 何利用PMC来发现JVM原生代码的瓶颈?
何利用PMC来发现JVM原生代码的瓶颈?
本文通过对CPU层面的代码挖掘,发现JVM存在的问题,并通过对JVM打补丁的方式解决了大实例下性能不足的问题。
在前面的文章中,我们概述了可观测性的三大领域:整体范围,微服务和实例。我们描述了洞察每个领域所使用的工具和技术。然而,还有一类问题需要深入到CPU微体系架构中。本文我们将描述一个此类问题,并使用工具来解决该问题。
问题概述
问题起始于一个常规迁移。在Netflix,我们会定期对负载进行重新评估来优化可用容量的利用率。我们计划将一个Java微服务(暂且称之为GS2)迁移到一个更大的AWS实例上,规格从m5.4xl(16 vCPU)变为m5.12xl(48 vCPU)。GS2是计算密集型的,因此CPU就成为了受限资源。虽然我们知道,随着vCPU数量的增长,吞吐量几乎不可能实现线性增长,但可以近线性增长。
在大型实例上进行整合可以分摊后台任务产生的开销,为请求留出更多的资源,并可以抵消亚线性缩放。由于12xl实例的vCPU数是4xl实例的3倍,因此我们预期每个实例的吞吐量能够提升3倍。在快速进行了一次金丝雀测试后发现没有发现错误,并展示了更低的延迟,该结果符合预期,在我们的标准金丝雀配置中,会将流量平均路由到运行在4xl上的基准以及运行在12xl上的金丝雀上。
由于GS2依赖 AWS EC2 Auto Scaling来达到目标CPU利用率,一开始我们认为只要将服务重新部署到大型实例上,然后等待 ASG (Auto Scaling Group)达到目标CPU即可,但不幸的是,一开始的结果与我们的预期相差甚远:
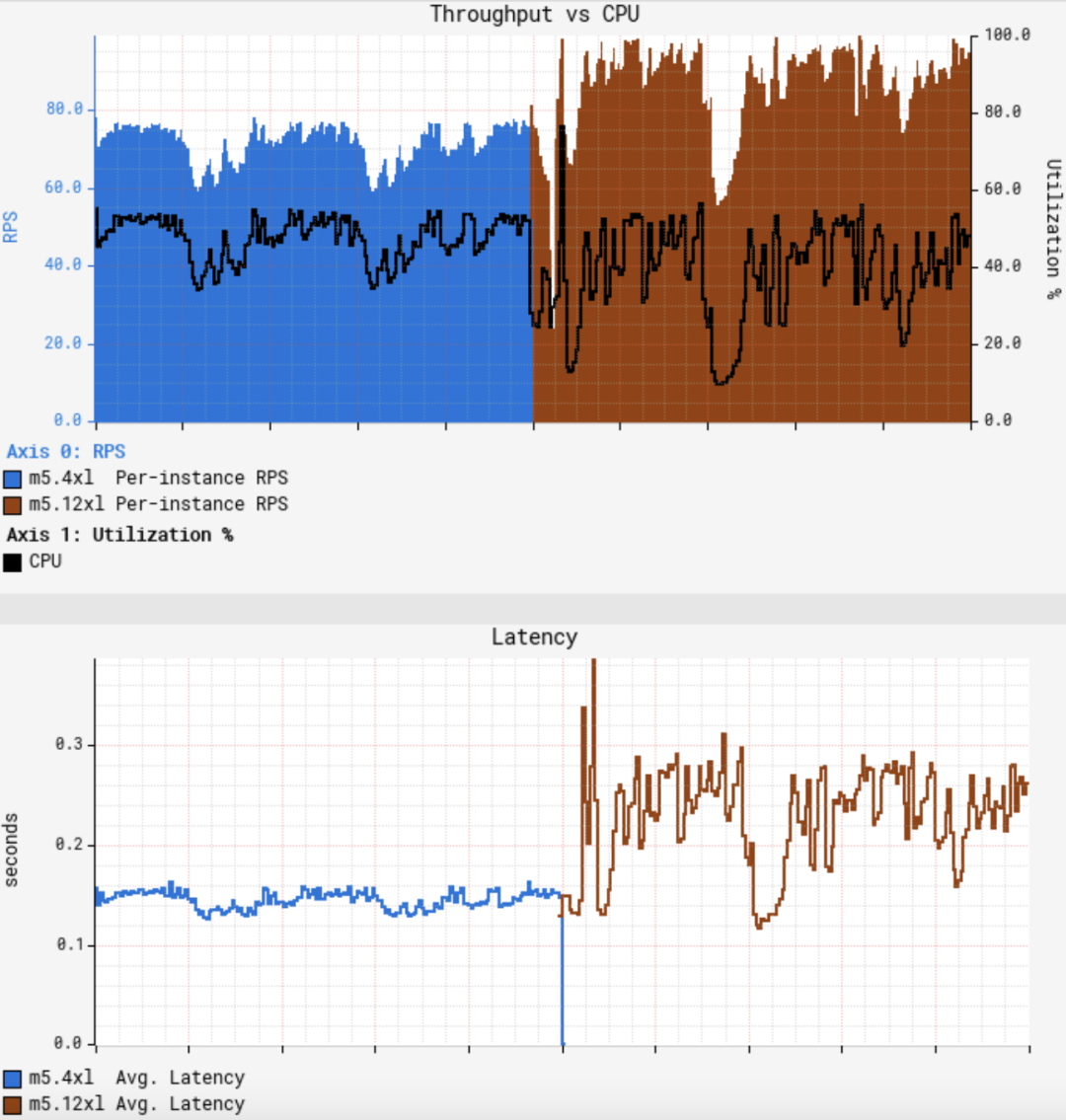
第一张图展示了单节点吞吐量和CPU利用率之间的关系,第二张图展示了平均请求延迟。可以看到当CPU大致达到50%时,平均吞吐量仅仅增加了约25%,大大低于预期。更糟糕的是,平均延迟则增加了50%,CPU和延迟的波动也更大。GS2是一个无状态服务,它使用轮询方式的负载均衡器来接收流量,因此所有节点应该接收到几乎等量的流量。RPS(Requests Per Second)也显示了,不同节点的吞吐量变化很少:
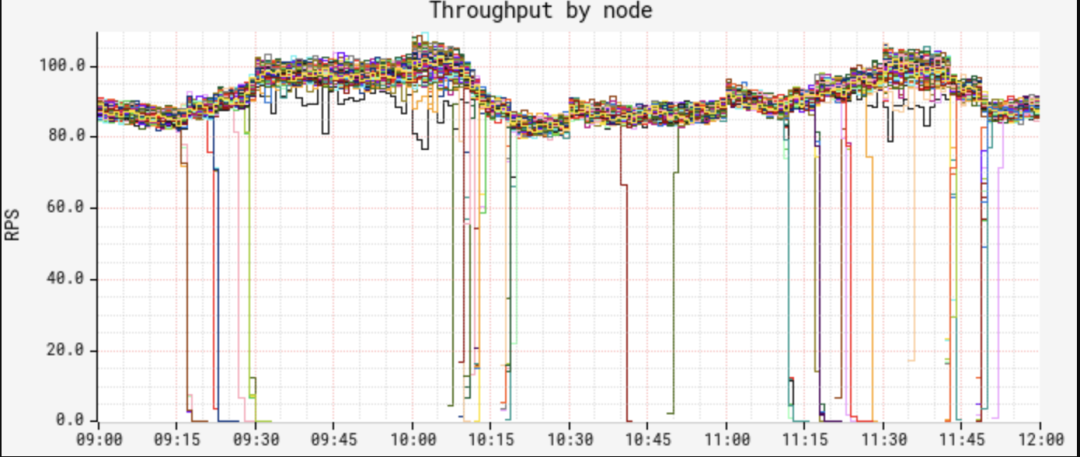
但当我们查看节点的CPU和延迟时,发现了一个奇怪的模式:
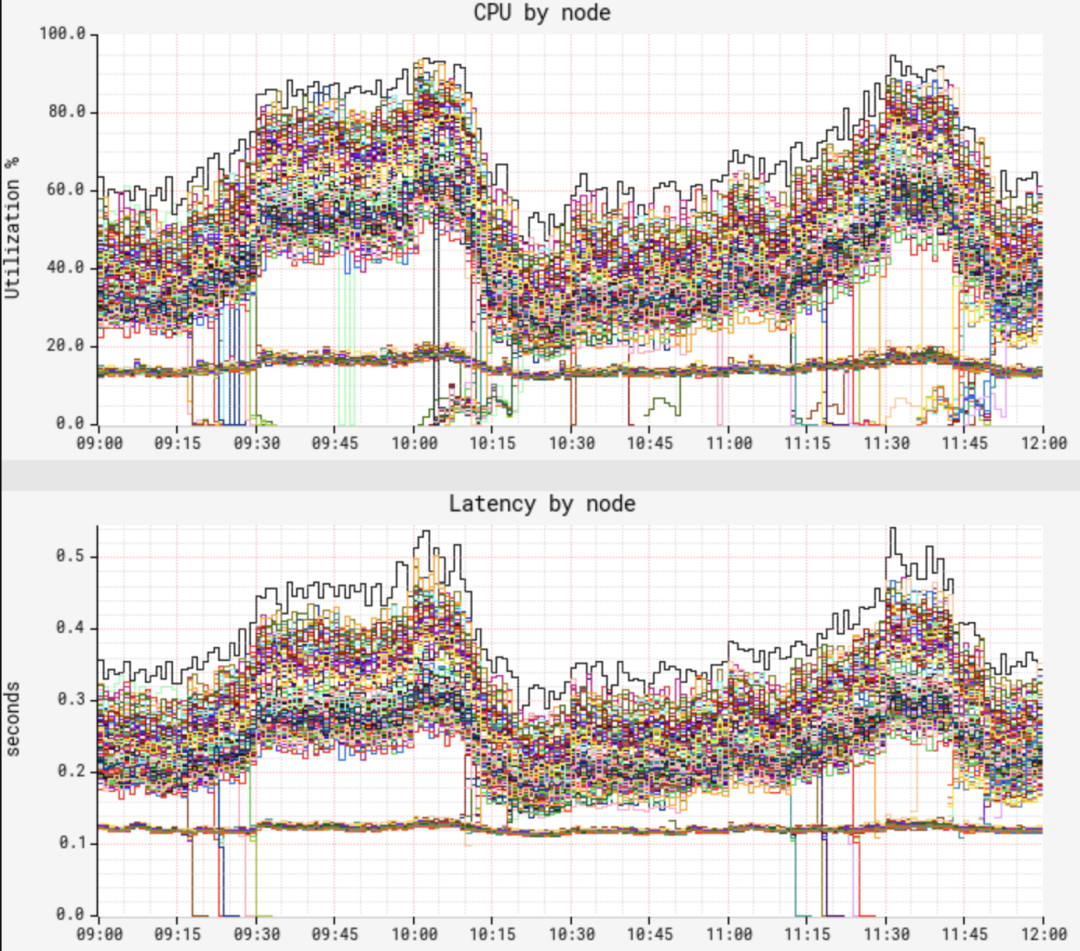
尽管我们确认了节点之间的流量分布相当,但CPU和延迟度量却展示了一种非常不同的双峰分布模式。"低波段"的节点展示了很低的CPU和延迟,且几乎没有波动,而"高波段"的节点则具有相当高的CPU和延迟,以及更大的波动。我们发现大约12%的节点处于低波段中,随着时间的推移,这一图形让人产生怀疑。两种波段中,在(节点上的)JVM的整个运行时间内,其性能特点保持一致,即节点不会跳出其所在的波段。我们就此开始进行问题定位。
首次尝试解决
一开始我们尝试对比快慢两种节点的火焰图。虽然火焰图清晰地给出了采样到的CPU利用率之间的差异,但堆栈之间的分布保持不变,因此并没有获得有价值的结论。我们转而使用JVM专用的性能采样,从基本的hotspot 统计到更详细的 JFR (Java Flight Recorder)来比较事件分布,然而还是一无所获,快慢两种节点的事件数量和分布都没有出现值得关注的差异。我们仍然怀疑JIT行为可能有问题,通过对perf-map-agent 采集的符号映射进行了一些基本统计,结果发现了另一个死角。
False Sharing
在确定没有在app-,OS-和JVM层面有所遗漏之后,我们感觉答案可能隐藏在更低的层次。幸运的是,m5.12xl实例类型暴露了一组PMCs (Performance Monitoring Counters, 即PMU 计数器),因此我们可以使用PerfSpect采集一组基线计数器数据:
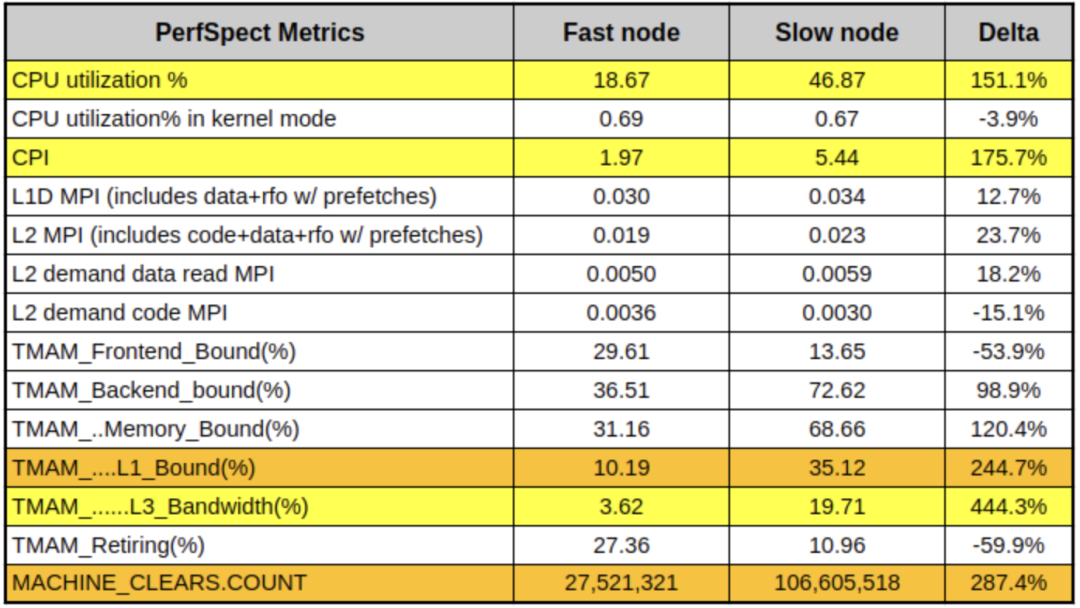
在上表中,低CPU/延迟的节点代表"快节点",而高CPU/延迟的节点代表"慢节点"。除了CPU上的明显差异外,还看到慢节点的CPI几乎是快节点的3倍。此外,我们还看到了更高的L1缓存活动以及4倍的MACHINE_CLEARS计数。一种常见的导致这种现象的原因称为false sharing,即当2个core读/写恰好共享同一L1 cache line的不相关的变量的模式。Cache line是一个类似内存页的概念,数据块(x86系统通常为64字节)会进出该缓存,过程如下:
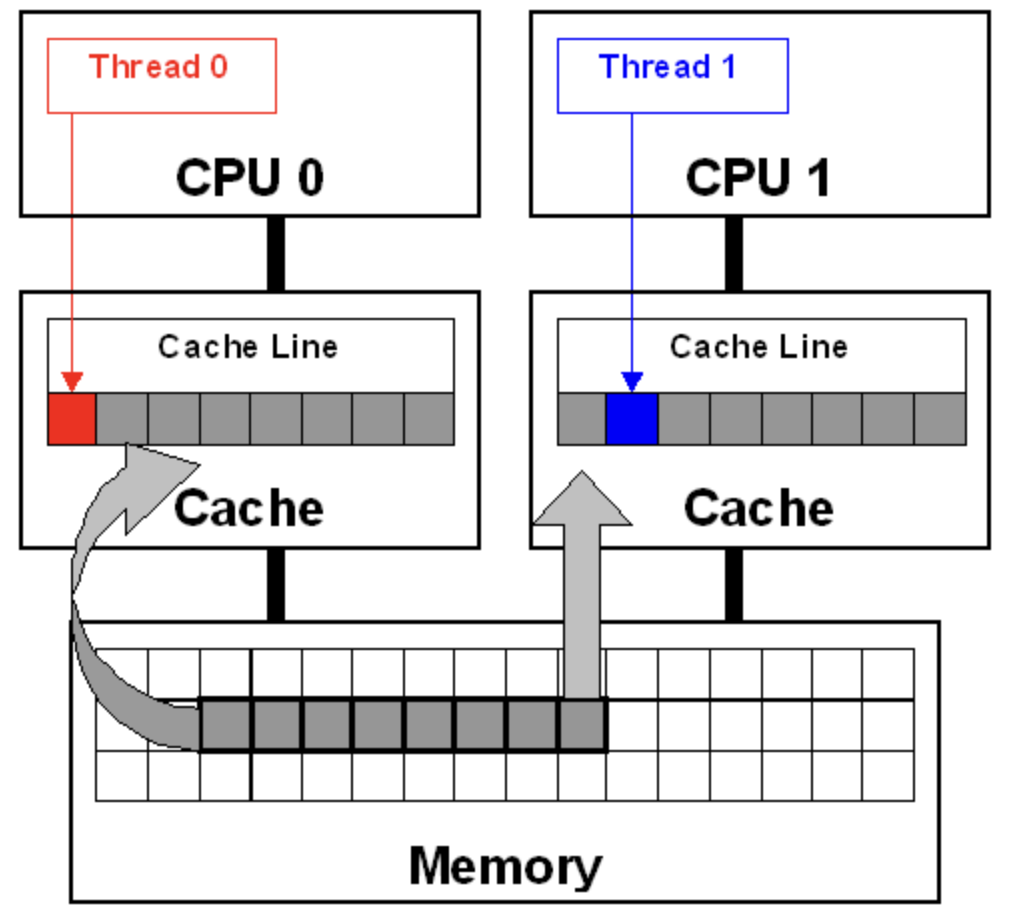
图中的每个core都有自己的私有缓存,由于两个cores会访问相同的内存空间,因此必须保证缓存一致。这种一致性称为缓存一致协议。Thread 0会写入红色变量,一致性协议会将Thread 0中的整个cache line标记为"已修改",并将Thread 1的缓存标记为"无效"。
而后,当Thread 1读取蓝色变量时,即使蓝色变量不是"已修改"的,一致性协议也会强制从缓存中重载上次修改的内容(本例中为Thread 0的缓存)到cache line中。解决私有缓存之间的一致性需要花费一定时间并导致CPU暂停。此外,还需要通过最后一级共享缓存的控制器来监控来回的一致性流量,进而导致更多的暂停。我们认为CPU缓存一致性是理所当然的,但这种false sharing模式表明,如果只读取与无关数据相邻的变量时,就会造成巨大的性能损耗。
根据已掌握的知识,我们使用 Intel vTune 来进行微体系架构的性能采样。通过研究热点方法以及汇编代码,我们找出了超过100CPI的指令(执行非常慢的指标),如下:
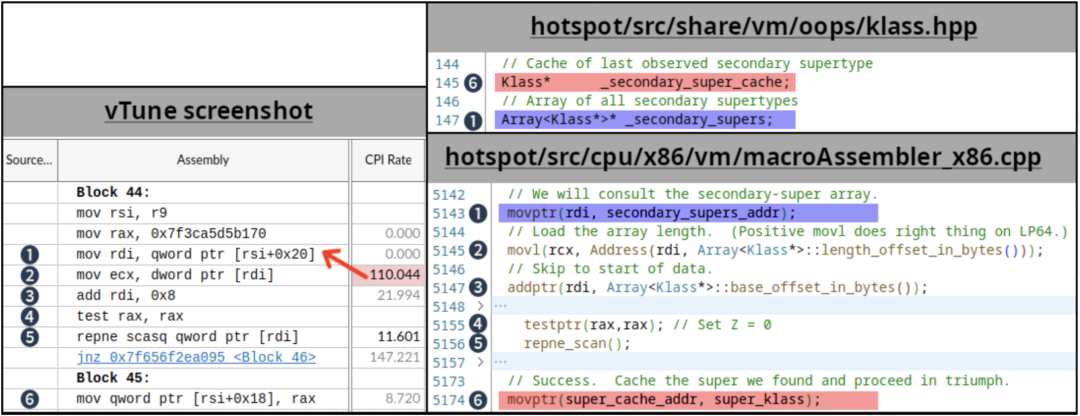
1到6的编号表示源代码和vTune汇编视图中对应的相同代码/变量。红色箭头表示的CPI值可能属于上一条指令,这是由于在没有PEBS(基于处理器事件的采样)的情况下进行了性能采样,并且通常是被单条指令关闭的。(5)中的repne scan是一个相对少见的定义在JVM代码库中的操作,我们将这个代码片段链接到用于子类检查的例程(在撰写本文时,JDK主线中存在相同的代码)中。关于HotSpot中的子类型检查的细节超出了本文的范畴,有兴趣的可以参见2002年出版的Fast Subtype Checking in the HotSpot JVM。
基于该工作负载中使用的类层次结构的特点,我们不断更新(6)_secondary_super_cache字段的代码路径,它是最后找到的二级父类的单元素缓存,注意该字段与_secondary_supers相邻。_secondary_supers是所有父类的列表,会在扫描开始时读取(1)。多线程会对这些字段进行读写操作,且如果字段(1)和(6)处于相同的cache line,那么就会出现false sharing的情况。在上图中,我们使用红色和蓝色高亮了这些导致false sharing的字段。
由于cache line的长度为64字节,而指针长度为8字节,因此这些字段有1/8的机会让处于不同的cache line中,有7/8的机会共享相同的cache line。1/8的即12.5%,这与前面观测到的快节点的比例相同。
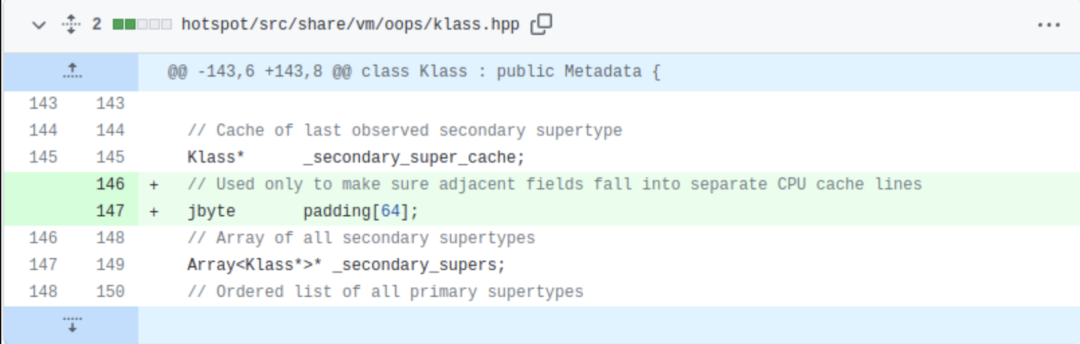
问题的修复需要设涉及对JDK的补丁操作,我们在_secondary_super_cache和_secondary_supers字段中间插入padding来保证它们不会使用相同的cache line。注意我们并没有修改JDK的功能,只是变更了数据布局:
部署补丁之后的效果立竿见影。下图中节点上的CPU出现了断崖式下降。在这里,我们可以看到中午进行了一次红黑部署,而新的ASG和修补后的JDK在12:15时生效:
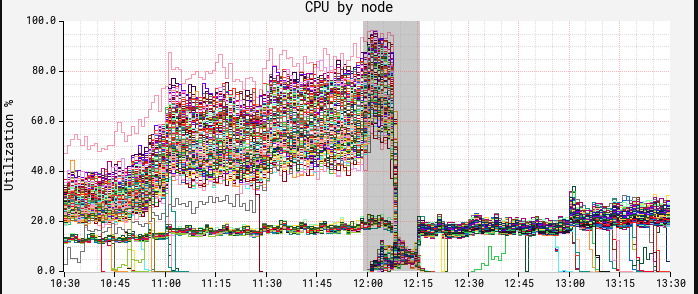
此时CPU和延迟展示了相似的曲线,慢波段节点消失不见。
True Sharing
随着自动扩容达到CPU目标,但我们注意到单个节点仍然无法处理超过150RPS,而我们的目标是250RPS。针对补丁版本的JDK进行的又一轮vTune性能采样,发现围绕二级父类的缓存查找出现了瓶颈。在经过补丁之后又出现了相同的问题,一开始让人感到困惑,但在仔细研究后发现,现在我们使用的是true sharing,与false sharing不同,两个独立的变量共享了一个cache line,true sharing指相同的变量会被多线程/core读写。这种情况下,CPU强制内存排序是导致速度减慢的原因。
我们推断,消除false sharing并提高了总吞吐量会导致增加相同JVM父类缓存代码路径的执行次数。本质上,我们有更高的执行并发性,但由于CPU强制内存排序协议,导致父类缓存压力过大。通常的解决方式是避免一起写入相同的共享变量,这样就可以有效地绕过JVM的辅助父类缓存。由于此变更改变了JDK的行为,因此我们使用了命令行标志,完整的补丁如下:
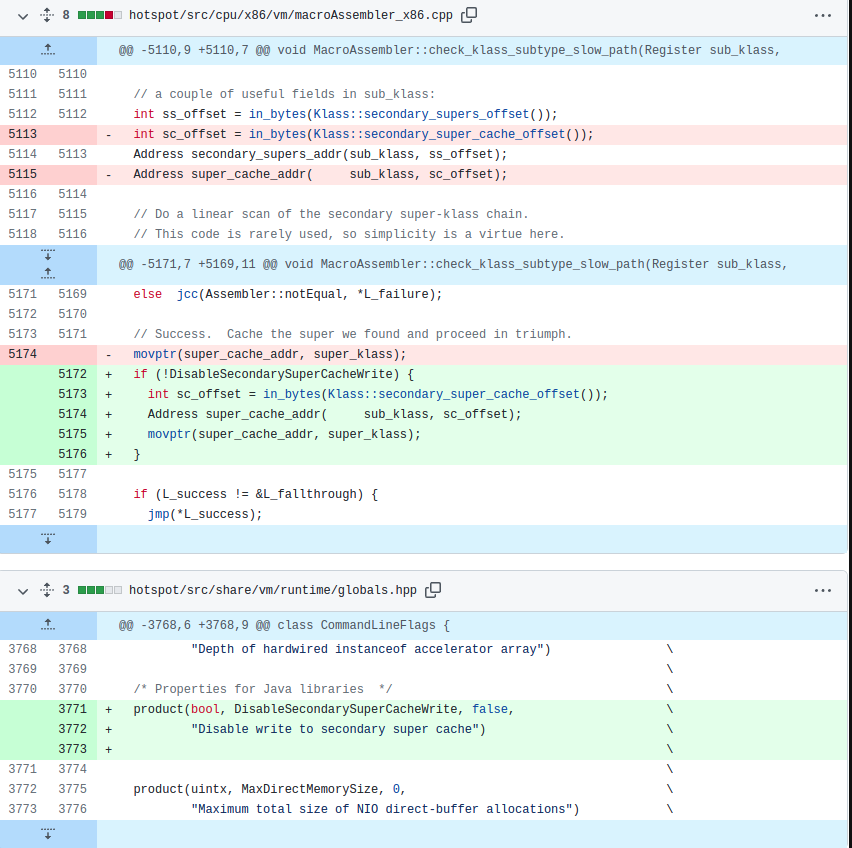
在禁用父类缓存写操作之后的结果如下:
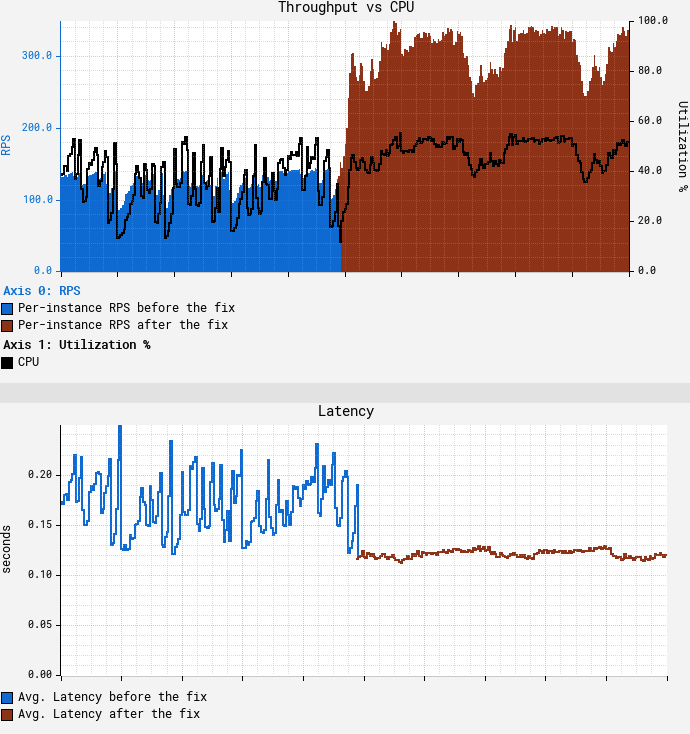
可以看到在CPU达到目标55%的情况下,吞吐量达到了350 RPS,是我们一开始使用m5.12xl的吞吐量的3.5倍,同时降低了平均和尾部延迟。
后续工作
在我们的场景下,禁用写入二级父类缓存工作良好,虽然这并不一定适用于所有场景,但过程中使用到的方法,工具集可能会对遇到类似现象的人有所帮助。在处理该问题时,我们碰到了 JDK-8180450,这是一个5年前的bug,它所描述的问题和我们遇到的一模一样。讽刺的是,在真正找到答案之前,我们并不能确定是这个bug。
总结
我们倾向于认为现在的JVM是一个高度优化的环境,在很多场景中展示出了类似C+++的性能。虽然对于大多数负载来说是正确的,但需要提醒的是,JVM中运行的特定负载可能不仅仅受应用代码的设计和实现的影响,还会受到JVM自身的影响,本文中我们描述了如何利用PMC来发现JVM原生代码的瓶颈,对其打补丁,并且随后使负载的吞吐量提升了3倍以上。当遇到这类性能问题时,唯一的解决方案是在CPU微体系结构层面进行挖掘。intel vTune使用PMC提供了有价值的信息(如通过m5.12xl实例类型暴露出来的信息)。在云环境中跨所有实例类型和大小公开一组更全面的PMC和PEBS可以为更深入的性能分析铺平道路,并可能获得更大的性能收益。
审核编辑:刘清
-
PMC
+关注
关注
0文章
89浏览量
14942 -
JVM
+关注
关注
0文章
158浏览量
12249 -
RPSMA
+关注
关注
0文章
2浏览量
6185 -
AWS
+关注
关注
0文章
432浏览量
24430
原文标题:通过硬件计数器,将性能提升3倍之旅
文章出处:【微信号:LinuxDev,微信公众号:Linux阅码场】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
jvm的类加载器的整体结构及过程解析
进击的 Java ,云原生时代的蜕变
Jvm的整体结构和特点
为什么低代码平台都不采用原生代码的方式
Java:JVM虚拟机的入门知识
如何解决JVM中一个极小概率发生的bug
JVM内存布局的多方面了解
JVM内存布局详解
Spring干掉原生JVM?

详解Java虚拟机的JVM内存布局
jvm的dump太大了怎么分析
jvm内存分析命令和工具
jvm运行时内存区域划分
jvm和jmm的区别
聊聊JVM如何优化





 工商网监
工商网监
评论