 OpenHarmony 3.2 Beta Audio——音频渲染
OpenHarmony 3.2 Beta Audio——音频渲染
点击蓝字 ╳ 关注我们

巴延兴
深圳开鸿数字产业发展有限公司
资深OS框架开发工程师
一、简介
二、目录
audio_framework
├── frameworks
│ ├── js #js 接口
│ │ └── napi
│ │ └── audio_renderer #audio_renderer NAPI接口
│ │ ├── include
│ │ │ ├── audio_renderer_callback_napi.h
│ │ │ ├── renderer_data_request_callback_napi.h
│ │ │ ├── renderer_period_position_callback_napi.h
│ │ │ └── renderer_position_callback_napi.h
│ │ └── src
│ │ ├── audio_renderer_callback_napi.cpp
│ │ ├── audio_renderer_napi.cpp
│ │ ├── renderer_data_request_callback_napi.cpp
│ │ ├── renderer_period_position_callback_napi.cpp
│ │ └── renderer_position_callback_napi.cpp
│ └── native #native 接口
│ └── audiorenderer
│ ├── BUILD.gn
│ ├── include
│ │ ├── audio_renderer_private.h
│ │ └── audio_renderer_proxy_obj.h
│ ├── src
│ │ ├── audio_renderer.cpp
│ │ └── audio_renderer_proxy_obj.cpp
│ └── test
│ └── example
│ └── audio_renderer_test.cpp
├── interfaces
│ ├── inner_api #native实现的接口
│ │ └── native
│ │ └── audiorenderer #audio渲染本地实现的接口定义
│ │ └── include
│ │ └── audio_renderer.h
│ └── kits #js调用的接口
│ └── js
│ └── audio_renderer #audio渲染NAPI接口的定义
│ └── include
│ └── audio_renderer_napi.h
└── services #服务端
└── audio_service
├── BUILD.gn
├── client #IPC调用中的proxy端
│ ├── include
│ │ ├── audio_manager_proxy.h
│ │ ├── audio_service_client.h
│ └── src
│ ├── audio_manager_proxy.cpp
│ ├── audio_service_client.cpp
└── server #IPC调用中的server端
├── include
│ └── audio_server.h
└── src
├── audio_manager_stub.cpp
└──audio_server.cpp三、音频渲染总体流程
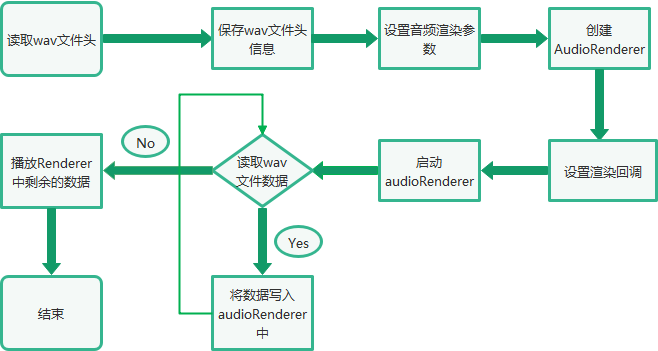
四、Native接口使用
bool TestPlayback(int argc, char *argv[]) const
{
FILE* wavFile = fopen(path, "rb");
//读取wav文件头信息
size_t bytesRead = fread(&wavHeader, 1, headerSize, wavFile);
//设置AudioRenderer参数
AudioRendererOptions rendererOptions = {};
rendererOptions.streamInfo.encoding = AudioEncodingType::ENCODING_PCM;
rendererOptions.streamInfo.samplingRate = static_cast(wavHeader.SamplesPerSec);
rendererOptions.streamInfo.format = GetSampleFormat(wavHeader.bitsPerSample);
rendererOptions.streamInfo.channels = static_cast(wavHeader.NumOfChan);
rendererOptions.rendererInfo.contentType = contentType;
rendererOptions.rendererInfo.streamUsage = streamUsage;
rendererOptions.rendererInfo.rendererFlags = 0;
//创建AudioRender实例
unique_ptr audioRenderer = AudioRenderer::Create(rendererOptions);
shared_ptr cb1 = make_shared();
//设置音频渲染回调
ret = audioRenderer->SetRendererCallback(cb1);
//InitRender方法主要调用了audioRenderer实例的Start方法,启动音频渲染
if (!InitRender(audioRenderer)) {
AUDIO_ERR_LOG("AudioRendererTest: Init render failed");
fclose(wavFile);
return false;
}
//StartRender方法主要是读取wavFile文件的数据,然后通过调用audioRenderer实例的Write方法进行播放
if (!StartRender(audioRenderer, wavFile)) {
AUDIO_ERR_LOG("AudioRendererTest: Start render failed");
fclose(wavFile);
return false;
}
//停止渲染
if (!audioRenderer->Stop()) {
AUDIO_ERR_LOG("AudioRendererTest: Stop failed");
}
//释放渲染
if (!audioRenderer->Release()) {
AUDIO_ERR_LOG("AudioRendererTest: Release failed");
}
//关闭wavFile
fclose(wavFile);
return true;
}五、调用流程
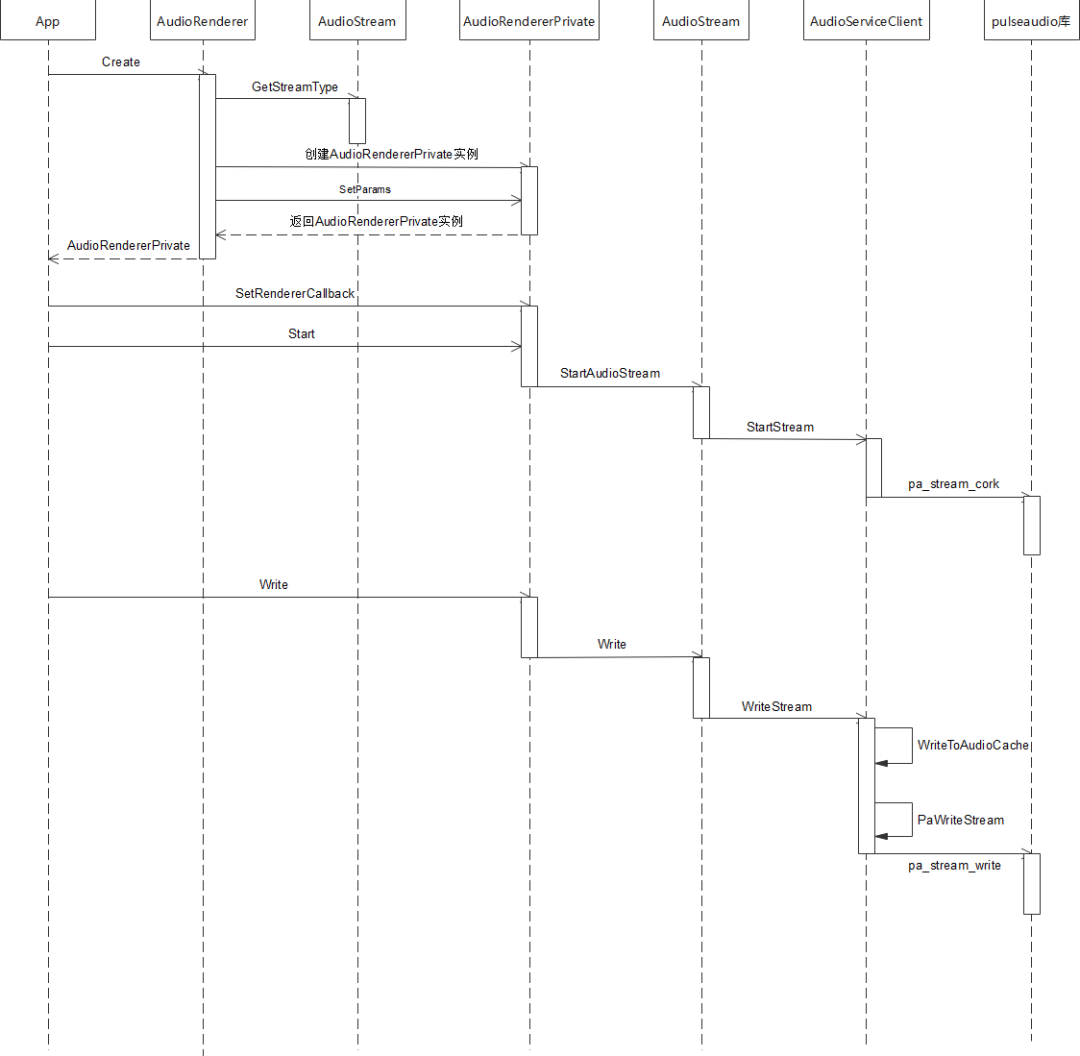
std::unique_ptr AudioRenderer::Create(const std::string cachePath,
const AudioRendererOptions &rendererOptions, const AppInfo &appInfo)
{
ContentType contentType = rendererOptions.rendererInfo.contentType;
StreamUsage streamUsage = rendererOptions.rendererInfo.streamUsage;
AudioStreamType audioStreamType = AudioStream::GetStreamType(contentType, streamUsage);
auto audioRenderer = std::make_unique(audioStreamType, appInfo);
if (!cachePath.empty()) {
AUDIO_DEBUG_LOG("Set application cache path");
audioRenderer->SetApplicationCachePath(cachePath);
}
audioRenderer->rendererInfo_.contentType = contentType;
audioRenderer->rendererInfo_.streamUsage = streamUsage;
audioRenderer->rendererInfo_.rendererFlags = rendererOptions.rendererInfo.rendererFlags;
AudioRendererParams params;
params.sampleFormat = rendererOptions.streamInfo.format;
params.sampleRate = rendererOptions.streamInfo.samplingRate;
params.channelCount = rendererOptions.streamInfo.channels;
params.encodingType = rendererOptions.streamInfo.encoding;
if (audioRenderer->SetParams(params) != SUCCESS) {
AUDIO_ERR_LOG("SetParams failed in renderer");
audioRenderer = nullptr;
return nullptr;
}
return audioRenderer;
}int32_t AudioRendererPrivate::SetRendererCallback(const std::shared_ptr &callback)
{
RendererState state = GetStatus();
if (state == RENDERER_NEW || state == RENDERER_RELEASED) {
return ERR_ILLEGAL_STATE;
}
if (callback == nullptr) {
return ERR_INVALID_PARAM;
}
// Save reference for interrupt callback
if (audioInterruptCallback_ == nullptr) {
return ERROR;
}
std::shared_ptr cbInterrupt =
std::static_pointer_cast(audioInterruptCallback_);
cbInterrupt->SaveCallback(callback);
// Save and Set reference for stream callback. Order is important here.
if (audioStreamCallback_ == nullptr) {
audioStreamCallback_ = std::make_shared();
if (audioStreamCallback_ == nullptr) {
return ERROR;
}
}
std::shared_ptr cbStream =
std::static_pointer_cast(audioStreamCallback_);
cbStream->SaveCallback(callback);
(void)audioStream_->SetStreamCallback(audioStreamCallback_);
return SUCCESS;
}bool AudioRendererPrivate::Start(StateChangeCmdType cmdType) const
{
AUDIO_INFO_LOG("AudioRenderer::Start");
RendererState state = GetStatus();
AudioInterrupt audioInterrupt;
switch (mode_) {
case InterruptMode:
audioInterrupt = sharedInterrupt_;
break;
case InterruptMode:
audioInterrupt = audioInterrupt_;
break;
default:
break;
}
AUDIO_INFO_LOG("AudioRenderer: %{public}d, streamType: %{public}d, sessionID: %{public}d",
mode_, audioInterrupt.streamType, audioInterrupt.sessionID);
if (audioInterrupt.streamType == STREAM_DEFAULT || audioInterrupt.sessionID == INVALID_SESSION_ID) {
return false;
}
int32_t ret = AudioPolicyManager::GetInstance().ActivateAudioInterrupt(audioInterrupt);
if (ret != 0) {
AUDIO_ERR_LOG("AudioRendererPrivate::ActivateAudioInterrupt Failed");
return false;
}
return audioStream_->StartAudioStream(cmdType);
}bool AudioStream::StartAudioStream(StateChangeCmdType cmdType)
{
int32_t ret = StartStream(cmdType);
resetTime_ = true;
int32_t retCode = clock_gettime(CLOCK_MONOTONIC, &baseTimestamp_);
if (renderMode_ == RENDER_MODE_CALLBACK) {
isReadyToWrite_ = true;
writeThread_ = std::make_unique<std::thread>(&AudioStream::WriteCbTheadLoop, this);
} else if (captureMode_ == CAPTURE_MODE_CALLBACK) {
isReadyToRead_ = true;
readThread_ = std::make_unique<std::thread>(&AudioStream::ReadCbThreadLoop, this);
}
isFirstRead_ = true;
isFirstWrite_ = true;
state_ = RUNNING;
AUDIO_INFO_LOG("StartAudioStream SUCCESS");
if (audioStreamTracker_) {
AUDIO_DEBUG_LOG("AudioStream:Calling Update tracker for Running");
audioStreamTracker_->UpdateTracker(sessionId_, state_, rendererInfo_, capturerInfo_);
}
return true;
}int32_t AudioServiceClient::StartStream(StateChangeCmdType cmdType)
{
int error;
lock_guard lockdata(dataMutex);
pa_operation *operation = nullptr;
pa_threaded_mainloop_lock(mainLoop);
pa_stream_state_t state = pa_stream_get_state(paStream);
streamCmdStatus = 0;
stateChangeCmdType_ = cmdType;
operation = pa_stream_cork(paStream, 0, PAStreamStartSuccessCb, (void *)this);
while (pa_operation_get_state(operation) == PA_OPERATION_RUNNING) {
pa_threaded_mainloop_wait(mainLoop);
}
pa_operation_unref(operation);
pa_threaded_mainloop_unlock(mainLoop);
if (!streamCmdStatus) {
AUDIO_ERR_LOG("Stream Start Failed");
ResetPAAudioClient();
return AUDIO_CLIENT_START_STREAM_ERR;
} else {
AUDIO_INFO_LOG("Stream Started Successfully");
return AUDIO_CLIENT_SUCCESS;
}
}int32_t AudioRendererPrivate::Write(uint8_t *buffer, size_t bufferSize)
{
return audioStream_->Write(buffer, bufferSize);
}size_t AudioStream::Write(uint8_t *buffer, size_t buffer_size)
{
int32_t writeError;
StreamBuffer stream;
stream.buffer = buffer;
stream.bufferLen = buffer_size;
isWriteInProgress_ = true;
if (isFirstWrite_) {
if (RenderPrebuf(stream.bufferLen)) {
return ERR_WRITE_FAILED;
}
isFirstWrite_ = false;
}
size_t bytesWritten = WriteStream(stream, writeError);
isWriteInProgress_ = false;
if (writeError != 0) {
AUDIO_ERR_LOG("WriteStream fail,writeError:%{public}d", writeError);
return ERR_WRITE_FAILED;
}
return bytesWritten;
}size_t AudioServiceClient::WriteStream(const StreamBuffer &stream, int32_t &pError)
{
size_t cachedLen = WriteToAudioCache(stream);
if (!acache.isFull) {
pError = error;
return cachedLen;
}
pa_threaded_mainloop_lock(mainLoop);
const uint8_t *buffer = acache.buffer.get();
size_t length = acache.totalCacheSize;
error = PaWriteStream(buffer, length);
acache.readIndex += acache.totalCacheSize;
acache.isFull = false;
if (!error && (length >= 0) && !acache.isFull) {
uint8_t *cacheBuffer = acache.buffer.get();
uint32_t offset = acache.readIndex;
uint32_t size = (acache.writeIndex - acache.readIndex);
if (size > 0) {
if (memcpy_s(cacheBuffer, acache.totalCacheSize, cacheBuffer + offset, size)) {
AUDIO_ERR_LOG("Update cache failed");
pa_threaded_mainloop_unlock(mainLoop);
pError = AUDIO_CLIENT_WRITE_STREAM_ERR;
return cachedLen;
}
AUDIO_INFO_LOG("rearranging the audio cache");
}
acache.readIndex = 0;
acache.writeIndex = 0;
if (cachedLen < stream.bufferLen) {
StreamBuffer str;
str.buffer = stream.buffer + cachedLen;
str.bufferLen = stream.bufferLen - cachedLen;
AUDIO_DEBUG_LOG("writing pending data to audio cache: %{public}d", str.bufferLen);
cachedLen += WriteToAudioCache(str);
}
}
pa_threaded_mainloop_unlock(mainLoop);
pError = error;
return cachedLen;
}六、总结
原文标题:OpenHarmony 3.2 Beta Audio——音频渲染
文章出处:【微信公众号:OpenAtom OpenHarmony】欢迎添加关注!文章转载请注明出处。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
鸿蒙
+关注
关注
57文章
2405浏览量
43229 -
OpenHarmony
+关注
关注
25文章
3760浏览量
16912
原文标题:OpenHarmony 3.2 Beta Audio——音频渲染
文章出处:【微信号:gh_e4f28cfa3159,微信公众号:OpenAtom OpenHarmony】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
大联大品佳集团推出基于达发科技(Airoha)产品的LE Audio耳机方案
的LE Audio耳机方案的展示板图 LE Audio(低功耗音频)技术标准的诞生为业内带来低复杂性通信编解码器(LC3)、多重串流音频、助听器功能扩展和广播

e络盟大幅扩充PUI Audio产品系列以强化音频产品组合
安富利旗下全球电子元器件产品与解决方案分销商e络盟大幅扩充了 PUI Audio产品种类。作为音频、触觉反馈及传感器解决方案领域的全球创新者和供应商,PUI Audio产品的加入进一步丰富e络盟的产品组合。新扩展的产品线使客户能

请问cc3200 audio boosterpack音频采集是不是底噪很大?
基于TLV320AIC3254的音频开发办,我烧入wifi_audio_app例程(例程中关掉板载咪头输入,并将音量调到最大),另两入输入接口没有接音频信号,但是板子一直吱吱吱的响,是板子本身底噪就这么大吗?
发表于 10-25 06:28
TPS6595 Audio Codec输出音频偶发混入7Khz杂波是怎么回事?
主芯片是DM3730, 音频使用的是TPS65950的Audio 外设。
DM3730使用MCBSP输出8Khz音频数据,通过I2C设置 TPS65950相关寄存器。 采用Audio
发表于 10-15 07:08
Auracast广播音频创造全新音频体验
音频(LE Audio)发布以来,Auracast广播音频在音频市场持续发力,对音频设备和相关产品产生了深远影响。
【龙芯2K0300蜂鸟板试用】OpenHarmony代码
fetch origin OpenHarmony-3.2-Release:OpenHarmony-3.2-Release
git switch OpenHarmony-3.2
发表于 09-18 11:42
LE Audio音频技术助推影音、助听市场,蓝牙+助听芯片成为趋势
3.0版本支持高速数据传输和更低的功耗,蓝牙4.0版本引入了低功耗模式(BLE),蓝牙5.0版本提高了传输速度。再到蓝牙5.2版本提出了LE Audio,增强了蓝牙音频体验。 进入无损时代,LE Audio带来低延迟、高音质体验
HarmonyOS NEXT Developer Beta1中的Kit
管理服务)、Network Kit(网络服务)等。
媒体相关Kit开放能力:Audio Kit(音频服务)、Media Library Kit(媒体文件管理服务)等。
图形相关Kit开放能力
发表于 06-26 10:47
使用提供的esp_audio_codec 的库组件时,不能将AAC音频解码回PCM音频,为什么?
使用提供的esp_audio_codec 的库组件时,能够将PCM音频编码为AAC音频,但是不能将AAC音频解码回PCM音频,是为什么导致的
发表于 06-05 06:39
鸿蒙开发接口媒体:【@ohos.multimedia.audio (音频管理)】
音频管理提供管理音频的一些基础能力,包括对音频音量、音频设备的管理,以及对音频数据的采集和渲染等

HarmonyOS实战开发-合理选择条件渲染和显隐控制
开发者可以通过条件渲染或显隐控制两种方式来实现组件在显示和隐藏间的切换。本文从两者原理机制的区别出发,对二者适用场景分别进行说明,实现相应适用场景的示例并给出性能对比数据。
原理机制
条件渲染
发表于 05-10 15:16
【RTC程序设计:实时音视频权威指南】音频采集与渲染
在进行视频的采集与渲染的同时,我们还需要对音频进行实时的采集和渲染。对于rtc来说,音频的实时性和流畅性更加重要。
声音是由于物体在空气中振动而产生的压力波,声波的存在依赖于空气介质,
发表于 04-28 21:00
【开源鸿蒙】下载OpenHarmony 4.1 Release源代码
本文介绍了如何下载开源鸿蒙(OpenHarmony)操作系统 4.1 Release版本的源代码,该方法同样可以用于下载OpenHarmony最新开发版本(master分支)或者4.0 Release、3.2 Release等发
鸿蒙ArkUI开发学习:【渲染控制语法】
ArkUI开发框架是一套构建 HarmonyOS / OpenHarmony 应用界面的声明式UI开发框架,它支持程序使用 `if/else` 条件渲染, `ForEach` 循环渲染以及 `LazyForEach` 懒加载

3.2W单声道D类音频功率放大器TPA2037D1数据表
电子发烧友网站提供《3.2W单声道D类音频功率放大器TPA2037D1数据表.pdf》资料免费下载
发表于 03-20 09:17
•0次下载






 工商网监
工商网监
评论