 Python多线程的使用
Python多线程的使用

前言
最近常常需要处理大量的crash数据,对这些数据进行分析,在此之前需要将存量的数据导入自己的数据库,开始一天一天的去导,发现太慢了,后来尝试通过python多线程并行导入多天数据,以此记录对于Python多线程的使用。
进程与线程
在介绍Python的多线程之前,我们需要先明确一下线程和进程的概念,其实线程和进程是操作系统的基本概念,都是实现并发的方式,其二者的区别可以用一句话概括:进程是资源分配的最小单位,而线程是调度的最小单位。 线程是进程的一部分,一个进程含有一个或多个线程。
threading的使用
Python提供了threading库来实现多线程,其使用多线程的方式有两种,一种是直接调用如下:
import threading
import time
def say(index):
print("thread%s is running" % index)
time.sleep(1)
print("thread%s is over" % index)
if __name__ == "__main__":
threading.Thread(target=say, args=(1,)).start()
❝需要注意的是函数入参的传入是通过元组实现的,如果只有一个参数,","是不能省略的。
❞
除了以上方法,还可以通过继承threading.Thread来实现,代码如下。
import threading
import time
class MyThread(threading.Thread):
def __init__(self, index):
threading.Thread.__init__(self) # 必须的步骤
self.index = index
def run(self):
print("thread%s is running" % self.index)
time.sleep(1)
print("thread%s is over" % self.index)
if __name__ == "__main__":
myThread = MyThread(1)
myThread.start()
在threading中提供了很多方法,主要可以分为两个部分,一部分是关于线程信息的函数,一部分是线程对象的函数。
线程信息的函数
| 函数 | 说明 |
|---|---|
| threading.active_count() | 活跃线程Thread的数量 |
| threading.current_thread() | 返回当前线程的thread对象 |
| threading.enumerate() | 返回当前存活线程的列表 |
| threading.main_thread() | 返回当前主线程的Thread对象 |
线程对象Thread的函数和属性
| 函数 | 说明 |
|---|---|
| Thread.name | 线程名,可相同 |
| Thread.ident | 线程标识符,非零整数 |
| Thread.Daemon | 是否为守护线程 |
| Thread.is_alive() | 是否存活 |
| Thread.start() | 开启线程,多次调用会报错 |
| Thread.join(timeout=None) | 等待线程结束 |
| Thread(group=None, target=None, name=None, args=(), kwargs={}, *, deamon=None) | 构造函数 |
| Thread.run() | 用来重载 |
线程池
线程可以提高程序的并行性,提高程序执行的效率,虽然python的多线程只是一种假象的多线程,但是在一些io密集的程序中还是可以提高执行效率,其中的细节会在后面详细解释。在多线程中线程的调度也会造成一定的开销,线程数量越多,调度开销越大,所以我们需要控制线程的数量,使用join可以在主线程等待子线程执行结束,从而控制线程的数量。其代码如下
import threading
import time
def say(index):
print("thread%s is running" % index)
time.sleep(1)
print("thread%s is over" % index)
if __name__ == "__main__":
for i in range(1, 4, 2):
thread1 = threading.Thread(target=say, args=(i,))
thread2 = threading.Thread(target=say, args=(i + 1,))
thread1.start()
thread2.start()
thread1.join()
thread2.join()
结果如下
thread1 is running
thread2 is running
thread1 is over
thread2 is over
thread3 is running
thread4 is running
thread3 is over
thread4 is over
如果不使用join其结果如下:
thread1 is running
thread2 is running
thread3 is running
thread4 is running
thread1 is over
thread2 is over
thread4 is over
thread3 is over
这时候是同时启动了四个线程
使用join来控制线程数量虽然可以达到目的,但是这样的实现确实很不优雅,而且线程的创建和销毁也是很大的开销,所以针对一些执行频率高且执行时间短的情况,可以使用线程池,线程池顾名思义就是一个包含固定数量线程的池子,线程池里面的线程是可以重复利用的,执行完任务后不会立刻销毁而且返回线程池中等待,如果有任务则立即执行下一个任务。
python中的concurrent.futures模块提供了ThreadPoolExector类来创建线程池,其提供了以下方法:
| 函数 | 说明 |
|---|---|
| submit(fn, *args, **kwargs) | 将 fn 函数提交给线程池。args 代表传给 fn 函数的参数,kwargs 代表以关键字参数的形式为 fn 函数传入参数。 |
| map(func, *iterables, timeout=None, chunksize=1) | 该函数将会启动多个线程,以异步方式立即对 iterables 执行 map 处理。超时抛出TimeoutError错误。返回每个函数的结果,注意不是返回future。 |
| shutdown(wait=True) | 关闭线程池。关闭之后线程池不再接受新任务,但会将之前提交的任务完成。 |
有一些函数的执行是有返回值的,将任务通过submit提交给线程池后,会返回一个Future对象,Future有以下几个方法:
| 函数 | 说明 |
|---|---|
| cancel() | 取消该 Future 代表的线程任务。如果该任务正在执行,不可取消,则该方法返回 False;否则,程序会取消该任务,并返回 True。 |
| cancelled() | 如果该 Future 代表的线程任务正在执行、不可被取消,该方法返回 True。 |
| running() | 如果该 Future 代表的线程任务正在执行、不可被取消,该方法返回 True。 |
| done() | 如果该 Funture 代表的线程任务被成功取消或执行完成,则该方法返回 True。 |
| result(timeout=None) | 获取该 Future 代表的线程任务最后返回的结果。如果 Future 代表的线程任务还未完成,该方法将会阻塞当前线程,其中 timeout 参数指定最多阻塞多少秒。超时抛出TimeoutError,取消抛出CancelledError。 |
| exception(timeout=None) | 获取该 Future 代表的线程任务所引发的异常。如果该任务成功完成,没有异常,则该方法返回 None。 |
| add_done_callback(fn) | 为该 Future 代表的线程任务注册一个“回调函数”,当该任务成功完成时,程序会自动触发该 fn 函数,参数是future。 |
之前的问题可以用线程池,代码如下
import time
from concurrent.futures import ThreadPoolExecutor
def say(index):
print("thread%s is running" % index)
time.sleep(1)
print("thread%s is over" % index)
if __name__ == "__main__":
params = tuple()
for i in range(1, 11):
params = params + (i,)
pool = ThreadPoolExecutor(max_workers=2)
pool.map(say, params)
线程安全与锁
正如之前所提到的,线程之间是共享资源的,所以当多个线程同时访问或处理同一资源时会产生一定的问题,会造成资源损坏或者与预期不一致。例如以下程序最后执行结果是157296且每次结果都不一样。
import threading
import time
lock = threading.Lock()
def task():
global a
for i in range(100000):
a = a + 1
if i == 50:
time.sleep(1)
if __name__ == "__main__":
global a
a = 0
thread1 = threading.Thread(target=task)
thread2 = threading.Thread(target=task)
thread1.start()
thread2.start()
thread1.join()
thread2.join()
print(a)
这时候就需要用到锁,是使用之前将资源锁定,锁定期间不允许其他线程访问,使用完之后再释放锁。在python的threading模块中有Lock和RLock两个类,它们都有两个方法,Lock.acquire(blocking=True, timeout=-1) 获取锁。Lock.release() 释放锁。其二者的区别在于RLock是可重入锁,一个线程可以多次获取,主要是为了避免死锁。一个简单的例子,以下代码会死锁
Lock.acquire()
Lock.acquire()
Lock.release()
Lock.release()
用RLock则不会死锁
RLock.acquire()
RLock.acquire()
RLock.release()
RLock.release()
❝死锁(Deadlock)是指两个或两个以上的线程在执行过程中,由于竞争资源或者由于彼此通信而造成的一种阻塞的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程。
❞
以上代码加锁后就可以得到想要的结果了,其代码如下
import threading
import time
lock = threading.Lock()
def task():
global a
for i in range(100000):
lock.acquire()
a = a + 1
lock.release()
if i == 50:
time.sleep(1)
if __name__ == "__main__":
global a
a = 0
thread1 = threading.Thread(target=task)
thread2 = threading.Thread(target=task)
thread1.start()
thread2.start()
thread1.join()
thread2.join()
print(a)
假的多线程
关于python多线程的简单使用已经讲完了,现在回到之前文中提到的,python的多线程是假的多线程,为什么这么说呢,因为Python中有一个GIL,GIL的全称是Global Interpreter Lock(全局解释器锁),并且由于GIL锁存在,python里一个进程永远只能同时执行一个线程(拿到GIL的线程才能执行),这就是为什么在多核CPU上,python的多线程效率并不高。对于计算密集型的Python多线程并不会提高执行效率,甚至可能因为线程切换开销过大导致性能还不如单线程。但是对于IO密集型的任务,Python多线程还是可以提高效率。
-
数据
+关注
关注
8文章
7361浏览量
95136 -
多线程
+关注
关注
0文章
279浏览量
21141 -
python
+关注
关注
59文章
4891浏览量
90395
发布评论请先 登录
Python多线程编程运行【python简单入门】
Python多线程编程原理
浅析Python使用多线程实现串口收发数据
python多线程和多进程对比
python多线程与多进程的区别
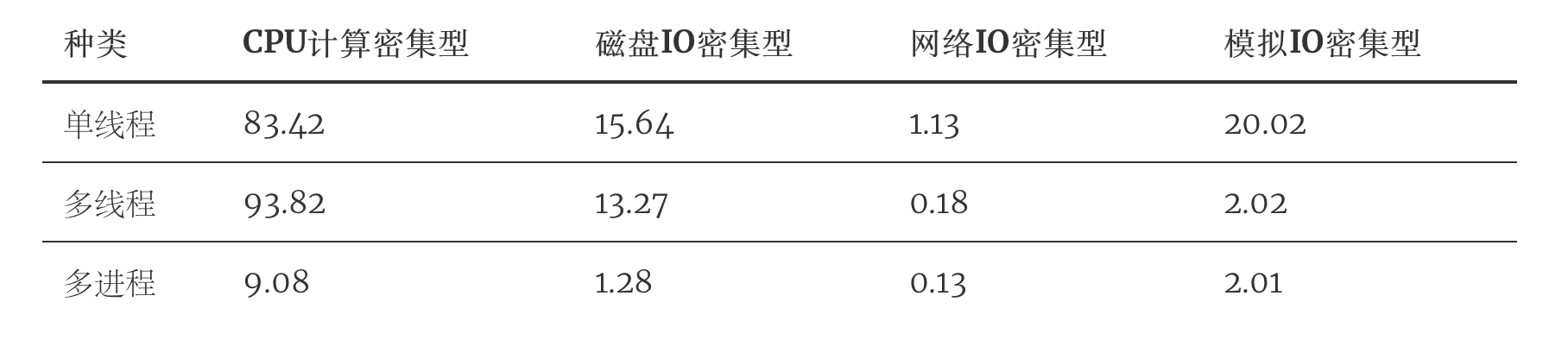
python多线程和多进程的对比




评论