IO口数量:78bit(48支持位操作);
-
103条指令,功耗10瓦。
做成这样,成本统共算下来只有2000元左右,若是再刨去电烙铁、示波器这类工具,花在基础器件上的钱还不到1000块。

整体性能方面,小哥表示它和70年代初期的CPU差不多,并且在指令上还要优于当时的CPU。
形象点来说,目前它可以简单刷个屏幕,显示文字、图像,甚至一些小游戏(类似贪吃蛇)也能跑起来。
其实在去年7月份,小哥就已经在B站更新过一个“纯手工自制CPU”的视频,搭建的是CPU雏形,耗时6个月。
不过当时的CPU还仅处于能跑起来的阶段,要运行更复杂的程序还比较困难。
于是小哥就开始了他的手搓“进阶版CPU”历程,在刚制作好的CPU雏形上进行调试维修,这一步他的计划是:
-
把指令增加到100多条;
-
增加了堆栈、 IO 口,运算器的这些比较复杂一点的部件,还有内存管理;
-
可以满足一些复杂的运算;
……
这一把调试维修,直接就整了小哥一年半的时间。
为了有效提高CPU的性能,期间小哥下了“血本”购入了示波器这类专业器材,用来检测整个CPU每一个节点的信号。
然后小哥以最简易的方式去拆除了一些器件,直接把CPU的频率从1kHz提升到33kHz,性能翻了33倍。
话说回来,徒手搓出CPU,小哥可是完全是依靠自己本科就已经掌握的电子领域、IT领域的知识,实打实开发出来的。
从前期的电路仿真、PCB设计到中后期的焊接、调试以及软件编程……小哥一个人独揽一条“CPU生产线”。
(听起来就很头疼对吧)不过这对“爱好技术类手工制作”的小哥来说可就不一样了。
独创技术了解一下~
看过视频的盆友或许都知道,小哥在视频中特别提到了自己的独创双通道内存。

看看这电路图,嗯,话不多说,各位跪好,自行搜索B站视频观看。
5. 大卷积模型 + 大数据集 + 有监督训练!探寻ViT的前身:Big Transfer (BiT)
原文:https://mp.weixin.qq.com/s/tpEEIYkFO_af7NkCAFQvUw
论文地址:https://arxiv.org/pdf/1912.11370.pdf
1 ViT 的前奏:Scale up 卷积神经网络学习通用视觉表示
1.1 背景和动机
使用深度学习实现的强大性能通常需要大量 task-specific 的数据和计算。如果每个任务都经历这样的过程,就会给新任务的训练过程带来非常高昂的代价。迁移学习提供了一种解决方案:我们可以首先完成一个预训练 (Pre-train) 的阶段,即:在一个更大的,更通用的数据集上训练一次网络,然后使用它的权重初始化后续任务,这些任务可以用更少的数据和更少的计算资源来解决。
在本文中,作者重新审视了一个简单的范例,即:在大型有监督数据集上进行预训练 (注意本文是 ECCV 2020 的工作,当时的视觉模型有监督训练还是主流) ,并在目标任务上进行微调。本文的目标不是引入一个新的模型,而是提供一个 training recipe,使用最少的 trick,也能够在许多任务上获得出色的性能,作者称之为 Big Transfer (BiT)。
作者在3种不同规模的数据集上训练网络。最大的 BiT-L 是在 JFT-300M 数据集上训练的,该数据集包含 300M 噪声标记的图片。再将 BiT 迁移到不同的下游任务上。这些任务包括 ImageNet 的 ImageNet-1K,ciremote -10/100 ,Oxford-IIIT Pet,Oxford Flowers-102,以及1000样本的 VTAB-1k 基准。BiT-L 在许多这些任务上都达到了最先进的性能,并且在很少的下游数据可用的情况下惊人地有效。
重要的是,BiT 只需要预训练一次,后续对下游任务的微调成本很低。BiT 不仅需要对每个新任务进行简短的微调协议,而且 BiT 也不需要对新任务进行大量的超参数调优。作者提出了一种设置超参数的启发式方法,在多种任务中表现得很好。除此之外,作者强调了使 Big Transfer 有效的最重要的要素,并深入了解了规模、架构和训练超参数之间的相互作用。
1.2 Big Transfer 上游任务预训练
Big Transfer 上游预训练第一个要素是规模 (Scale)。众所周知,在深度学习中,更大的网络在各自的任务上表现得更好。但是,更大的数据集往往需要更大的架构才能有收益。作者研究了计算预算 (训练时间)*、*架构大小和数据集大小之间的相互作用,在3个大型数据集上训练了3个 BiT 模型:在 ImageNet-1K (1.3M 张图像) 上训练 BiT-S, 在 ImageNet-21K (14M 张图像) 上训练 BiT-M,在 JFT-300M (300M 张图像) 上训练 BiT-M。
Big Transfer 上游预训练第二个要素是 Group Normalization[1] 和权重标准化 (Weight Standardization, WS)[2]。在大多数的视觉模型中,一般使用 BN 来稳定训练,但是作者发现 BN 不利于 Big Transfer。
原因是:
-
在训练大模型时,BN 的性能较差,或者会产生设备间同步成本。
-
由于需要更新运行统计信息,BN 不利于下游任务的迁移。
当 GN 与 WS 结合时,已被证明可以提高 ImageNet 和 COCO 的小 Batch 的训练性能。本文中,作者证明了 GN 和WS 的组合对于大 Batch 的训练是有用的,并且对迁移学习有显著的影响。
1.3 Big Transfer 下游任务迁移
作者提出了一种适用于许多不同下游任务的微调策略。作者不去对每个任务和数据集进行昂贵的超参数搜索,每个任务只尝试一种超参数。作者使用了一种启发式的规则,BiT-HyperRule,选择最重要的超参数进行调优。作者发现,为每个任务设置以下超参数很重要:训练 Epoch、分辨率以及是否使用 MixUp 正则化。作者使用 BiT-HyperRule 处理超过20个任务,训练集从每类1个样本到超过1M个样本。
在微调中,作者使用以下标准数据预处理:将图像大小调整为一个正方形,裁剪出一个较小的随机正方形,并在训练时随机水平翻转图像。在测试时,只将图像调整为固定大小。这个固定大小作者设置为把分辨率提高一点,因为作者发现这样更适合迁移学习。
此外,作者还发现 MixUp 对于预训练 BiT 是没有用的,可能是由于训练数据比较丰富。但是,它有时对下游的迁移是有效的。令人惊讶的是,作者在下游调优期间不使用以下任何形式的正则化技术 (regularization):权值衰减到零、权值衰减到初始参数或者 Dropout。尽管网络非常大,BiT 有9.28亿个参数,但是却在没有正则化的情况下,性能惊人好。作者发现更大的数据集训练更长的时间,可以提供足够的正则化。
1.4 上游任务预训练实验设置
作者在3个大型数据集上训练了3个 BiT 模型:在 ImageNet-1K (1.3M 张图像) 上训练 BiT-S, 在 ImageNet-21K (14M 张图像) 上训练 BiT-M,在 JFT-300M (300M 张图像) 上训练 BiT-M。注意:“-S/M/L”后缀指的是预训练数据集的大小和训练时长,而不是架构的大小。作者用几种架构大小训练 BiT,最大的是 ResNet152x4。
所有的 BiT 模型都使用原始的 ResNet-v2 架构,并在所有卷积层中使用 Group Normalization + Weight Standardization。
1.5 下游任务迁移实验设置
使用的数据集分别是:ImageNet-1K, CIFAR10/100, Oxford-IIIT Pet 和 Oxford Flowers-102。这些数据集在图像总数、输入分辨率和类别性质方面存在差异,从 ImageNet 和 CIFAR 中的一般对象类别到 Pet 和 Flowers 中的细粒度类别。
为了进一步评估 BiT 学习到的表征的普遍性,作者在 Visual Task Adaptation Benchmark (VTAB) 上进行评估。VTAB 由19个不同的视觉任务组成,每个任务有1000个训练样本。这些任务被分为3组:natural, specialized and structured,VTAB-1k 分数是这19项任务的平均识别表现。
下游任务迁移实验中,大多数的超参数在所有数据集中都是固定的,但是训练长度、分辨率和 MixUp 的使用取决于任务图像分辨率和训练集大小。
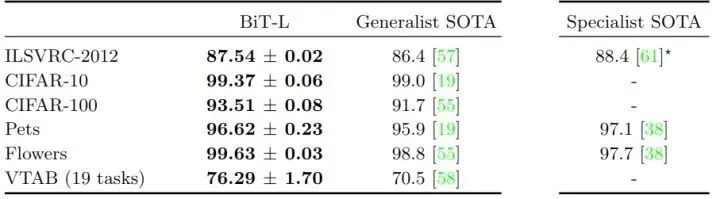
1.6 标准计算机视觉 Benchmark 实验结果
作者在标准基准上评估 BiT-L,对比的结果主要有2类:Generalist SOTA 指的是执行任务独立的预训练的结果,Specialist SOTA 指的是对每个任务分别进行预训练的结果。Specialist 的表征是非常有效的,但每个任务需要大量的训练成本。相比之下,Generalist 的表征只需要一次大规模的训练,然后就只有一个廉价的微调阶段。
受到在 JFT-300M 上训练 BiT-L 的结果的启发,作者还在公开的 ImageNet-21K 数据集上训练模型。对于 ImageNet-1K 这种大规模的数据集,有一些众所周知的,稳健的训练过程。但对于 ImageNet-21K 这种超大规模的数据集,有14,197,122张训练数据,包含21841个类别,在2020年,对于如此庞大的数据集,目前还没有既定的训练程序,本文作者提供了一些指导方针如下:
-
训练时长:增加训练时长和预算。
-
权重衰减:较低的权重衰减可以导致明显的加速收敛,但是模型最终性能不佳。这种反直觉的行为源于权值衰减和归一化层的相互作用。weight decay 变低之后,导致权重范数的增加,这使得有效学习率下降。这种效应会给人一种更快收敛的印象,但最终会阻碍进一步的进展。为了避免这种影响,需要一个足够大的权值衰减,作者在整个过程中使用10−4。
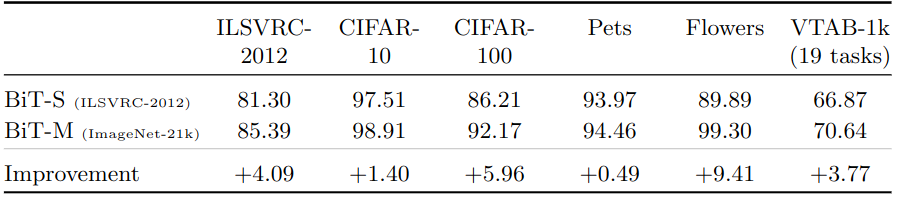
如下图2所示是与 ImageNet-1K 相比,在 ImageNet-21K 数据集上进行预训练时提高了精度,两种模型都是 ResNet152x4。
1.7 单个数据集更少数据的实验结果
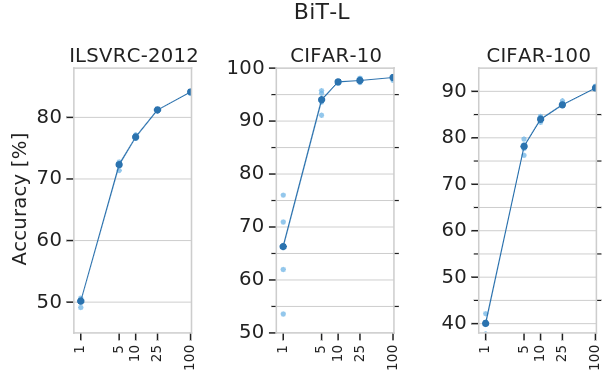
作者研究了成功转移 BiT-L 所需的下游数据的数量。作者使用 ImageNet-1K、CIFAR-10 和 CIFAR-100 的子集传输BiT-L,每个类减少到1个训练样本。作者还对19个 VTAB-1K 任务进行了更广泛的评估,每个任务有1000个训练样本。实验结果如下图3所示,令人惊讶的是,即使每个类只有很少的样本,BiT-L 也可以表现出强大的性能,并迅速接近全数据集的性能。特别是,在 ImageNet-1K 上,每个类只有5个标记样本时,其 top-1 的准确度达到 72.0%,而在100个样本时, top-1 的准确度达到 84.1%。在 CIFAR-100 中,我们每个类只有10个样本, top-1 的准确度达到 82.6%。
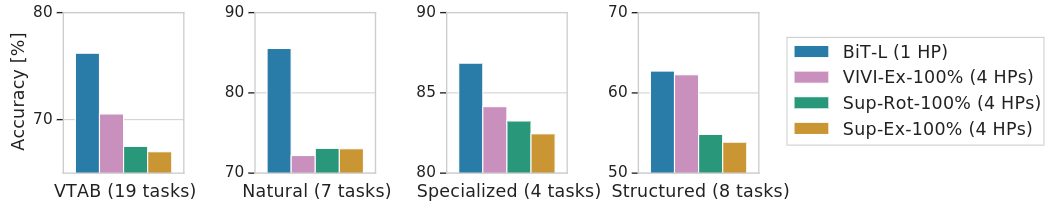
如下图4所示是 BiT-L 在19个 VTAB-1k 任务上的性能。在研究 VTAB-1k 任务子集的性能时,BiT 在 natural, specialized 和 structured 任务上是最好的。在上游预训练期间使用视频数据的 VIVIEx-100% 模型在结构化任务上展示出非常相似的性能。
1.8 ObjectNet:真实世界数据集的实验结果
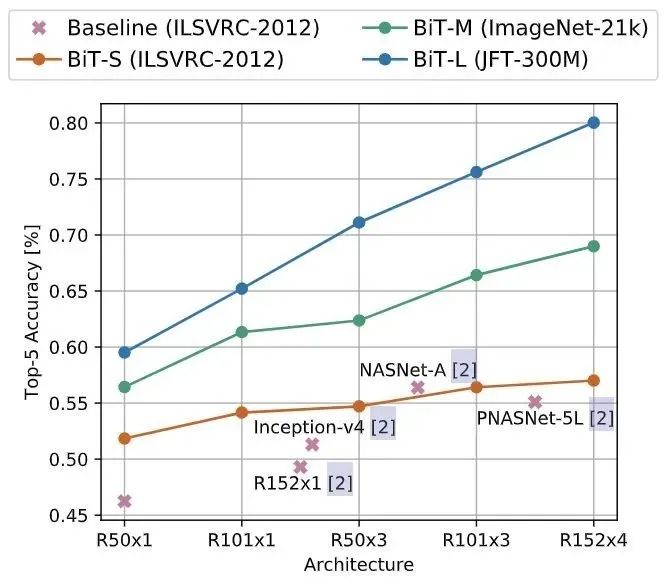
ObjectNet 数据集是一个仅包含测试集的,非常类似于现实场景的数据集,总共有313个类,其中113个与ImageNet-1K 重叠。实验结果如图5所示,更大的结构和对更多数据的预训练可以获得更高的准确性。作者还发现缩放模型对于实现 80% top-5 以上的精度非常重要。
1.9 目标检测实验结果
数据集使用 COCO,检测头使用 RetinaNet,使用预训练的 BiT 模型 ResNet-101x3 作为 Backbone,如下图6所示是实验结果。BiT 模型优于标准 ImageNet 预训练的模型,可以看到在 ImageNet-21K 上进行预训练,平均精度 (AP) 提高了1.5个点,而在 JFT-300M 上进行预训练,则进一步提高了0.6个点。

总结
本文回顾了在大数据集上进行预训练的范式,并且提出了一种简单的方法 Scale up 了预训练的数据集,得到的模型获得了很好的下游任务的性能,作者称之为 Big Transfer (BiT)。通过组合几个精心的组件,训练和微调的策略,并使用简单的迁移学习方法平衡复杂性和性能,BiT 在超过20个数据集上实现了强大的性能。
6. 神经网络INT8量化部署实战教程
原文:
https://mp.weixin.qq.com/s/oxHnjABZG2xdsEFSfcJYqQ
开篇
刚开始接触神经网络量化是2年前那会,用NCNN和TVM在树莓派上部署一个简单的SSD网络。那个时候使用的量化脚本是参考于TensorRT和NCNN的PTQ量化(训练后量化)模式,使用交叉熵的方式对模型进行量化,最终在树莓派3B+上部署一个简单的分类模型(识别剪刀石头布静态手势)。
转眼间过了这么久啦,神经网络量化应用已经完全实现大面积落地了、相比之前成熟多了!
我工作的时候虽然也简单接触过量化,但感觉还远远不够,趁着最近项目需要,重新再学习一下,也打算把重新学习的路线写成一篇系列文,分享给大家。
本篇系列文的主要内容计划从头开始梳理一遍量化的基础知识以及代码实践。因为对TensorRT比较熟悉,会主要以TensorRT的量化方式进行描述以及讲解。不过TensorRT由于是闭源工具,内部的实现看不到,咱们也不能两眼一抹黑。所以也打算参考Pytorch、NCNN、TVM、TFLITE的量化op的现象方式学习和实践一下。
当然这只是学习计划,之后可能也会变动。对于量化我也是学习者,既然要用到这个技术,必须要先理解其内部原理。而且接触了挺长时间量化,感觉这里面学问还是不少。好记性不如烂笔头,写点东西记录下,也希望这系列文章在能够帮助大家的同时,抛砖引玉,一起讨论、共同进步。
参考了以下关于量化的一些优秀文章,不完全统计列了一些,推荐感兴趣的同学阅读:
-
神经网络量化入门--基本原理(https://zhuanlan.zhihu.com/p/149659607)
-
从TensorRT与ncnn看卷积网络int8量化(https://zhuanlan.zhihu.com/p/387072703)
-
模型压缩:模型量化打怪升级之路 - 1 工具篇(https://zhuanlan.zhihu.com/p/355598250)
-
NCNN Conv量化详解(一)(https://zhuanlan.zhihu.com/p/71881443)
当然在学习途中,也认识了很多在量化领域经验丰富的大佬(田子宸、JermmyXu等等),嗯,这样前进路上也就不孤单了。
OK,废话不多说开始吧。
Why量化
我们都知道,训练好的模型的权重一般来说都是FP32也就是单精度浮点型,在深度学习训练和推理的过程中,最常用的精度就是FP32。当然也会有FP64、FP16、BF16、TF32等更多的精度:
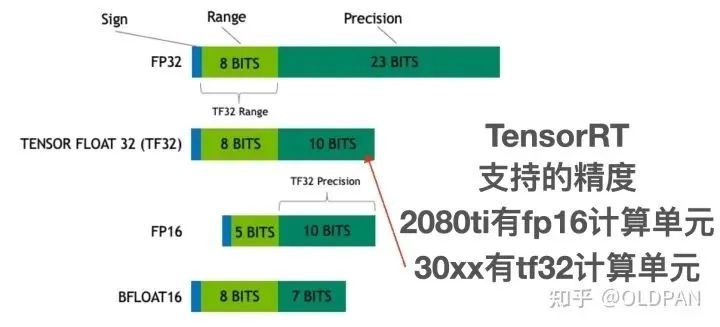
FP32 是单精度浮点数,用8bit 表示指数,23bit 表示小数;FP16半精度浮点数,用5bit 表示指数,10bit 表示小数;BF16是对FP32单精度浮点数截断数据,即用8bit 表示指数,7bit 表示小数。TF32 是一种截短的 Float32 数据格式,将 FP32 中 23 个尾数位截短为 10 bits,而指数位仍为 8 bits,总长度为 19 (=1 + 8 + 10) bits。
对于浮点数来说,指数位表示该精度可达的动态范围,而尾数位表示精度。之前的一篇文章中提到,FP16的普遍精度是~5.96e−8 (6.10e−5) … 65504,而我们模型中的FP32权重有部分数值是1e-10级别。这样从FP32->FP16会导致部分精度丢失,从而模型的精度也会下降一些。
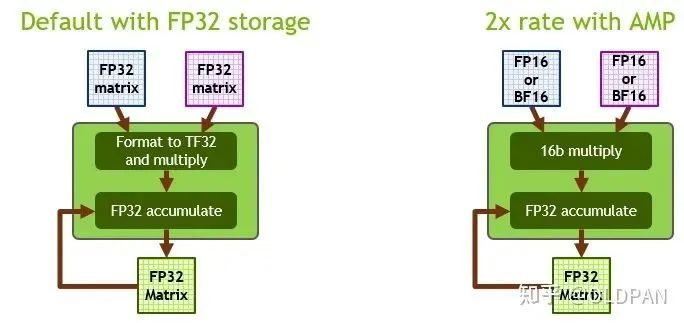
其实从FP32->FP16也是一种量化,只不过因为FP32->FP16几乎是无损的(CUDA中使用__float2half直接进行转换),不需要calibrator去校正、更不需要retrain。
而且FP16的精度下降对于大部分任务影响不是很大,甚至有些任务会提升。NVIDIA对于FP16有专门的Tensor Cores可以进行矩阵运算,相比FP32来说吞吐量提升一倍。

实际点来说,量化就是将我们训练好的模型,不论是权重、还是计算op,都转换为低精度去计算。因为FP16的量化很简单,所以实际中我们谈论的量化更多的是INT8的量化,当然也有3-bit、4-bit的量化,不过目前来说比较常见比较实用的,也就是INT8量化了,之后的重点也是INT8量化。
那么经过INT8量化后的模型:
-
模型容量变小了,这个很好理解,FP32的权重变成INT8,大小直接缩了4倍
-
模型运行速度可以提升,实际卷积计算的op是INT8类型,在特定硬件下可以利用INT8的指令集去实现高吞吐,不论是GPU还是INTEL、ARM等平台都有INT8的指令集优化
-
对于某些设备,使用INT8的模型耗电量更少,对于嵌入式侧端设备来说提升是巨大的
所以说,随着我们模型越来越大,需求越来越高,模型的量化自然是少不了的一项技术。
如果你担心INT8量化对于精度的影响,我们可以看下NVIDIA量化研究的一些结论: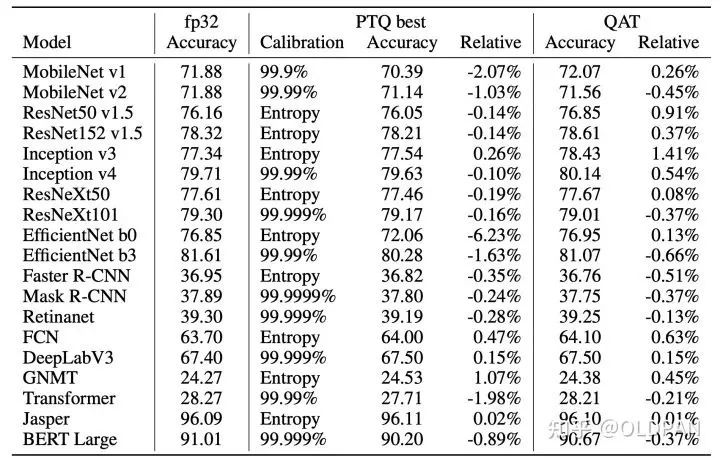
量化现状
量化技术已经广泛应用于实际生产环境了,也有很多大厂开源了其量化方法。不过比较遗憾的是目前这些方法比较琐碎,没有一套比较成熟比较完善的量化方案,使用起来稍微有点难度。不过我们仍可以从这些框架中学习到很多。
谷歌是比较早进行量化尝试的大厂了,感兴趣的可以看下Google的白皮书Quantizing deep convolutional networks for efficient inference: A whitepaper以及Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference。
TensorFlow很早就支持了量化训练,而TFLite也很早就支持了后训练量化,感兴趣的可以看下TFLite的量化规范 (https://www.tensorflow.org/lite/performance/quantization_spec) ,目前TensorRT支持TensorFlow训练后量化的导出的模型。
TensorRT
TensorRT在2017年公布了自己的后训练量化方法,不过没有开源,NCNN按照这个思想实现了一个,也特别好用。不过目前TensorRT8也支持直接导入通过ONNX导出的QTA好的模型,使用上方便了不少,之后会重点讲下。

TVM
TVM有自己的INT8量化操作,可以跑量化,我们也可以添加自己的算子。不过TVM目前只支持PTQ,可以通过交叉熵或者percentile的方式进行校准。不过如果动手能力强的话,应该可以拿自己计算出来的scale值传入TVM去跑,应该也有人这样做过了。
比较有参考意义的一篇:
-
ViT-int8 on TVM:提速4.6倍,比TRT快1.5倍(https://zhuanlan.zhihu.com/p/365686106)
当然还有很多优秀的量化框架,想看详细的可以看这篇(https://zhuanlan.zhihu.com/p/355598250),后续如果涉及到具体知识点也会再提到。
更多关于量化的基础理论和技巧,请点击原文查看。
———————End———————
你可以添加微信:rtthread2020 为好友,注明:公司+姓名,拉进RT-Thread官方微信交流群!
↓点击阅读原文
爱我就请给我在看
原文标题:【AI简报20230304期】 ChatGPT API 正式发布、2023年中国人工智能产业趋势报告
-
RT-Thread
+关注
关注
31文章
1285浏览量
40062
原文标题:【AI简报20230304期】 ChatGPT API 正式发布、2023年中国人工智能产业趋势报告
文章出处:【微信号:RTThread,微信公众号:RTThread物联网操作系统】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
华为推动中国人工智能框架生态高速发展
软通动力入选《人工智能数据标注产业图谱》
2025 福布斯中国人工智能科技企业 TOP 50 评选正式启动

名单公布!【书籍评测活动NO.44】AI for Science:人工智能驱动科学创新
报名开启!深圳(国际)通用人工智能大会将启幕,国内外大咖齐聚话AI
OpenAI 深夜抛出王炸 “ChatGPT- 4o”, “她” 来了
达闼机器人荣登“2024福布斯中国人工智能科技企业TOP 50”

Nullmax荣登「中国人工智能与大数据产业最佳投资案例TOP10」榜单

爱芯元智荣登“2024福布斯中国人工智能科技企业TOP 50”榜单

云天励飞荣誉入选“2024福布斯中国人工智能科技企业”







 工商网监
工商网监
评论