 深度解读!VSLAM与VIO的3D建图,重定位与世界观综述
深度解读!VSLAM与VIO的3D建图,重定位与世界观综述
本文重点描述VSLAM与VIO的3D建图,重定位,回环与世界观,从小伙伴们最关心的工程和商用搞钱的角度进行详细分析,并从技术和实现部分详细描述各种类型SLAM在这块的差异。
首先来4个基础逻辑:
SLAM本质是数学问题,是一个科学家与工程师可以控制的数学问题,本质不是玄学,实现需要大量的数学知识与工具,需要极强的代码功底与硬软件开发能力。
无论对SLAM系统如何分割,建图仍是位姿估计的副产品。
当下SLAM主流落地就两类:二维三维导航建图与具体操作(如抓取)
无论任何SLAM系统,精度无论多高,本质都是求解非线性优化的最优解,势必存在误差,且随时长与探索距离递增。
三相性:开销/鲁棒性/精度已经反复提过了,这个部分我们也实现了,本文的重点在于描述VIO/VSLAM的世界观。
01
主流SLAM相关工作分类
首先,稀疏点云不是世界观,即使稀疏点云有完整而正确的深度,也是难以被直观理解的机器语言,这块在学界和业界都得到了反复的验证,目前先对所有SLAM系统做一个基本的分类,(二维单点激光SLAM与矢量重定位不放在里面,是原点和古早的系统类别):
(1) 以VINS,ORB3为代表的间接法(或特征点法)构建的系统,或LSD-SLAM与SD-VIS这一类并不直接的直接法
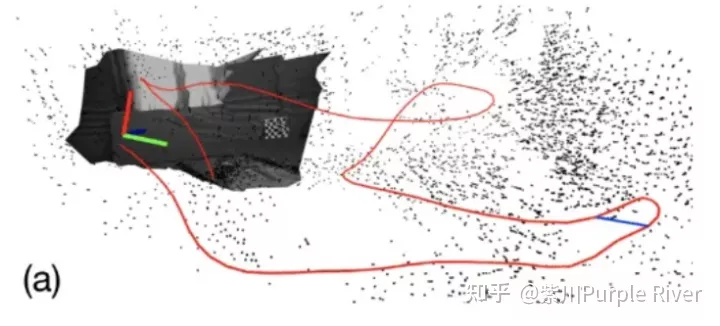
如上图所示,从非常直观的感受就能感觉到,这种稀疏的点云,即使构建了完整和正确的深度,也是不容易被直观理解的机器语言,相对的商业价值貌似较低。其实这种认知是不完善的,后续会进行详述。
(2)线扫/固态激光SLAM

线扫或者固态激光生成的点云相对稠密,距离和范围较大,而且可以建立世界观相对本端的误差较小的深度,也是最容易理解的,广泛应用于汽车与自动驾驶行业,还有一定的缺陷是没有更加稠密和丰富的纹理(类似真实世界)。
这一类激光SLAM大多数由多种(4-5种)传感器的融合卡尔曼滤波构成:IEKF或MSCKF,然后对点云进行如ICP类型的暴力匹配,目前并行化的工作也做得相当好了,从业人员很多。问题在于当下最主流的L4级自动驾驶本身是一个非常卷的领域,并慢慢开始走向了2个路径:1是本端基础感知+AI目标分类结合HD高精地图(HD地图目前也是一个很卷的东西(类似以前网吧接AI公司的单做标注),2是具有极强感知能力的本地多传感器融合融态结合简单的地图,但是路径2虽然厉害但是当前无论是芯片各种U上的算力还是算法本身,都离真正的商用有距离(同时路径1和2都有非常麻烦的法律法规问题)。接下来几年这块正在走向L2变为主机厂的系统支撑方,也许只有等到未来的某一天某篇真正划时代的论文之后,才能迎来真正的大批量落地。
(3)紧耦合同步优化直接法-DSO系,注意此处的紧耦合并不意指不同传感器间的紧耦合,任何信息,包括同类传感器间的信息同样是可以被耦合的,整个处理流和pipeline也是可以被紧耦合的。
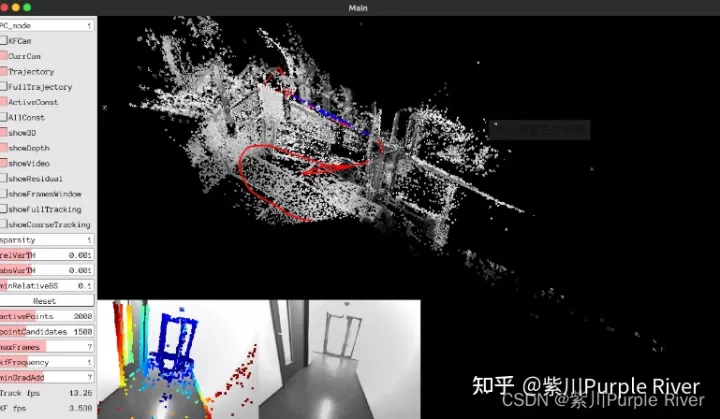
效果如上图所示
这块学术上带头的是我很喜欢和尊敬的Daniel Cremer教授(TUM),他的思维是用纯视觉完成整个世界观的构建,甚至在未来大面积的去替换雷达。
这条路径的基础特点是用视觉构建了半稀疏的世界观,而且随着算力的提升,点云的密度可以进一步的增加以形成实际的半稠密世界观,是一条非常棒的路径。但是这条路径问题也非常多,最核心的一点是三相性中的开销度,其次是视觉世界观相当于雷达的深度信息仍有一些明显的缺陷,再次是和IMU等运动类传感器紧耦合难以实施,后续进行详述。
02
相关工作与评估 (不懂可跳):
(1) 三相性VIO系统研究与试验发展:
2021年至2022年中, 紫川组主要针对(1)完成了三相性相关工作,实现了viobot完整的软硬件闭环,实现了独立编解码与OSD叠点,开发了独立的UI与三维空间规划底,通过CPU+GPU+DSP完成了整个系统前端/后端与回环的并行化(其实回环并没有真正并行化只是做了SIMD),完成了完整SDK,并针对在各种真实环境中的极端情况设计了对应的ZUPT策略,输出了VIO/VINS工程问题定位的思路与流程。以上各项工作在前文中都已经详述。最近一些收尾工作是双目初始化的升级和环点SDK。2022年中至2023年6月重点完成VIO系统的世界观,主要难点在数据结构,每天不是整WARP原语就是各种乱七八糟的CELL和树结构。在之前这一系列工作中,首先感谢港科VINS组,尤其是基于四元数的预积分的编写工作,后续大家的一些工作可以用GTSAM,但是用这个去处理预积分其实在工程侧是不友好的,还是重了。
针对(1),目前其实可用性是很高的,这个和大家对于稀疏点云的通常直观理解还是会有一些差异。相关工作先重点描述这个:词袋看起来貌似是一门玄学,其实它存储了优化之后在空间中的相机位置与姿态,以及它在当时所对应的点的x,y坐标与深度信息(但是数量很少很稀疏比如200个,多了算不过来)。最终你存的那张图其实是没啥用的,形成的数据结构是一整个用二进制表述的关键字和描述符,同时词袋字典是用很基本的k-d树形式训练与存储,所以它其实一点都不玄学,而是一门真正的显学。在机器语言中系统是很容易完成这个工作流的,同时对准确率及召回率来说,所有的VSLAM系统和VIO系统在商用时一定要有更高的准确率!这块照做即可。

首先你把这玩意当成三维空间,红色代表地面真实GT(也不要纠结哪来的,你当我外感信标或者RTK大概标的),蓝色的各种不确定小椭球你就可以当成词袋回环每一次定位的范围了。绿色的线代表重复作业轨迹,在这个二次和多次机器人作业的过程中,所复用的位置姿态,即蓝色不确定椭球给予的引导。同时这是一个标准3D-2D的PNP过程,进入回算之后给出的位姿也是相对世界坐标系原点的位姿。
缺点是虽然词袋重定位及回环是一门显学,但是毕竟它是一个二进制的综合描述,也来源于二维图像中的特征点与描述子(如ORB),它给人整体的感觉肯定是远远不如三维点云的,而且对作业重定位观测方向也会有要求。也不像真正的二维重定位如Catagrapher这类系统中开发的二维边界矢量重定位清晰。但是实际它是好用的,即使环境中出现了一些小的移动目标物,也不会对整个词袋的特性造成太大的破坏,仍然可以友好的重定位与回环。但当然当所取用的环点中如果有30-40%以上都改变了,肯定也是难以回环的(这种难以回环和重定位反而是正确的结果)
回到摘要中的基础逻辑4,任何SLAM的优化,势必产生误差,VIO只是提供了更好的鲁棒性也是目前世界上性价比最好的传感器组合(前提是解决三相性,否则算力平台成本惊人),而这种误差,必须通过重定位手段解决,才能更新更准确的位姿和世界观(建图)
实现的效果就是类似TANGO的这个简单清晰的小视频了【Visual-inertial teach and repeat powered by Google Tango】
https://www.bilibili.com/video/BV1tP4y1d7AX/share_source=copy_web&vd_source=3cba44a8cb771560d536cc3085033dfe,但是要注意,无论如何,(1)这种系统的世界观都是相当糟糕的!

TANGO完成位姿计算并记录工作点(重定位环点)

稀疏的MAPPING

UAV完成作业及重定位拍摄。
其实(1)还有一个很大的问题,虽然它是一套很好的导航与重定位系统,但是它仍然难以用来实现SLAM基础逻辑3中的具体操作行为,比如抓取一个水杯,打开一扇门等,因为首先它的世界观是稀疏的。当然到这里有同学会问了,那我再加上一个面阵i-tof相机呢?其实我想说这个也是难以实现的,因为目前最好用的VIO(如我们组的系统,哈哈)其实误差大约也是在0.5-0.8%,而很多具体操作要求的精度是cm级别的。实现这种耦合的最好设计是:先使用VIO导航定位到附近,如数十cm内,再启动另外一套工作逻辑(如AI的类识别结合i-TOF相机)结合机械臂完成接下来的工作。目前导航+操作类的大量行为还是更多的依赖外感信标。
(2) 激光雷达SLAM系统简述:
激光雷达最大的优点就是有完全可控的深度,用非常弱智的方式算回来,线束越多,建图越清晰。
真的是简述,几个问题,首先雷达太贵了。
其次雷达在非常近距离的具体操作实施上一样是有问题的,误差并不小,特别近和特别远都有问题。
最后一个问题是先算位姿再进行ICP等暴力匹配的方式太浪费开销,无论怎么优化数据结构,八叉树/K-D/BBST,结果都类似,除非降帧降频或者大量降低最后模型的精度(比如八叉树最后搞成一坨坨的),那这不就走回头路了吗。。。当然现在也有很多更好的方式提高雷达的工作效率和开销比,但是很多都需要基于GPU和NPU等矩阵乘法器,极大的提升了门槛,几乎完全就是给车载平台弄的,仍然不利于行业的进步和业务的普及!
(3) 紧耦合连贯优化的直接法/ DSO-直接稀疏里程计
这个部分后续我准备专门针对性的写个纯技术的课题,春节后应该还要发布DM-VIO的全解和pipeline。因此这篇文章还是写粗一些。但是要注意,这个部分即使写粗,对于一些基础稍微弱一些的朋友,还是非常吃力的。
其实首先我一直对Daniel老师这个命名感觉到奇怪。。。为啥叫这个,其实明明挺稠密的或者说可以做到很稠密,嘿嘿。
TUM的这套方法和路径是目前能实现视觉世界观的主流方法,但是有一系列非常麻烦的先决条件,首先就是对光度标定的要求非常高,另外对卷帘快门非常不友好(虽然已经提供了优化方法),另外也没有过多考虑自动增益等现代相机带来的影响,但是瑕不掩瑜,这套方法在我的心目中,还是非常重要的,虽然它真的非常地难。。。
DSO的灵魂是:光度不变假设
他的学生Jacob Engel在2016-2017年就整个完成了DSO这套系统并开源,写得。。。怎么说呢,一言难尽,其实就是写得非常好,但是对普通工程师过于不友好,导致了后续这个方向一直没有得到太多的发展,但是本身也是因为它的这一整套理论实施落地的难度。。。
DSO详解高翔博士在知乎做过,另外东北大学的高手龚亦群同学做了整个代码的详解,我们在他这个海量工作的基础上重新梳理了一下因子图。所以我在这里就不多贴式子了,讲核心重点!
DSO是基于优化的,H矩阵形态很好理解,每个位姿8维,在6个自由度上增加了2个关键的光度参数a,b。最核心的3个残差同时包含了:几何/光度与图像梯度,对应3个Jacobian。
这3个残差的优化就是绝大部分同学难以上手的核心原因,另一个核心原因是其极其麻烦的初始化。整个DSO绝对不是大家简单认为的顺序操作:比如先前端提取,然后跟踪,然后匹配,然后RANSAC,然后BA或者卡尔曼优化这类,而是整个工作流都在不断地重复交叉优化这3种残差同时不断地更新整个Hession矩阵的过程。
FRAME/POINT与Residual与对应的能量EF全部互持指针,整个工作流耦合度极高,但注意因果关系!正是这种非常精美的模型,才能实现最终DSO所实现的真正相对稠密的视觉世界观。
DSO系统解耦的难度极大,最好的方法就是重写,另外后续地平线的工作组和涂大神也手写了2个双目的立体S-DSO, 问题仍然有不少但是已经收敛了很多。后人也在不断地推进相关工作。
DSO系最大的问题就是如果要建立更好的视觉世界观,其开销会几何级数增长,同时因为运算涉及到太多的交叉优化与迭代(矩阵的处理和常规差不多),很难ASIC化。同时因为耦合度很高,运动传感器也很难并入,如VI-DSO和DM-VIO并入了IMU,代码也是很难的。同时DM-VIO虽然运行效果很好,但是开销更高了(直接2个BA+延迟边缘化在跑,视觉紧耦,运动传感器接近松耦,虽然也不是很松)。
视觉世界观如果真正建立,我们的重定位便不再依赖词袋这类东西,同时回环也会变得没那么重点,我们将有更多方法匹配惯性系与世界系,因为我们得到的参照数据将变得更加直观。
但是事情也不要太理想化,视觉世界观毕竟还是来自于双眼,和雷达世界观比仍然有不少的缺陷:如大树在阳光下的影子,一面墙它只是个矩形但到底是否可以通过呢?这一系列的问题。
审核编辑 :李倩
-
SLAM
+关注
关注
23文章
428浏览量
31995 -
VIO
+关注
关注
0文章
11浏览量
10222 -
VSLAM
+关注
关注
0文章
24浏览量
4367
原文标题:深度解读!VSLAM与VIO的3D建图,重定位与世界观综述
文章出处:【微信号:vision263com,微信公众号:新机器视觉】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
解读3D打印 打造科技生活新世界
肇观电子发布世界领先AI视觉处理芯片N171
3D TOF深度剖析
全球3D芯片及模组引领者,强势登陆中国市场
MASTERIMAGE 3D公司向世界展示强大的3D立体技术
3D电视显示技术综述
微软眼中的AI世界观 AI指引未来世界将走向何方
旷视科技联合业内企业共研3D视觉 探索世界的深度
NVIDIATITANXPascal评测 重新刷新我们对TITANX的世界观
关于3D视觉定位技术详细解析
深度剖析3D视觉定位技术
一种降低VIO/VSLAM系统漂移的新方法
3D深度感测的原理和使用二极管激光来实现深度感测的优势





 工商网监
工商网监
评论