 NLP数据增强的最新综述
NLP数据增强的最新综述

摘要
作为一种有效的策略,数据增强 (data augmentation, DA) 缓解了深度学习技术可能失败的数据稀缺情况。
它广泛应用于计算机视觉,然后引入自然语言处理,并在许多任务中取得了改进。DA方法的主要重点之一是提高训练数据的多样性,从而帮助模型更好地泛化到看不见的测试数据。
在本次综述中,我们根据增强数据的多样性将 DA 方法分为三类,包括改写(paraphrasing)、噪声(noising)和采样(sampling)。我们的论文着手根据上述类别详细分析 DA 方法。此外,我们还介绍了它们在 NLP 任务中的应用以及面临的挑战。
介绍
数据扩充是指通过添加对现有数据稍作修改的副本或从现有数据中新创建的合成数据来增加数据量的方法。这些方法缓解了深度学习技术可能失败的数据稀缺情况,因此 DA 最近受到了积极的关注和需求。数据增强广泛应用于计算机视觉领域,例如翻转和旋转,然后引入自然语言处理(NLP)。与图像不同,自然语言是离散的,这使得在 NLP 中采用 DA 方法更加困难且探索不足。
最近提出了大量的 DA 方法,对现有方法的调查有利于研究人员跟上创新的速度。之前的两项调查都提供了 NLP DA 的鸟瞰图。他们直接按照方法来划分类别。因此,这些类别往往过于有限或过于笼统,例如,反向翻译和基于模型的技术。Baier在 DA 上发布仅用于文本分类的综述。在本次调研中,我们将全面概述 NLP 中的 DA 方法。我们的主要目标之一是展示 DA 的本质,即为什么数据增强有效。为了促进这一点,我们根据增强数据的多样性对 DA 方法进行分类,因为提高训练数据的多样性是 DA 有效性的主要推动力之一。我们将 DA 方法分为三类,包括改写、噪声和采样。
该论文着手根据上述类别详细分析 DA 方法。此外,还介绍了它们在 NLP 任务中的应用以及面临的挑战。
具体内容
一共分为五大部分。
全面回顾了这三个类别,并分析了这些类别中的每一种方法。还介绍了方法的特征,例如粒度和级别:
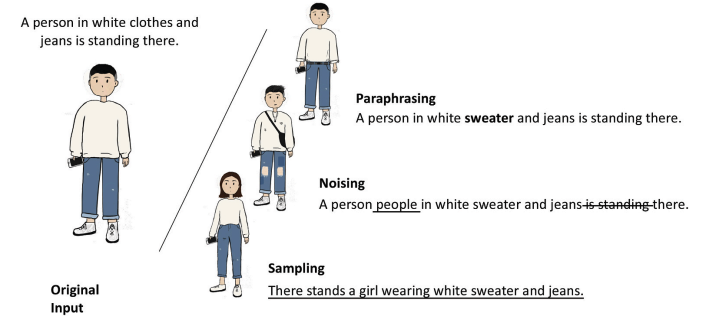
基于改写(paraphrasing)的方法
基于对句子的适当和有限制的更改,生成与原始数据具有有限语义差异的增强数据。增强数据传达与原始形式非常相似的信息。
基于噪声(noising)的方法
在保证有效性的前提下加入离散或连续的噪声。这些方法的重点是提高模型的鲁棒性。
基于抽样(sampling)的方法
掌握数据分布并对其中的新数据进行抽样。这些方法输出更多样化的数据,满足基于人工启发式和训练模型的下游任务的更多需求。
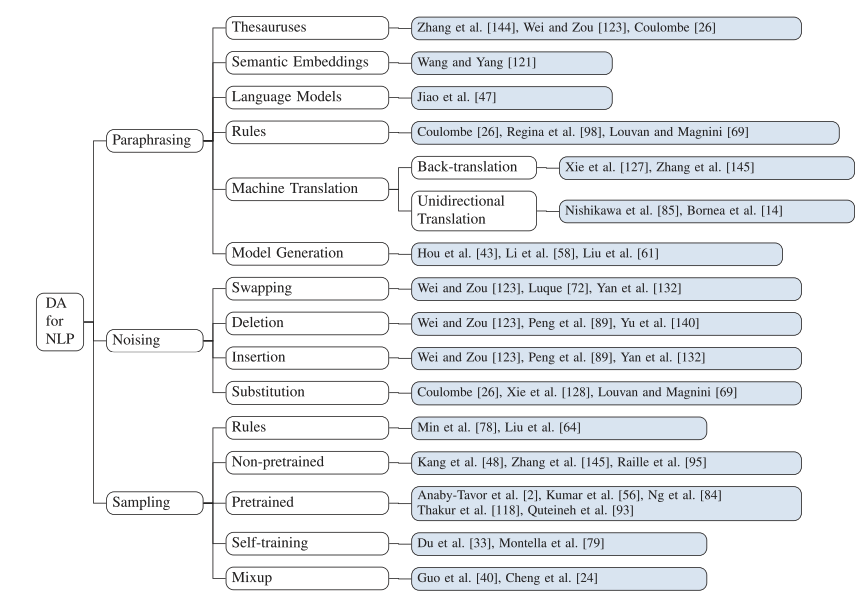

改写数据增强技术包括三个层次:词级、短语级和句子级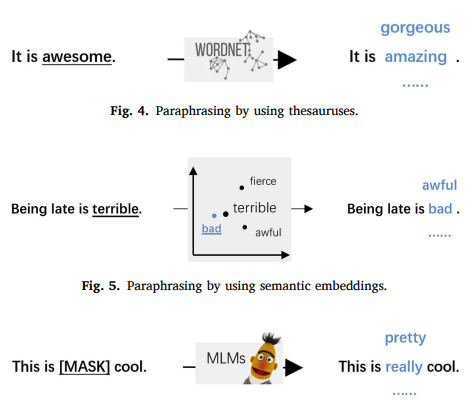
使用语言模型进行改写
使用规则进行改写
机器翻译改写
通过模型生成进行改写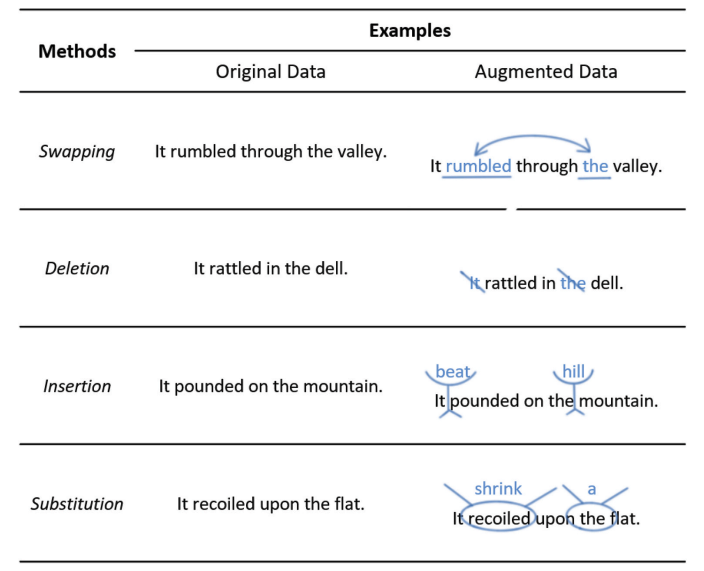
五种基于噪声的方法的示例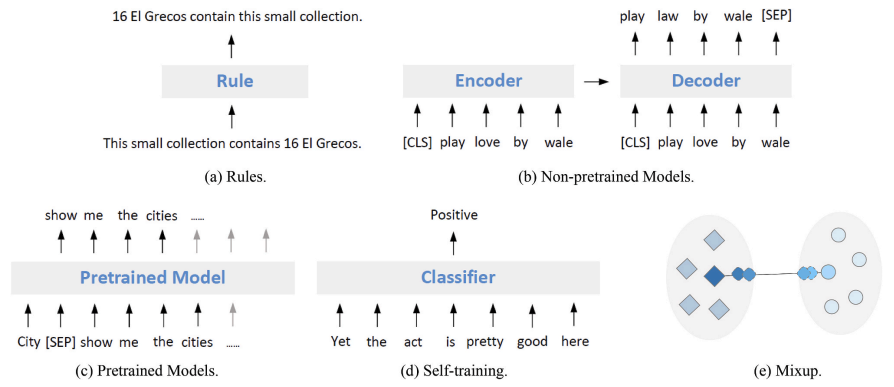
基于采样的模型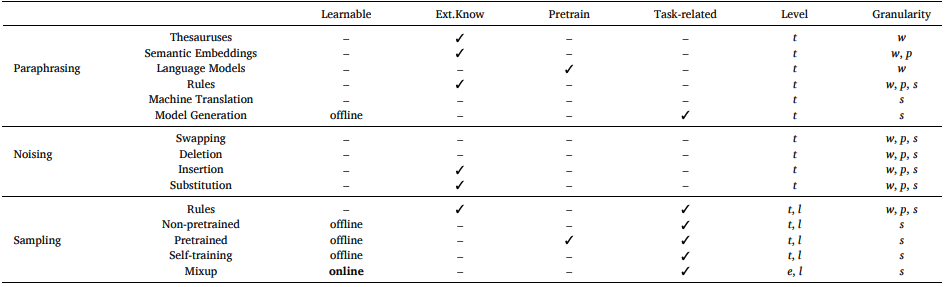
不同DA方法的特点。Learnable表示方法是否涉及模型训练;online 和 offline 表示 DA 过程是在模型训练期间还是之后
总结了提高增强数据质量的常用策略和技巧,包括方法堆叠、优化和过滤策略。
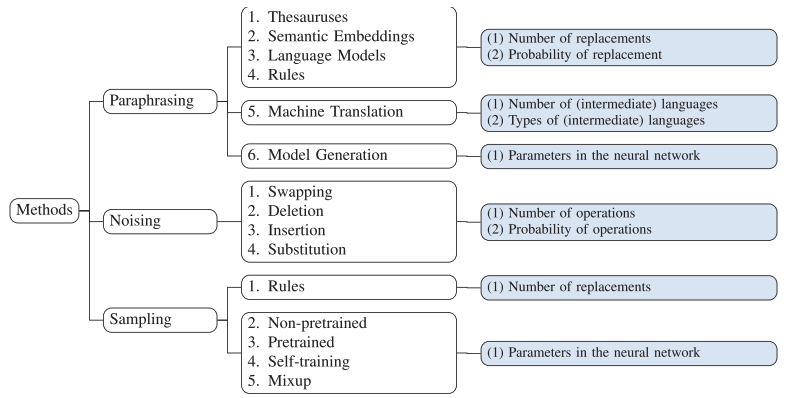
影响每个 DA 方法中增强效果的超参数
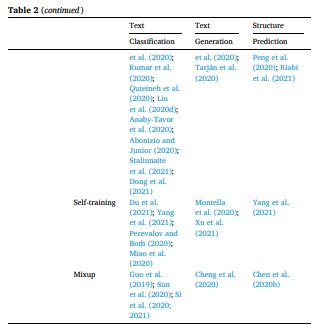
分析了上述方法在 NLP 任务中的应用,还通过时间线展示了 DA 方法的发展。



介绍了数据增强的一些相关主题,包括预训练语言模型、对比学习、相似数据操作方法、生成对抗网络和对抗攻击。目标是将数据增强与其他主题联系起来,同时展示它们的不同之处。
列出了在 NLP 数据增强中观察到的一些挑战,包括理论叙述和通用方法,揭示了数据增强未来的发展方向。
公开资源
一些有用的api:
除了英语,也有其他语种的工具资源:
总结
在本文中,作者对自然语言处理的数据增强进行了全面和结构化的调研。为了检验 DA 的性质,根据增强数据的多样性将 DA 方法分为三类,包括改写、噪声和采样。这些类别有助于理解和开发 DA 方法。
还介绍了 DA 方法的特点及其在 NLP 任务中的应用,然后通过时间线对其进行了分析。
此外,还介绍了一些技巧和策略,以便研究人员和从业者可以参考以获得更好的模型性能。最后,我们将 DA 与一些相关主题区分开来,并概述了当前的挑战以及未来研究的机遇。
审核编辑:刘清
-
计算机视觉
+关注
关注
9文章
1716浏览量
47737 -
自然语言处理
+关注
关注
1文章
630浏览量
14737 -
nlp
+关注
关注
1文章
491浏览量
23347
原文标题:NLP中关于数据增强的最新综述
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
MOS管驱动电路综述
数据融合技术综述
NLP的介绍和如何利用机器学习进行NLP以及三种NLP技术的详细介绍

NLP-Progress库NLP的最新数据集、论文和代码
NLP 2019 Highlights 给NLP从业者的一个参考
一种单独适配于NER的数据增强方法
NLP事件抽取综述之挑战与展望
基于图像的数据增强方法发展现状综述




评论