 分布式文件系统的设计框架
分布式文件系统的设计框架

一、硬件故障检测
因为HDFS系统(分布式文件系统)可由数百或数千个存储文件数据片段的服务器组成,即HDFS系统包含较多的硬件设备,所以HDFS系统的硬件故障是常态,而非异常态。因此,HDFS系统的设计框架需包含故障检测和数据自动快速恢复。
HDFS系统故障检测和数据自动快速恢复功能具体过程如下:HDFS系统将数据分块,即数据块的形式存储于不同硬件设备中。通常,每个数据块在HDFS系统被存放于三个硬件设备中,即每个数据块的份数是三份。当某一硬件设备出现故障时,HDFS系统在检测到该设备故障后,可根据其他硬件设备的备份,将该硬件设备的数据再复制一遍,使HDFS系统中每个数据块的份数保持在三份。
二、数据访问
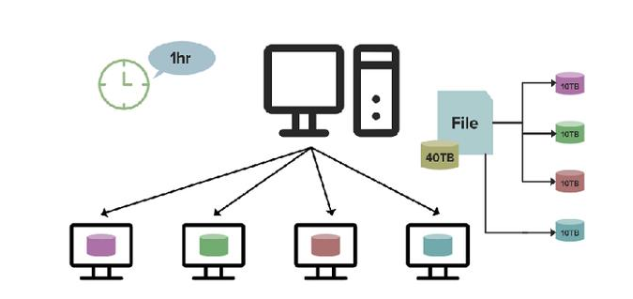
HDFS系统被设计为适合批量处理数据,具有较大的数据吞吐量。HDFS系统不适合交互式访问。交互式访问是指用户在客户端输入命令,系统可立即对用户命令做出反应。交互式访问需要系统具有较快速的反应时间,而HDFS系统处理数据的速度可能是几个小时或几天,因此,HDFS系统的速度不足以支持交互式访问。
图片来源:学堂在线《大数据导论》
三、大数据集
HDFS系统(分布式文件系统)的数据集群被设计为可包含数百个节点(个人理解:计算机或服务器均可作为HDFS系统的节点),百度最大的HDFS系统数据集群可能包含4000个节点。
HDFS系统的数据存储量可达至100TB的数量级,一些HDFS系统的数据存储量可超过该数量级。
HDFS系统被设计为可支持大文件存储。数据量越大,HDFS系统的支持量越好。相对于大文件存储,HDFS系统比较不适合存储零散的小文件,这是因为所存储的文件越小,主节点记录文件存储节点的日志文件(个人理解:存储节点的日志文件包含数据的存储位置等信息)越大,主节点的压力越大。
四、简单一致性模型
HDFS系统被设计为简单一致性模型。简单一致性模型是指多数HDFS系统的文件操作模式是一次写入多次读取,即文件一旦被创建、写入、关闭后,就不再需要修改。HDFS系统不适合对文件进行频繁的修改和删除。
五、将计算移动至数据
数据计算的最理想状态是在靠近数据的存储位置计算,如果不能实现数据计算的最理想状态,则需要通过将数据移动至计算或将计算移动至数据后再进行数据计算。
HDFS系统的数据计算方式是通过将计算移动至数据后再进行数据计算。将HDFS系统的数据存储于多个数据节点,在计算过程中,可根据数据节点所存储的数据进行相应计算,各数据节点计算结束后,再将各数据节点计算结果汇总。
HDFS系统的数据计算方式适合大数据的计算,并且可以消除网络拥堵,提高系统整体的吞吐量,数据计算的成本更低。如果将超过100TB的数据移动至计算中心,数据计算的速度将低于HDFS系统的数据计算方式,而且由于数据量大,网络需要承受较大的压力,容易造成拥堵,数据计算的成本更高。
六、异构软硬件平台间的可移植性
HDFS系统被设计为可简便地实现平台间的迁移,即不同的操作系统均可使用HDFS系统。该特点可推动大数据集应用更多采用HDFS系统。
审核编辑:刘清
-
服务器
+关注
关注
14文章
10347浏览量
91741 -
存储数据
+关注
关注
0文章
90浏览量
14490 -
HDFS
+关注
关注
1文章
32浏览量
10140
原文标题:大数据相关介绍(20)——分布式文件系统的设计框架
文章出处:【微信号:行业学习与研究,微信公众号:行业学习与研究】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
一文解读在RTThread平台上使用DFS分布式文件系统
HarmonyOS分布式文件系统开发指导
采用信任管理的分布式文件系统TrustFs
海量邮件分布式文件系统的设计与实现
基于分布式文件系统元数据操作优化
盘点一下这些常见的分布式文件系统
AFS,GFS ,QKFile主流分布式存储文件系统
解析夸克分布式文件系统如何实现资源共享
分布式文件存储系统GFS的基础知识
分布式文件系统主从式的伸缩性架构设计



评论