 程序从编译到被执行的流程介绍
程序从编译到被执行的流程介绍
当掌握越来越多的基础知识之后,你所看到的代码视角和你之前看代码的视角会发生一个翻天覆地的变化,就像你写代码看到的是一行一行代码的逻辑,而高级程序员看到的是一行一行指令或者你写函数调用是一个正常的函数调用,其他人看到的是调用链背后被调用的情况,所以学东西尽量学习一些基础,这样能够带给我们很不一样的编程体验,也能够让你了解整个程序的本质。当遇到瓶颈之后,更应该多学一些基础知识来丰富自己的眼界。
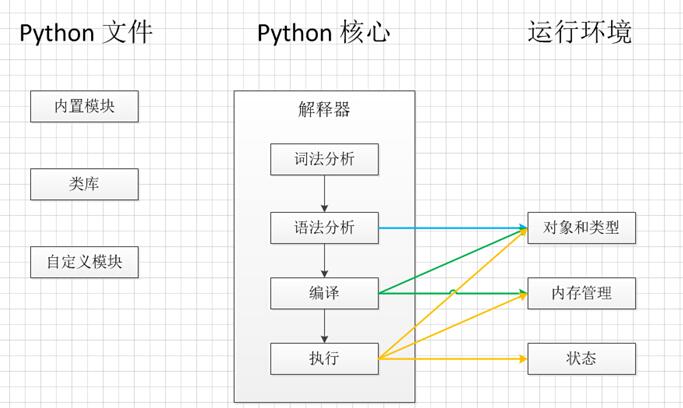
首先看下编译的过程,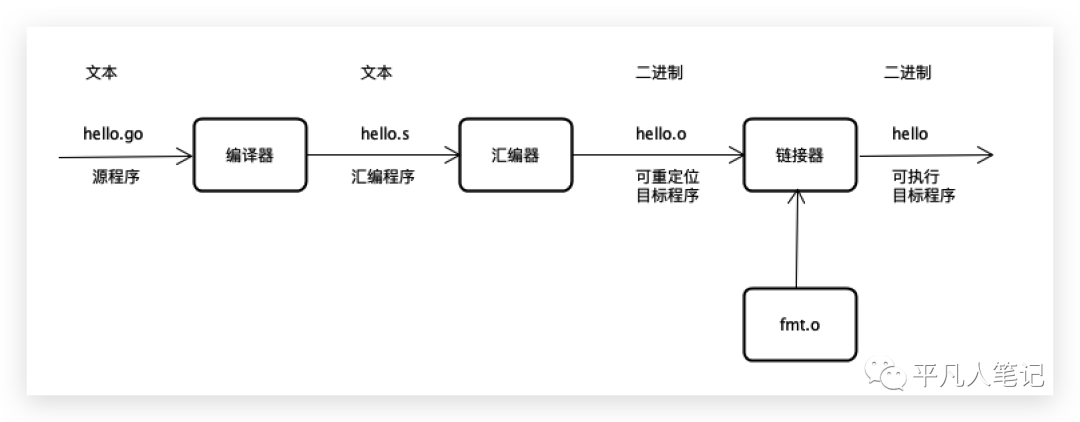
源代码会经过编译器,首先编译成汇编文件,汇编文件经过汇编器变成目标文件。在目标文件当中,函数调用地址是没有被真正的链接起来的,链接的过程是需要经过链接器,把目标文件当中相关的地址信息给链接起来,最后形成可执行的文件。
c编译举例
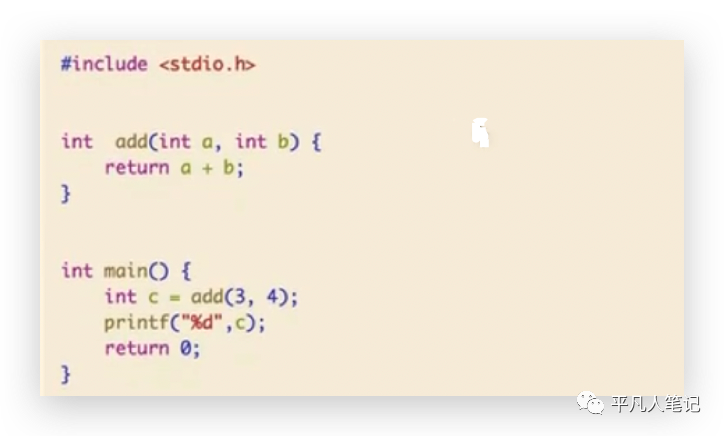
这是一个简单的add函数,在main方法里面调用这个add函数,然后进行打印。
生成目标文件
gcc -c main.c
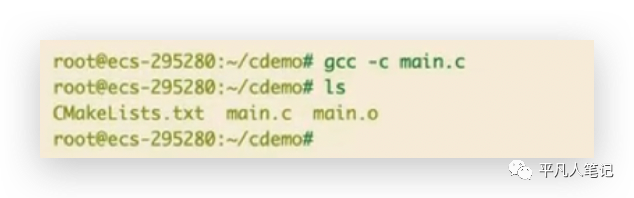
用gcc -c的命令可以生成一个目标文件,
看下生成的目标文件里的地址信息
objdump -d main.o
objdump反编译看下目标文件存了哪些信息,
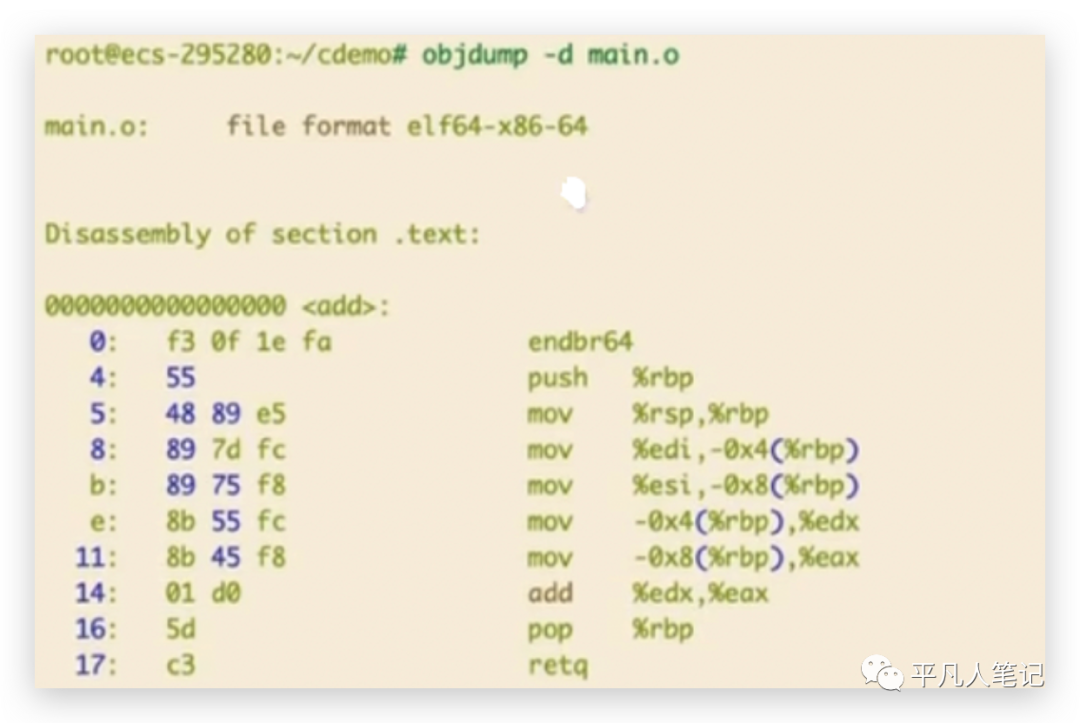
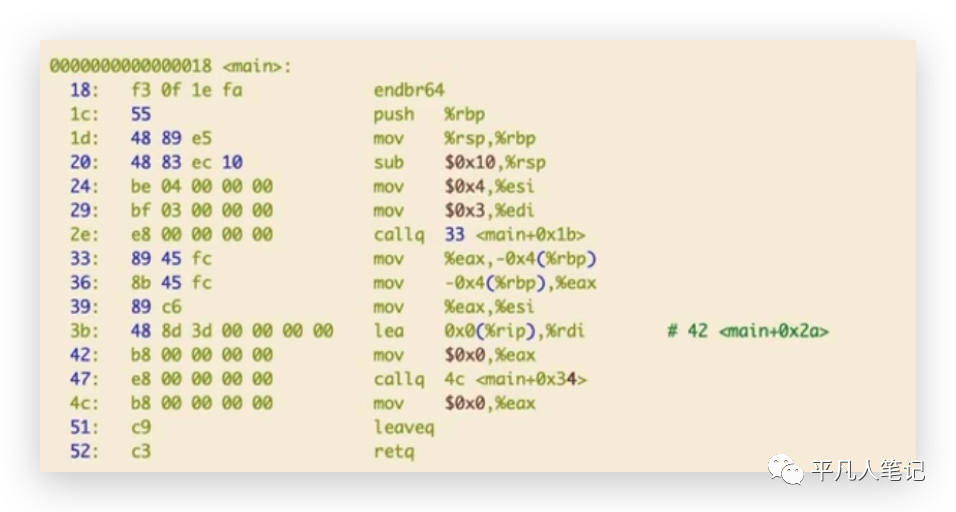
这是一个.test段,程序最终在内存上面或磁盘上面存储的时候,它不是无规律的存储,最后被翻译成机器码之后,也是一段一段存储的,每一段所存的内容是不一样的,像.test段存储的就是正常的代码段也是函数段,而声明的全局变量会存在.data段或.bss段。
这里只需要理解,我们写的代码被翻译成机器码大概的分段逻辑就行了。
左边是这条指令的地址0 4 5 8 .... ,就是我们写的程序加载到内存当中的时候是被加载成一条一条指令,然后每一个指令都会对应一个特定的地址,cpu在取的时候,就会取这个地址上面的信息,就可以知道这条指令地址所对应指令的具体内容。目标文件的这个地址是相对地址,相对于当前段的地址,当前段是.test段,所以是从0开始 按顺序排下来。
callq在汇编里面是调用函数的指令,这里写的是33 ,但其实在真正目标文件被链接成可执行文件之后,33会变成add函数的绝对地址。
被链接成可执行文件之后,看下整个代码地址的变化,用gcc命令编译了一个可执行文件,反汇编看下,将.test段的地址列出来了,它已经不是相对于.test段的相对地址了,而是一个绝对地址。
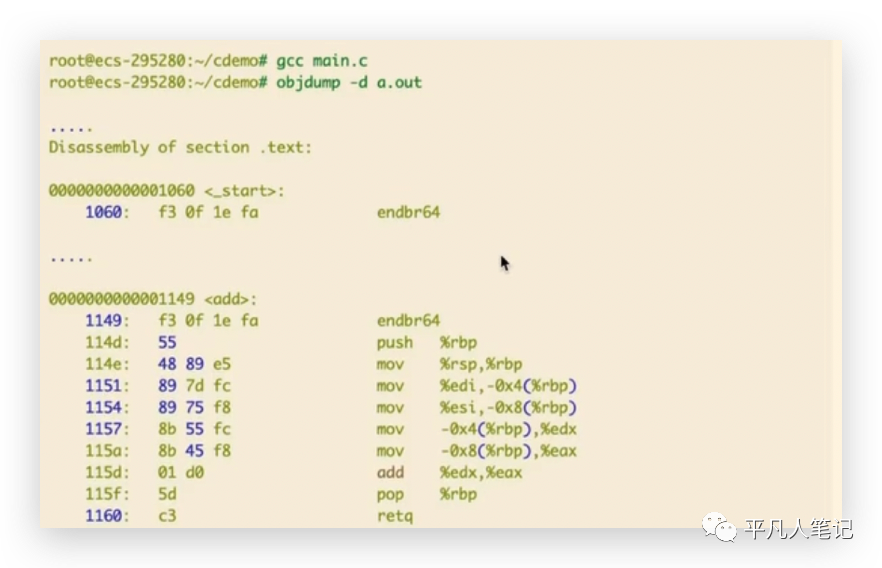
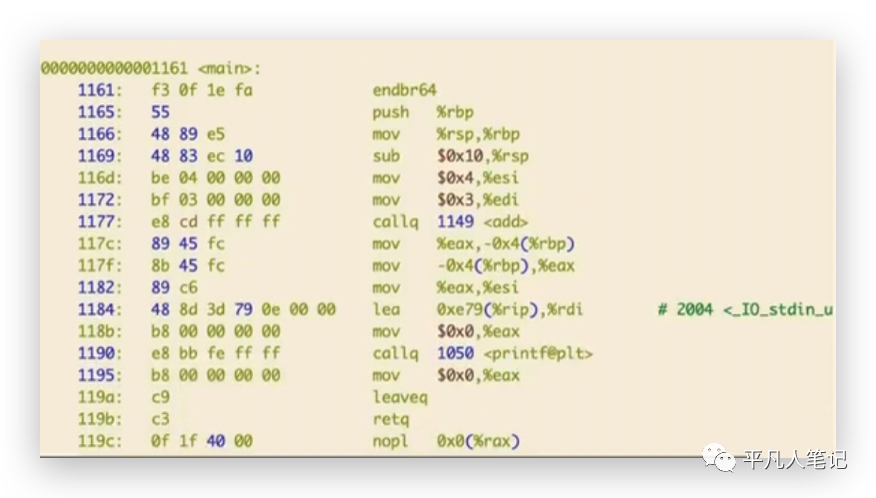
然后看下调用callq add函数的时候 ,1149所对应的首地址是add函数的第一行。<>括号在真正的机器代码中是不存在的,反汇编为了增加可读性才显示的。
在看了程序是怎么被编译成可执行文件之后,我们又知道了可执行文件里面,每一条指令所对应的地址代表什么意思之后,来看下是如何被加载?
这里要明白一点,程序是在内存里面被执行的,被加载到内存之后,cpu才能从内存里面读取并执行,所以有一个从磁盘加载到内存的过程,这个过程由加载器去完成的。
提到内存的话,就要提到cpu的实模式和保护模式。
在很早之前,cpu在实模式时期,我们的程序所使用的地址都是物理地址,就是真正的在内存芯片上所能看到的物理地址,使用物理地址之后,就会导致我们写的程序被编译成可执行文件之后,可执行文件是由链接器编译成链接脚本生成的,然后在链接脚本里面可以指定程序的首地址,如果要指定首地址(有一个默认的首地址),在实模式下,指定了当前编译程序的首地址之后,那它被加载到物理地址之后,这个首地址就只能是真正的被加载到物理地址的那个地方,如果它的首地址比如是0x10,那它被加载到的物理地址的首地址如果不是0x10 就会导致后面那些指令的顺序出现问题,因为指令是顺序排布的,就会导致后面的那些指令地址和可执行文件里面描述的这些指令地址是不吻合的。
这样会导致callq函数会调用到错误的地址,所以在cpu的实模式下,调用程序,程序在执行的时候,它的首地址要固定住,这样就会导致一个问题就是得考虑调得那个地址是不是可用的,调用期间内存是不是可用的,所以会演变成后面的cpu保护模式。
cpu保护模式能够让程序使用的是一个虚拟地址,现在的64位系统都是使用的页式管理,基于这个分析一下。要明白虚拟地址,首先要明白地址空间的概念,地址空间可以理解为进程能用的一个地址范围,比如进程能用的内存是512G,然后由于程序经过编译之后是分段的,就认为这512G里面,0-10G是属于.test段,10-20G是属于.data段,20-200G属于堆空间,其他范围分:栈空间是哪个范围,内核空间又是哪个范围,只是将这段区间划分为了具体的内容所在的这段范围,但是不会实际的在内存上去分配这些内存,只是将范围划分出来,而实际保存的也是这些范围,当需要用到这些范围地址的时候,cpu才会去通过MMU列表里面去寻找这个虚拟地址所对应的物理地址,如果没有这个映射关系,才会去真正的分配物理内存创建映射关系,如果可执行文件一开始没有加载到内存,那么后续地址缺失是如何找到磁盘上面的文件位置的?所以需要看下可执行文件里面到底有哪些信息?
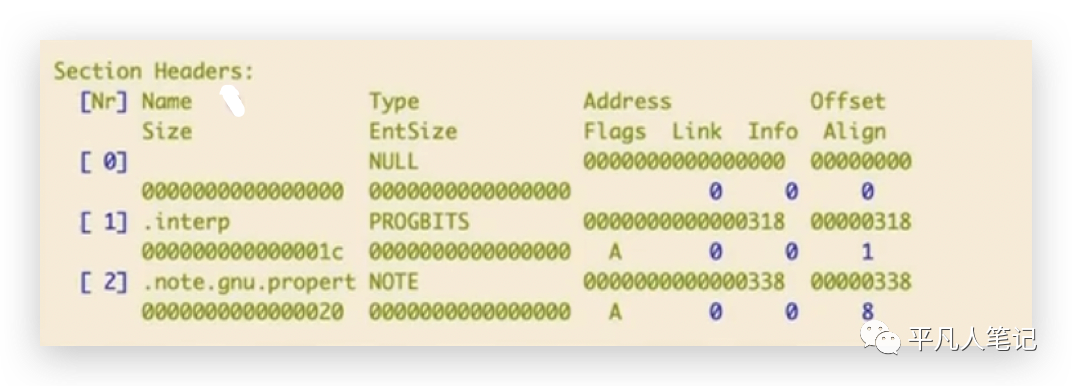
这里列出了可执行文件里面段的头部信息,在段的头部信息里面包含了虚拟地址、文件的偏移量,文件的偏移量可以理解为磁盘信息,可以通过偏移量去定位到在磁盘上的哪个位置,所以操作系统是可以这样做的:在可执行文件里面能够读到段地址还有文件偏移地址,所以在进程被加载执行的时候,刚开始被加载的时候,是可以为这个进程创建页表项,页表项是能够覆盖每个段的地址还有文件偏移的地址,但是这个时候,只是标记这个页表项所映射的这个映射关系,只是标记,并没有真正的分配实际的物理内存,这样等到页缺失的时候 ,够找到这个页表项并并且能够从这个页表项的标记去发现没有分配物理内存,这个时候再从磁盘上去读,再建立映射关系,这样就能够达到在真正使用的时候再去分配物理内存的目的了。
审核编辑:刘清
-
cpu
+关注
关注
68文章
10944浏览量
213823 -
GCC
+关注
关注
0文章
109浏览量
24985 -
编译器
+关注
关注
1文章
1645浏览量
49444 -
汇编器
+关注
关注
0文章
31浏览量
11312
原文标题:程序从编译到被执行的流程
文章出处:【微信号:IC学习,微信公众号:IC学习】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
cc2640 multirole工程代码没有被执行?
C/C++程序编译流程
异常处理程序没有被执行
定时器中断实验里的中断服务是怎么被执行的?

中兴通讯表示与中建五局属于正常商业纠纷并非失信被执行
时代芯存共有5项被执行人信息,总金额已经超过2.45亿元
单片机C程序编译、执行过程资料下载

一条SQL语句是怎么被执行的
罗永浩回应被执行信息清零
中断服务子程序是如何被执行的 ?





 工商网监
工商网监
评论