 罗列一些在不同操作系统中比较常见的文件系统
罗列一些在不同操作系统中比较常见的文件系统
当提到文件系统时,大部分人都很陌生。但实际上我们几乎每天都会使用它。比如,大家打开 Windows、macOS 或者 Linux,不管是用资源管理器还是 Finder,都是在和文件系统打交道。
如果大家曾经手动安装过操作系统,一定会记得在第一次安装时需要格式化磁盘,格式化时就需要为磁盘选择使用哪个文件系统。
维基百科上的关于文件系统[1]的定义是:
In computing, file system is a method and data structure that the operating system uses to control how data is stored and retrieved.
简而言之,文件系统的任务是管理存储介质(例如磁盘、SSD、CD、磁带等)上的数据。
在文件系统中最基础的概念就是文件和目录,所有的数据都会对应一个文件,通过目录以树形结构来管理和组织这些数据。
基于文件和目录的组织结构,可以进行一些更高级的配置,比如给文件配置权限、统计文件的大小、修改时间、限制文件系统的容量上限等。
以下罗列了一些在不同操作系统中比较常见的文件系统:
• Linux:ext4、XFS、Btrfs
• Windows:NTFS、FAT32
• macOS:APFS、HFS+
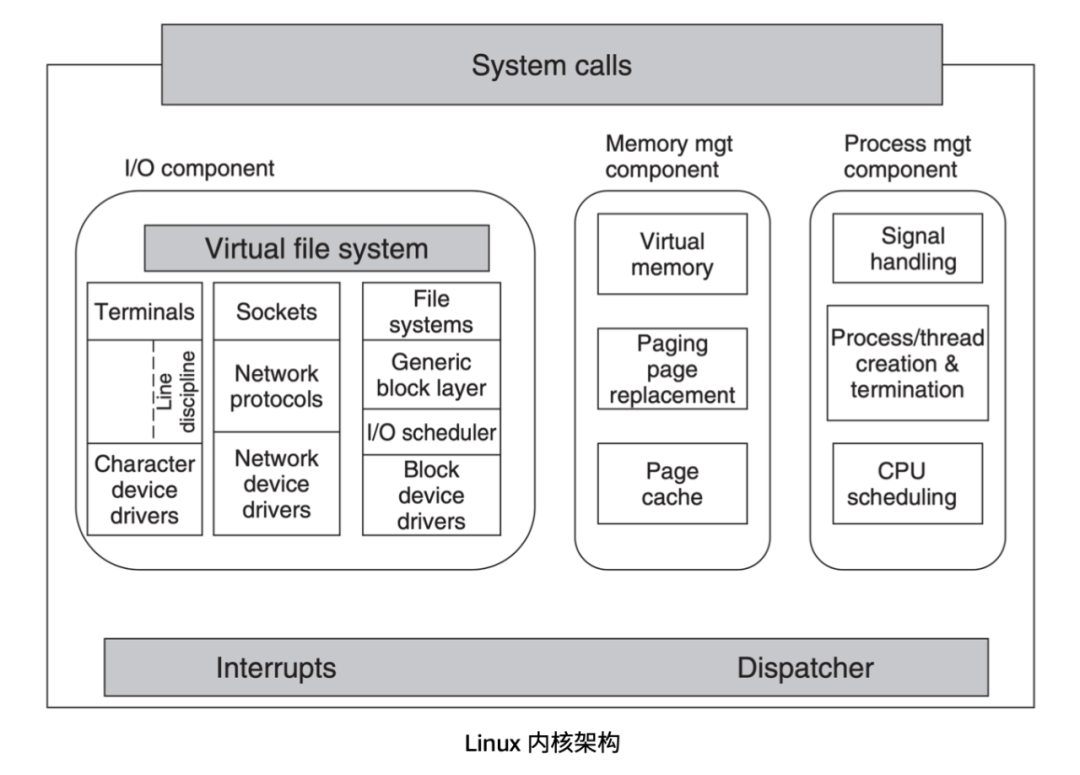
(图片来源:《Modern Operating Systems》10.2.5 小节)
上图是 Linux 内核的架构,左边 Virtual file system 区域,也就是虚拟文件系统简称 VFS。它的作用是为了帮助 Linux 去适配不同的文件系统而设计的,VFS 提供了通用的文件系统接口,不同的文件系统实现需要去适配这些接口。
日常使用 Linux 的时候,所有的系统调用请求都会先到达 VFS,然后才会由 VFS 向下请求实际使用的文件系统。
文件系统的设计者需要遵守 VFS 的接口协议来设计文件系统,接口是共享的,但是文件系统具体实现是不同的,每个文件系统都可以有自己的实现方式。文件系统再往下是存储介质,会根据不同的存储介质再去组织存储的数据形式。
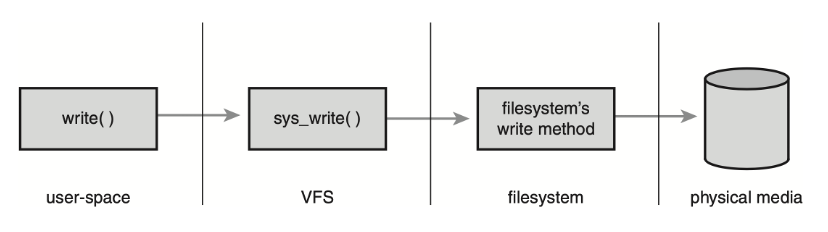
一次写操作的请求流程 (图片来源:《Linux Kernel Development》第 13 章 Filesystem Abstraction Layer)
上图是一次写操作的请求流程,在 Linux 里写文件,其实就是一次write()系统调用。当你调用write()操作请求的时候,它会先到达 VFS,再由 VFS 去调用文件系统,最后再由文件系统去把实际的数据写到本地的存储介质。
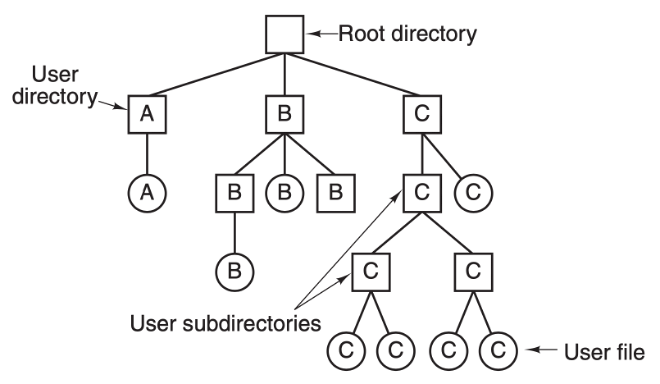
目录树(图片来源:《Modern Operating Systems》4.2.2 小节)
上图是一个目录树的结构,在文件系统里面,所有数据的组织形式都是这样一棵树的结构,从最上面的根节点往下,有不同的目录和不同的文件。
这颗树的深度是不确定的,相当于目录的深度是不确定的,是由每个用户来决定的,树的叶子节点就是每一个文件。
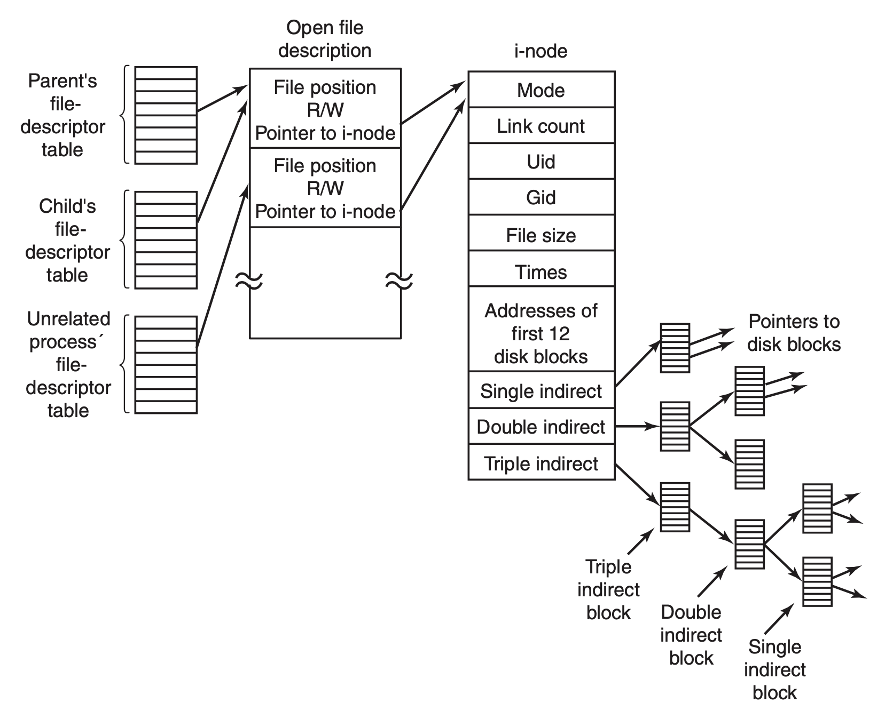
文件描述符与 inode
(图片来源:《Modern Operating Systems》10.6.3 小节)
最右边的 inode 就是每个文件系统内部的数据结构。这个 inode 有可能是一个目录,也有可能是一个普通的文件。Inode 里面会包含关于文件的一些元信息,比如创建时间、创建者、属于哪个组以及权限信息、文件大小等。此外每个 inode 里面还会有一些指针或者索引指向实际物理存储介质上的数据块。
以上就是实际去访问一个单机文件系统时,可能会涉及到的一些数据结构和流程。作为一个引子,让大家对于文件系统有一个比较直观的认识。
分布式文件系统架构设计
单机的文件系统已经能够满足我们大部分使用场景的需求,管理很多日常需要存储的数据。但是随着时代的发展以及数据的爆发增长,对于数据存储的需求也是在不断的增长,分布式文件系统应运而生。
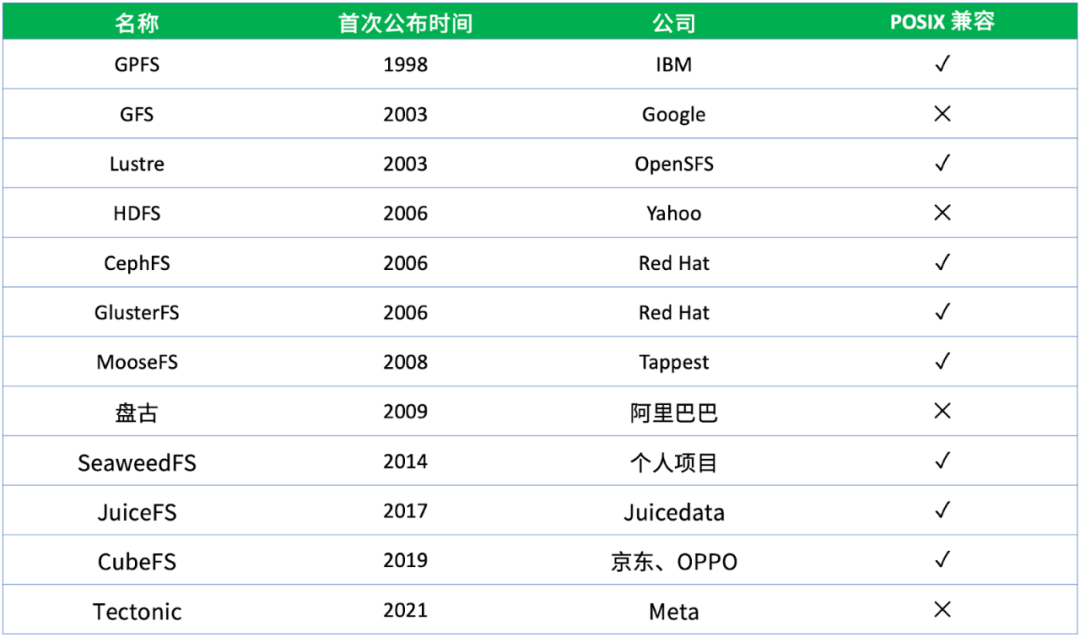
上面列了一些大家相对比较熟悉或者使用比较多的分布式文件系统,这里面有开源的文件系统,也有公司内部使用的闭源产品。从这张图可以看到一个非常集中的时间点,2000 年左右有一大批的分布式系统诞生,这些分布式文件系统至今在我们日常工作中或多或少还是会接触到。在 2000 年之前也有各种各样的共享存储、并行文件系统、分布式文件系统,但基本上都是基于一些专用的且比较昂贵的硬件来构建的。
自 2003 年 Google 的 GFS(Google File System)论文公开发表以来,很大程度上影响了后面一大批分布式系统的设计理念和思想。GFS 证明了我们可以用相对廉价的通用计算机,来组建一个足够强大、可扩展、可靠的分布式存储,完全基于软件来定义一个文件系统,而不需要依赖很多专有或者高昂的硬件资源,才能去搭建一套分布式存储系统。
因此 GFS 很大程度上降低了分布文件系统的使用门槛,所以在后续的各个分布式文件系统上都可以或多或少看到 GFS 的影子。比如雅虎开源的 HDFS 它基本上就是按照 GFS 这篇论文来实现的,HDFS 也是目前大数据领域使用最广泛的存储系统。
上图第四列的「POSIX 兼容」表示这个分布式文件系统对 POSIX 标准的兼容性。POSIX(Portable Operating System Interface)是用于规范操作系统实现的一组标准,其中就包含与文件系统有关的标准。所谓 POSIX 兼容,就是满足这个标准里面定义的一个文件系统应该具备的所有特征,而不是只具备个别,比如 GFS,它虽然是一个开创性的分布式文件系统,但其实它并不是 POSIX 兼容的文件系统。
Google 当时在设计 GFS 时做了很多取舍,它舍弃掉了很多传统单机文件系统的特性,保留了对于当时 Google 搜索引擎场景需要的一些分布式存储的需求。所以严格上来说,GFS 并不是一个 POSIX 兼容的文件系统,但是它给了大家一个启发,还可以这样设计分布式文件系统。
接下来我会着重以几个相对有代表性的分布式文件系统架构为例,给大家介绍一下,如果要设计一个分布式文件系统,大概会需要哪些组件以及可能会遇到的一些问题。
GFS
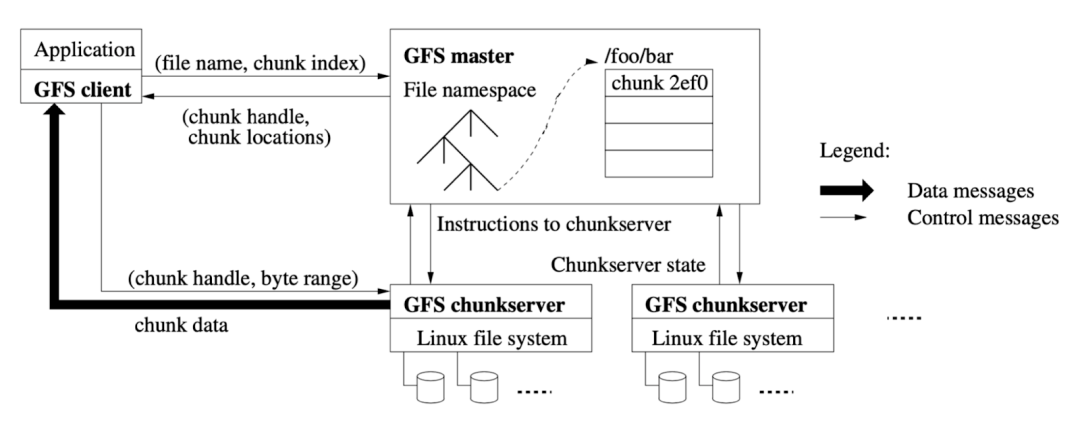
(图片来源:The Google File System 论文)
首先还是以提到最多的 GFS 为例,虽然它在 2003 年就公布了,但它的设计我认为至今也是不过时的,有很多值得借鉴的地方。GFS 的主要组件可以分为三块,最左边的 GFS client 也就是它的客户端,然后就是中间的 GFS master 也就是它的元数据节点,最下面两块是 GFS chunkserver 就是数据实际存储的节点,master 和 chunkserver 之间是通过网络来通信,所以说它是一个分布式的文件系统。Chunkserver 可以随着数据量的增长不断地横向扩展。
其中 GFS 最核心的两块就是 master 和 chunkserver。我们要实现一个文件系统,不管是单机还是分布式,都需要去维护文件目录、属性、权限、链接等信息,这些信息是一个文件系统的元数据,这些元数据信息需要在中心节点 master 里面去保存。Master 也包含一个树状结构的元数据设计。
当要存储实际的应用数据时,最终会落到每一个 chunkserver 节点上,然后 chunkserver 会依赖本地操作系统的文件系统再去存储这些文件。
Chunkserver 和 master、client 之间互相会有连接,比如说 client 端发起一个请求的时候,需要先从 master 获取到当前文件的元数据信息,再去和 chunkserver 通信,然后再去获取实际的数据。在 GFS 里面所有的文件都是分块(chunk)存储,比如一个 1GB 的大文件,GFS 会按照一个固定的大小(64MB)对这个文件进行分块,分块了之后会分布到不同的 chunkserver 上,所以当你读同一个文件时其实有可能会涉及到和不同的 chunkserver 通信。
同时每个文件的 chunk 会有多个副本来保证数据的可靠性,比如某一个 chunkserver 挂了或者它的磁盘坏了,整个数据的安全性还是有保障的,可以通过副本的机制来帮助你保证数据的可靠性。这是一个很经典的分布式文件系统设计,现在再去看很多开源的分布式系统实现都或多或少有 GFS 的影子。
这里不得不提一下,GFS 的下一代产品: Colossus。由于 GFS 的架构设计存在明显的扩展性问题,所以 Google 内部基于 GFS 继续研发了 Colossus。Colossus 不仅为谷歌内部各种产品提供存储能力,还作为谷歌云服务的存储底座开放给公众使用。Colossus 在设计上增强了存储的可扩展性,提高了可用性,以处理大规模增长的数据需求。下面即将介绍的 Tectonic 也是对标 Colossus 的存储系统。篇幅关系,这篇博客不再展开介绍 Colossus,有兴趣的朋友可以阅读官方博客[2]。
Tectonic
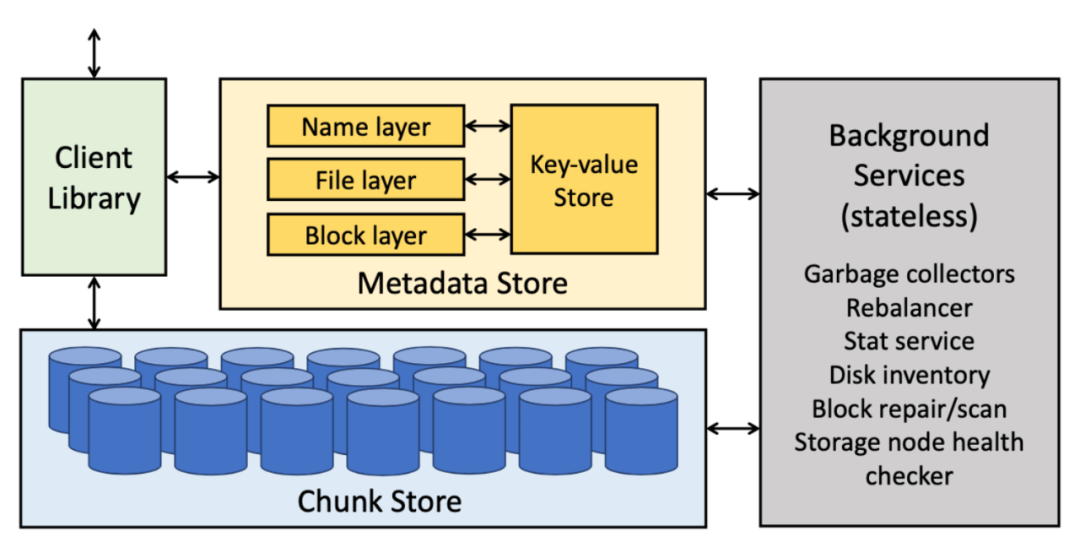
(图片来源:Facebook’s Tectonic Filesystem: Efficiency from Exascale 论文)
Tectonic 是 Meta(Facebook)内部目前最大的一个分布式文件系统。Tectonic 项目大概在 2014 年就开始做了(之前被叫做 Warm Storage),但直到 2021 年才公开发表论文来介绍整个分布式文件系统的架构设计。
在研发 Tectonic 之前,Meta 公司内部主要使用 HDFS、Haystack 和 f4 来存储数据,HDFS 用在数仓场景(受限于单集群的存储容量,部署了数十个集群),Haystack 和 f4 用在非结构化数据存储场景。Tectonic 的定位即是在一个集群里满足这 3 种存储支撑的业务场景需求。和 GFS 一样,Tectonic 也主要由三部分构成,分别是 Client Library、Metadata Store 和 Chunk Store。
Tectonic 比较创新的点在于它在 Metadata 这一层做了分层处理,以及存算分离的架构设计。从架构图可以看到 Metadata 分了三层:Name layer、File layer 和 Block layer。
传统分布式文件系统会把所有的元数据都看作同一类数据,不会把它们显式区分。在 Tectonic 的设计中,Name layer 是与文件的名字或者目录结构有关的元数据,File layer 是跟当前文件本身的一些属性相关的数据,Block layer 是每一个数据块在 Chunk Store 位置的元数据。
Tectonic 之所以要做这样一个分层的设计是因为它是一个非常大规模的分布式文件系统,特别是在 Meta 这样的量级下(EB 级数据)。在这种规模下,对于 Metadata Store 的负载能力以及扩展性有着非常高的要求。
第二点创新在于元数据的存算分离设计,前面提到这三个 layer 其实是无状态的,可以根据业务负载去横向扩展。但是上图中的 Key-value Store 是一个有状态的存储,layer 和 Key-value Store 之间通过网络通信。
Key-value Store 并不完全是 Tectonic 自己研发的,而是用了 Meta 内部一个叫做 ZippyDB 的分布式 KV 存储来支持元数据的存储。ZippyDB 是基于 RocksDB 以及 Paxos 共识算法来实现的一个分布式 KV 存储。Tectonic 依赖 ZippyDB 的 KV 存储以及它提供的事务来保证整个文件系统元信息的一致性和原子性。
这里的事务功能是非常重要的一点,如果要实现一个大规模的分布式文件系统,势必要把 Metadata Store 做横向扩展。横向扩展之后就涉及数据分片,但是在文件系统里面有一个非常重要的语义是强一致性,比如重命名一个目录,目录里面会涉及到很多的子目录,这个时候要怎么去高效地重命名目录以及保证重命名过程中的一致性,是分布式文件系统设计中是一个非常重要的点,也是业界普遍认为的难点。
Tectonic 的实现方案就是依赖底层的 ZippyDB 的事务特性来保证当仅涉及单个分片的元数据时,文件系统操作一定是事务性以及强一致性的。但由于 ZippyDB 不支持跨分片的事务,因此在处理跨目录的元数据请求(比如将文件从一个目录移动到另一个目录)时 Tectonic 无法保证原子性。
在 Chunk Store 层 Tectonic 也有创新,上文提到 GFS 是通过多副本的方式来保证数据的可靠性和安全性。多副本最大的弊端在于它的存储成本,比如说你可能只存了1TB 的数据,但是传统来说会保留三个副本,那么至少需要 3TB 的空间来存储,这样使得存储成本成倍增长。
对于小数量级的文件系统可能还好,但是对于像 Meta 这种 EB 级的文件系统,三副本的设计机制会带来非常高昂的成本,所以他们在 Chunk Store 层使用 EC(Erasure Code)也就是纠删码的方式去实现。通过这种方式可以只用大概 1.2~1.5 倍的冗余空间,就能够保证整个集群数据的可靠性和安全性,相比三副本的冗余机制节省了很大的存储成本。Tectonic 的 EC 设计细到可以针对每一个 chunk 进行配置,是非常灵活的。
同时 Tectonic 也支持多副本的方式,取决于上层业务需要什么样的存储形式。EC 不需要特别大的的空间就可以保证整体数据的可靠性,但是 EC 的缺点在于当数据损坏或丢失时重建数据的成本很高,需要额外消耗更多计算和 IO 资源。
通过论文我们得知目前 Meta 最大的 Tectonic 集群大概有四千台存储节点,总的容量大概有 1590PB,有 100 亿的文件量,这个文件量对于分布式文件系统来说,也是一个比较大的规模。在实践中,百亿级基本上可以满足目前绝大部分的使用场景。
 (图片来源:Facebook’s Tectonic Filesystem: Efficiency from Exascale 论文)
(图片来源:Facebook’s Tectonic Filesystem: Efficiency from Exascale 论文)
再来看一下 Tectonic 中 layer 的设计,Name、File、Block 这三个 layer 实际对应到底层的 KV 存储里的数据结构如上图所示。比如说 Name layer 这一层是以目录 ID 作为 key 进行分片,File layer 是通过文件 ID 进行分片,Block layer 是通过块 ID 进行分片。
Tectonic 把分布式文件系统的元数据抽象成了一个简单的 KV 模型,这样可以非常好的去做横向扩展以及负载均衡,可以有效防止数据访问的热点问题。
JuiceFS
JuiceFS 诞生于 2017 年,比 GFS 和 Tectonic 都要晚,相比前两个系统的诞生年代,外部环境已经发生了翻天覆地的变化。
首先硬件资源已经有了突飞猛进的发展,作为对比,当年 Google 机房的网络带宽只有 100Mbps(数据来源:The Google File System 论文),而现在 AWS 上机器的网络带宽已经能达到 100Gbps,是当年的 1000 倍!
其次云计算已经进入了主流市场,不管是公有云、私有云还是混合云,企业都已经迈入了「云时代」。而云时代为企业的基础设施架构带来了全新挑战,传统基于 IDC 环境设计的基础设施一旦想要上云,可能都会面临种种问题。如何最大程度上发挥云计算的优势是基础设施更好融入云环境的必要条件,固守陈规只会事倍功半。
同时,GFS 和 Tectonic 都是仅服务公司内部业务的系统,虽然规模很大,但需求相对单一。而 JuiceFS 定位于服务广大外部用户、满足多样化场景的需求,因而在架构设计上与这两个文件系统也大有不同。
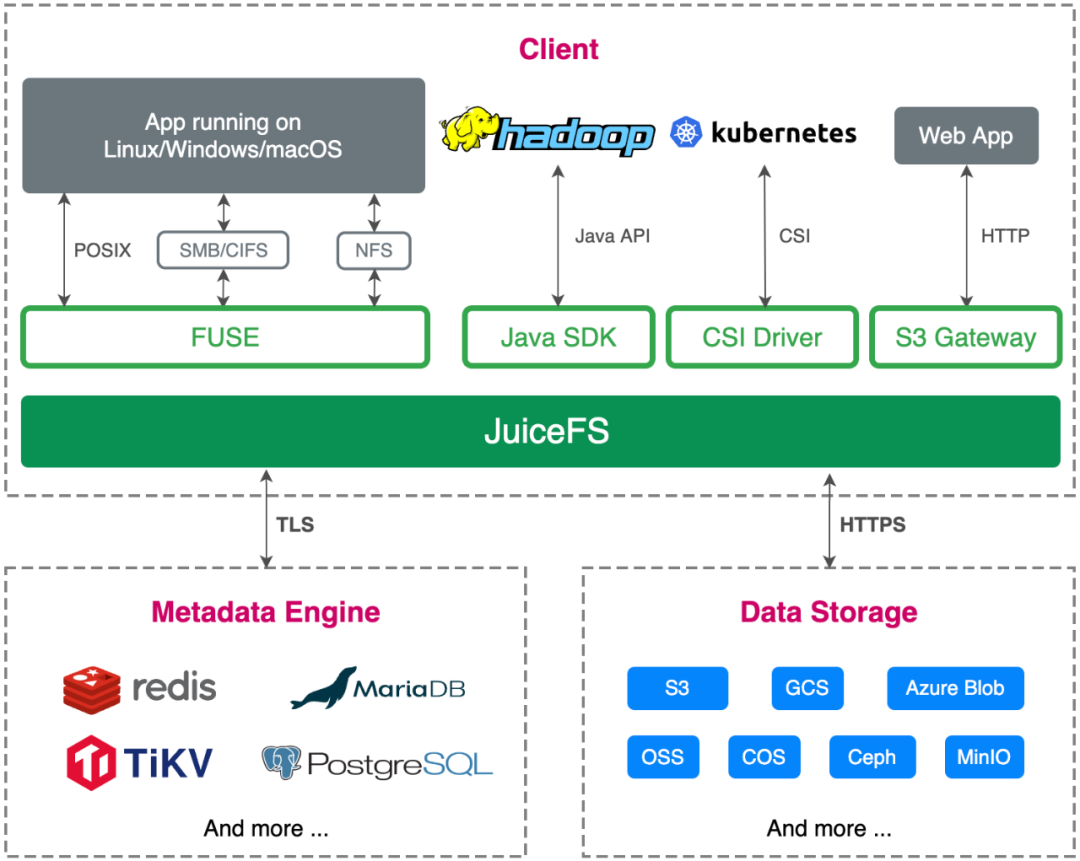
基于这些变化和差异,我们再来看看 JuiceFS 的架构。同样的,JuiceFS 也是由 3 部分组成:元数据引擎、数据存储和客户端。虽然大体框架上类似,但其实每一部分的设计 JuiceFS 都有着一些不太一样的地方。
首先是数据存储这部分,相比 GFS 和 Tectonic 使用自研的数据存储服务,JuiceFS 在架构设计上顺应了云原生时代的特点,直接使用对象存储作为数据存储。前面看到 Tectonic 为了存储 EB 级的数据用了 4000 多台服务器,可想而知,如此大规模存储集群的运维成本也必然不小。对于普通用户来说,对象存储的好处是开箱即用、容量弹性,运维复杂度陡然下降。对象存储也支持 Tectonic 中使用的 EC 特性,因此存储成本相比一些多副本的分布式文件系统也能降低不少。
但是对象存储的缺点也很明显,例如不支持修改对象、元数据性能差、无法保证强一致性、随机读性能差等。这些问题都被 JuiceFS 设计的独立元数据引擎,Chunk、Slice、Block 三层数据架构设计,以及多级缓存解决了。
其次是元数据引擎,JuiceFS 可使用一些开源数据库作为元数据的底层存储。这一点和 Tectonic 很像,但 JuiceFS 更进了一步,不仅支持分布式 KV,还支持 Redis、关系型数据库等存储引擎,让用户可以灵活地根据自己的使用场景选择最适合的方案,这是基于 JuiceFS 定位为一款通用型文件系统所做出的架构设计。使用开源数据库的另一个好处是这些数据库在公有云上通常都有全托管服务,因此对于用户来说运维成本几乎为零。
前面提到 Tectonic 为了保证元数据的强一致性选择了 ZippyDB 这个支持事务的 KV 存储,但 Tectonic 也只能保证单分片元数据操作的事务性,而 JuiceFS 对于事务性有着更严格的要求,需要保证全局强一致性(即要求跨分片的事务性)。因此目前支持的所有数据库都必须具有单机或者分布式事务特性,否则是没有办法作为元数据引擎接入进来的(一个例子就是 Redis Cluster 不支持跨 slot 的事务)。基于可以横向扩展的元数据引擎(比如 TiKV),JuiceFS 目前已经能做到在单个文件系统中存储 200 多亿个文件,满足企业海量数据的存储需求。

上图是使用 KV 存储(比如 TiKV)作为 JuiceFS 元数据引擎时的数据结构设计,如果对比 Tectonic 的设计,既有相似之处也有一些大的差异。比如第一个 key,在 JuiceFS 的设计里没有对文件和目录进行区分,同时文件或目录的属性信息也没有放在 value 里,而是有一个单独的 key 用于存储属性信息(即第三个 key)。
第二个 key 用于存储数据对应的块 ID,由于 JuiceFS 基于对象存储,因此不需要像 Tectonic 那样存储具体的磁盘信息,只需要通过某种方式得到对象的 key 即可。在 JuiceFS 的存储格式[3]中元数据分了 3 层:Chunk、Slice、Block,其中 Chunk 是固定的 64MiB 大小,所以第二个 key 中的chunk_index是可以通过文件大小、offset 以及 64MiB 直接计算得出。通过这个 key 获取到的 value 是一组 Slice 信息,其中包含 Slice 的 ID、长度等,结合这些信息就可以算出对象存储上的 key,最终实现读取或者写入数据。
最后有一点需要特别注意,为了减少执行分布式事务带来的开销,第三个 key 在设计上需要靠近前面两个 key,确保事务尽量在单个元数据引擎节点上完成。不过如果分布式事务无法避免,JuiceFS 底层的元数据引擎也支持(性能略有下降),确保元数据操作的原子性。
最后来看看客户端的设计。JuiceFS 和另外两个系统最大的区别就是这是一个同时支持多种标准访问方式的客户端,包括 POSIX、HDFS、S3、Kubernetes CSI 等。GFS 的客户端基本可以认为是一个非标准协议的客户端,不支持 POSIX 标准,只支持追加写,因此只能用在单一场景。Tectonic 的客户端和 GFS 差不多,也不支持 POSIX 标准,只支持追加写,但 Tectonic 采用了一种富客户端的设计,把很多功能都放在客户端这一边来实现,这样也使得客户端有着最大的灵活性。此外 JuiceFS 的客户端还提供了缓存加速特性,这对于云原生架构下的存储分离场景是非常有价值的。
结语
文件系统诞生于上个世纪 60 年代,随着时代的发展,文件系统也在不断演进。一方面由于互联网的普及,数据规模爆发式增长,文件系统经历了从单机到分布式的架构升级,Google 和 Meta 这样的公司便是其中的引领者。
另一方面,云计算的诞生和流行推动着云上存储的发展,企业用云进行备份和存档已逐渐成为主流,一些在本地机房进行的高性能计算、大数据场景,也已经开始向云端迁移,这些对性能要求更高的场景给文件存储提出了新的挑战。JuiceFS 诞生于这样的时代背景,作为一款基于对象存储的分布式文件系统,JuiceFS 希望能够为更多不同规模的公司和更多样化的场景提供可扩展的文件存储方案。
审核编辑:刘清
-
Linux系统
+关注
关注
4文章
594浏览量
27441 -
SSD
+关注
关注
21文章
2865浏览量
117516 -
fat32文件系统
+关注
关注
0文章
7浏览量
6728 -
APFS
+关注
关注
0文章
2浏览量
11557
原文标题:浅析三款大规模分布式文件系统架构设计
文章出处:【微信号:OSC开源社区,微信公众号:OSC开源社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
华纳云:VFS在提升文件系统性能方面的具体实践
Jtti:Linux中虚拟文件系统和容器化的关系
虚拟化数据恢复—UFS2文件系统数据恢复案例
服务器数据恢复—raid5阵列+reiserfs文件系统数据恢复案例
Linux根文件系统的挂载过程
小型文件系统如何选择?FatFs和LittleFs优缺点比较

服务器数据恢复—xfs文件系统服务器数据恢复案例
如何修改buildroot和debian文件系统
聚徽触控-工业一体机选择什么操作系统好
嵌入式实时操作系统:Intewell操作系统与VxWorks操作系统有啥区别

linux--sysfs文件系统

工业实时操作系统对比:鸿道Intewell跟rt-linux有啥区别






 工商网监
工商网监
评论