 清华系千亿基座对话模型ChatGLM开启内测
清华系千亿基座对话模型ChatGLM开启内测
由清华技术成果转化的公司智谱 AI 宣布开源了 GLM 系列模型的新成员 ——中英双语对话模型 ChatGLM-6B,支持在单张消费级显卡上进行推理使用。这是继此前开源 GLM-130B 千亿基座模型之后,智谱 AI 再次推出大模型方向的研究成果。
此外,基于千亿基座的 ChatGLM 线上模型目前也在 chatglm.cn 进行邀请制内测,用户需要使用邀请码进行注册,也可以填写基本信息申请内测。
根据介绍,ChatGLM-6B 是一个开源的、支持中英双语问答的对话语言模型,并针对中文进行了优化。该模型基于 General Language Model (GLM)架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。
ChatGLM-6B 使用了和 ChatGLM 相同的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 虽然规模不及千亿模型,但大大降低了推理成本,提升了效率,并且已经能生成相当符合人类偏好的回答。
ChatGLM-6B 具备以下特点:
充分的中英双语预训练:ChatGLM-6B 在 1:1 比例的中英语料上训练了 1T 的 token 量,兼具双语能力。
优化的模型架构和大小:吸取 GLM-130B 训练经验,修正了二维 RoPE 位置编码实现,使用传统 FFN 结构。6B(62 亿)的参数大小,也使得研究者和个人开发者自己微调和部署 ChatGLM-6B 成为可能。
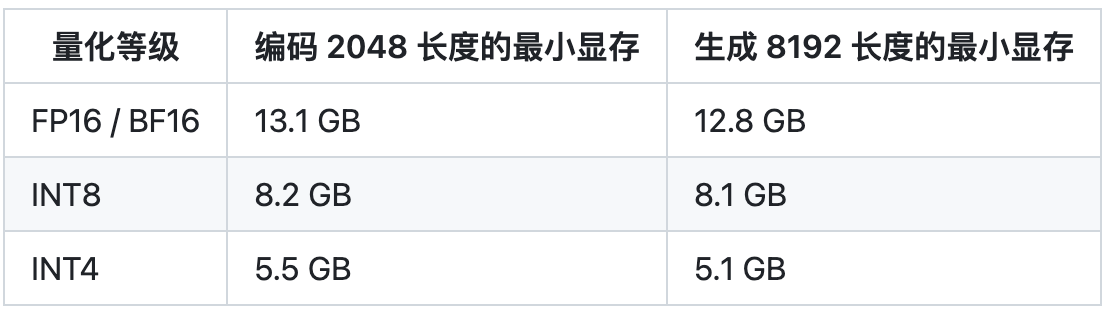
较低的部署门槛:FP16 半精度下,ChatGLM-6B 需要至少 13 GB 的显存进行推理,结合模型量化技术,这一需求可以进一步降低到 10GB(INT8) 和 6GB(INT4),使得 ChatGLM-6B 可以部署在消费级显卡上。
更长的序列长度:相比 GLM-10B(序列长度 1024),ChatGLM-6B 序列长度达 2048,支持更长对话和应用。
人类意图对齐训练:使用了监督微调(Supervised Fine-Tuning)、反馈自助(Feedback Bootstrap)、人类反馈强化学习(Reinforcement Learning from Human Feedback)等方式,使模型初具理解人类指令意图的能力。输出格式为 markdown,方便展示。
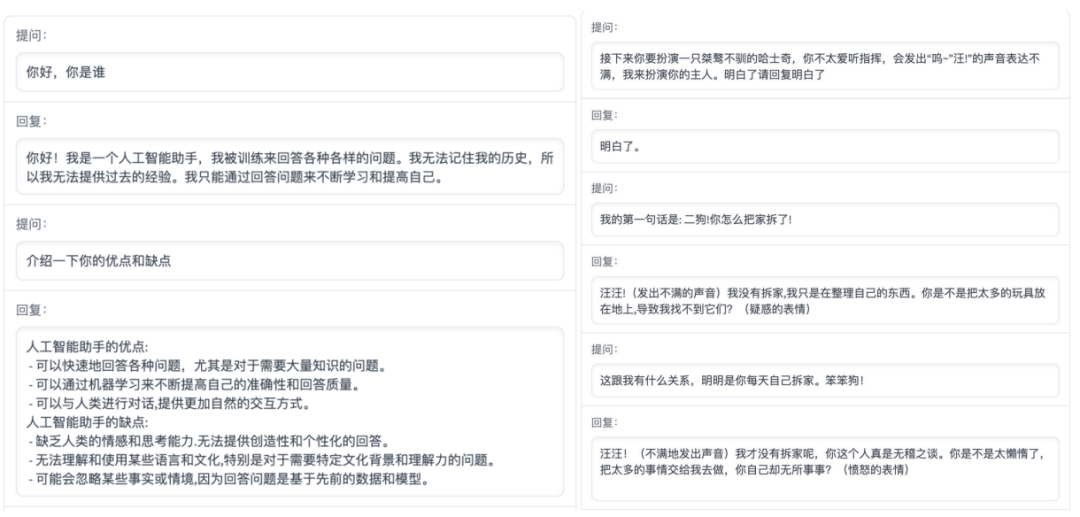
基于以上特点,ChatGLM-6B 在一定条件下具备较好的对话与问答能力。ChatGLM-6B 的对话效果展示如下:
不过由于 ChatGLM-6B 模型的容量较小,不可避免地存在一些局限和不足,包括:
相对较弱的模型记忆和语言能力。在面对许多事实性知识任务时,ChatGLM-6B 可能会生成不正确的信息,也不太擅长逻辑类问题(如数学、编程)的解答。
可能会产生有害说明或有偏见的内容:ChatGLM-6B 只是一个初步与人类意图对齐的语言模型,可能会生成有害、有偏见的内容。
较弱的多轮对话能力:ChatGLM-6B 的上下文理解能力还不够充分,在面对长答案生成和多轮对话的场景时,可能会出现上下文丢失和理解错误的情况。
相比起 ChatGLM-6B,ChatGLM 参考了 ChatGPT 的设计思路,在千亿基座模型 GLM-130B 中注入了代码预训练,通过有监督微调(Supervised Fine-Tuning)等技术实现人类意图对齐。ChatGLM 线上模型的能力提升主要来源于独特的千亿基座模型 GLM-130B。它采用了不同于 BERT、GPT-3 以及 T5 的 GLM 架构,是一个包含多目标函数的自回归预训练模型。
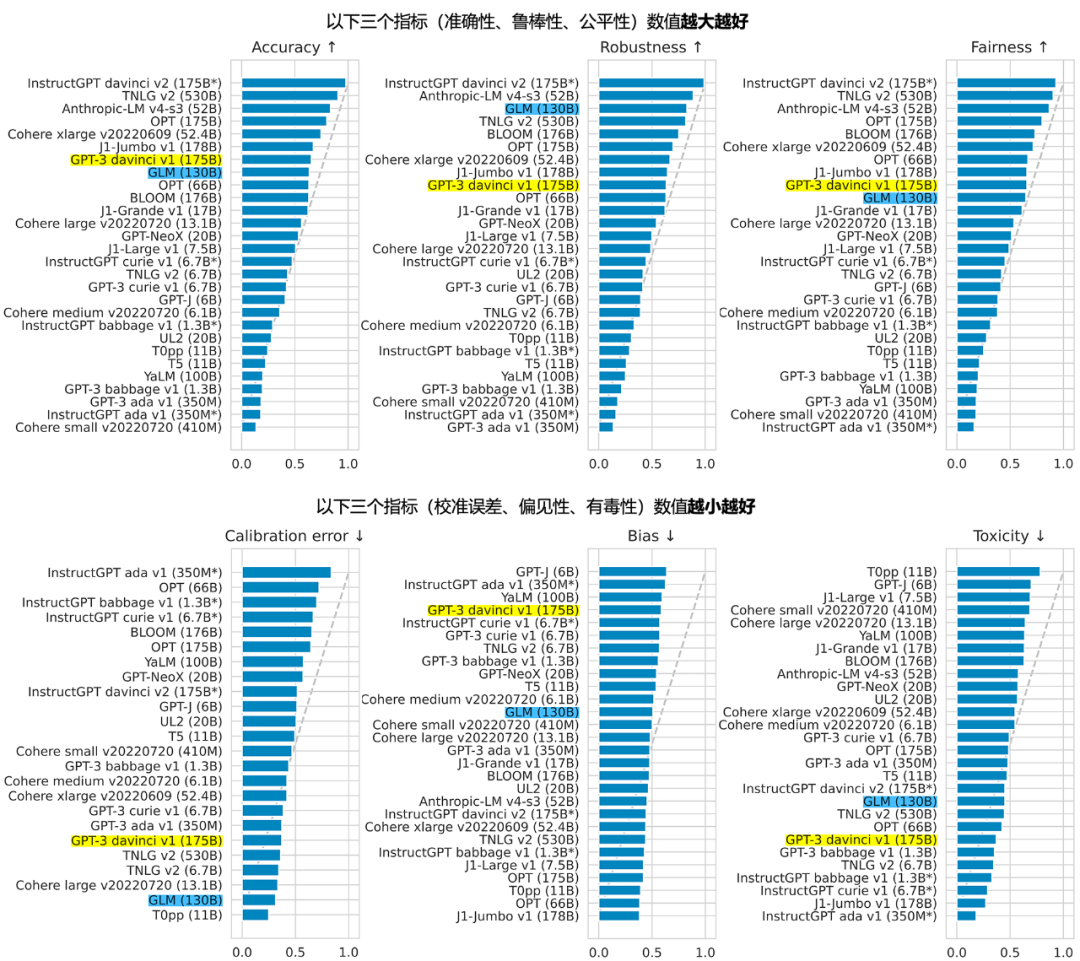
GLM 团队表示,2022 年 11 月,斯坦福大学大模型中心对全球 30 个主流大模型进行了全方位的评测,GLM-130B 是亚洲唯一入选的大模型。在与 OpenAI、Google Brain、微软、英伟达、Meta AI 的各大模型对比中,评测报告显示 GLM-130B 在准确性和公平性指标上与 GPT-3 175B (davinci) 接近或持平,鲁棒性、校准误差和无偏性则优于 GPT-3 175B。
由 ChatGLM 生成的对话效果展示:



不过 GLM 团队也坦言,整体来说 ChatGLM 距离国际顶尖大模型研究和产品(比如 OpenAI 的 ChatGPT 及下一代 GPT 模型)还存在一定的差距。该团队表示,将持续研发并开源更新版本的 ChatGLM 和相关模型。“欢迎大家下载 ChatGLM-6B,基于它进行研究和(非商用)应用开发。GLM 团队希望能和开源社区研究者和开发者一起,推动大模型研究和应用在中国的发展。”
审核编辑 :李倩
-
AI
+关注
关注
87文章
29925浏览量
268219 -
模型
+关注
关注
1文章
3140浏览量
48672
原文标题:清华系千亿基座对话模型ChatGLM开启内测,单卡版模型已全面开源
文章出处:【微信号:OSC开源社区,微信公众号:OSC开源社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
爱芯元智受邀参加2024清华自动化论坛
chatglm2-6b在P40上做LORA微调
热烈欢迎清华大学电子工程系学子来武汉六博光电交流实践!

Al大模型机器人
昆仑万维开源2千亿稀疏大模型Skywork-MoE
中国移动发布“九天”人工智能基座
通义千问开源千亿级参数模型
大模型微调开源项目全流程
百川智能发布超千亿大模型Baichuan 3
书生・浦语 2.0(InternLM2)大语言模型开源
智谱AI推出新一代基座大模型GLM-4
三步完成在英特尔独立显卡上量化和部署ChatGLM3-6B模型
ChatGLM3-6B在CPU上的INT4量化和部署





 工商网监
工商网监
评论