 Linux内核的链表数据结构
Linux内核的链表数据结构
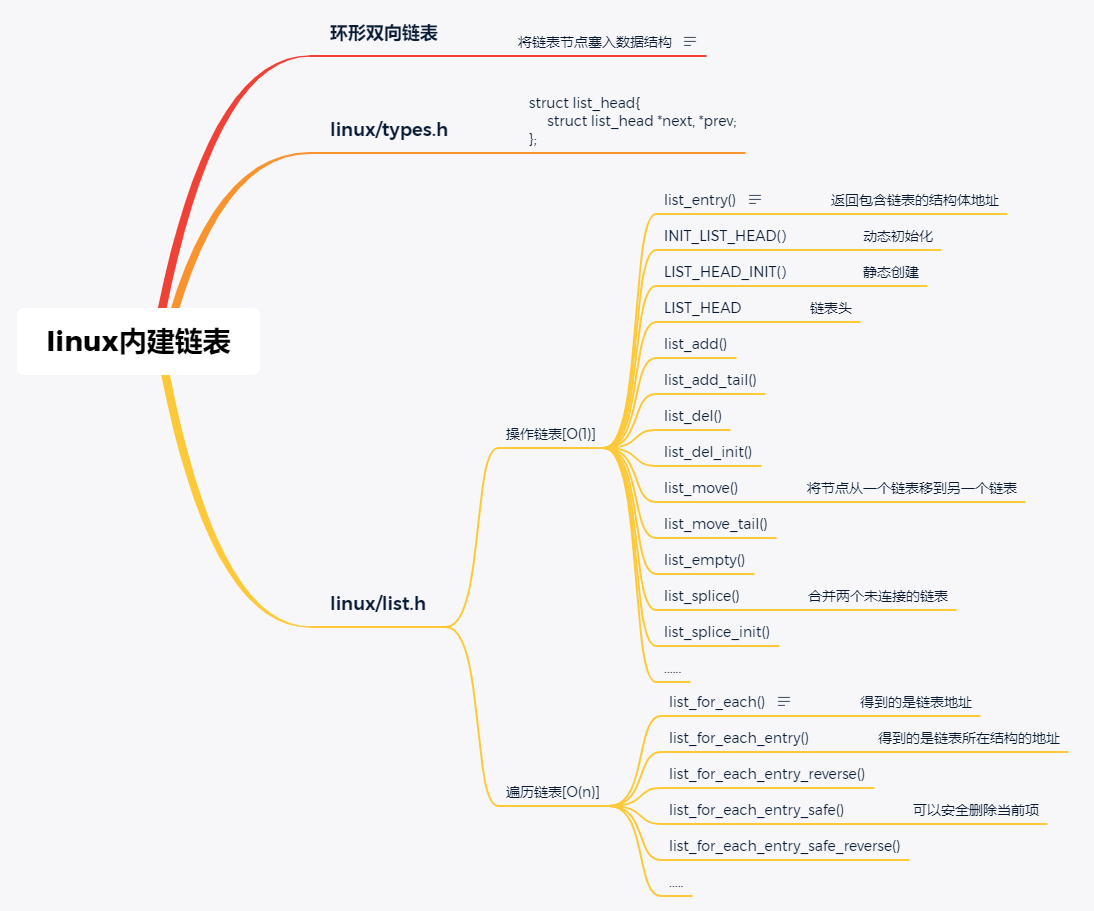
Linux内核实现了自己的链表数据结构,它的设计与传统的方式不同,非常巧妙也很通用。
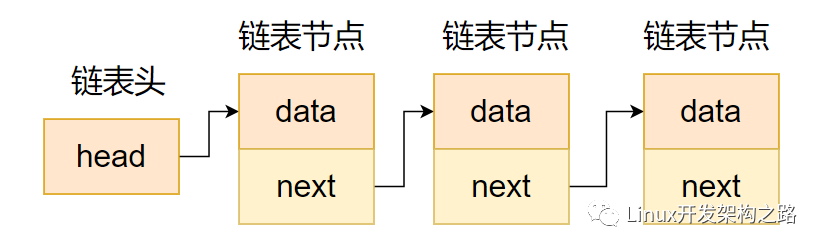
我们先看一下传统的定义
struct xxx{
void * p;
struct xxx * next,* prev;
}
这种方式将数据和链表指针定义在一起,整个链表也是通过整个结构体连接起来的。 这种链表不具有通用性,换一个不同的结构体需要重新定义。
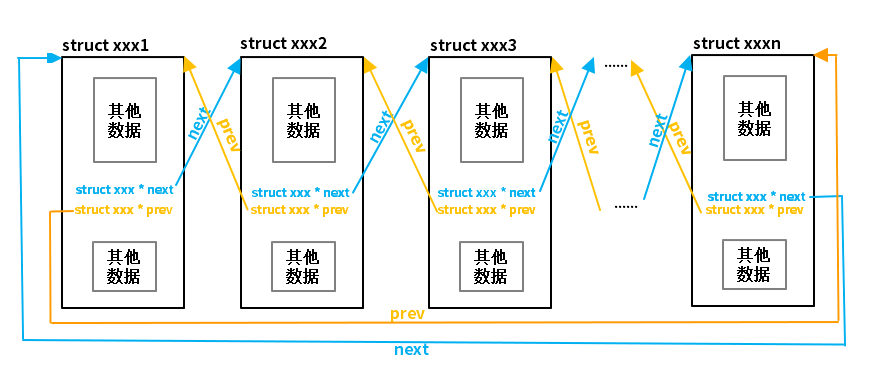
内核使用了不同的方式,它把链表的指针抽象出来,独立定义。
struct list_head{
struct list_head *next, *prev;
};
使用的时候嵌入到结构体中即可。
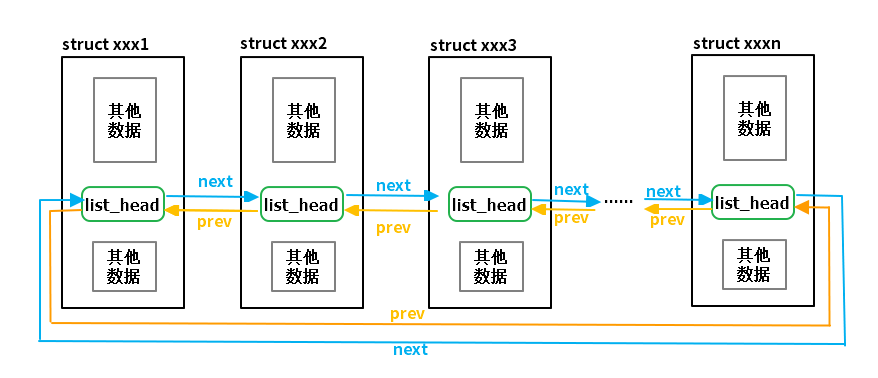
这种方式将数据和链表剥离开来,去除了链表和数据的耦合,这样就可以定义统一的接口,使得链表的管理和操作变得非常简洁。
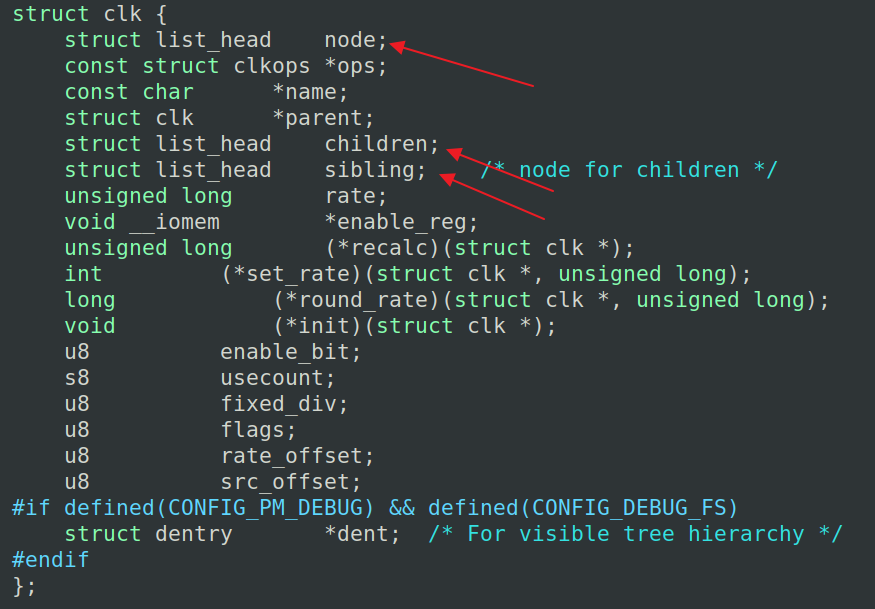
内核在
大家发现一个问题没有,我们如何获得链表所在结构体其他数据呢?
内核使用container_of()函数实现,这个函数能够通过结构体内部成员的地址找到结构体本身的地址,这样就可以通过链表的地址得到数据结构体的地址,然后就可以获得其他数据了。 这些在链表的操作方法中都已经实现了。
链表在内核中非常重要,比如所有进程就是通过链表管理,进程的子进程、兄弟进程也是链表管理,这些在进程描述符中都可以看到。
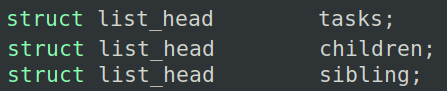
一个结构中可以包含多个不同的链表节点,分别从属于不同的链表,构成一个错综复杂的网络结构。
小结:
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
内核
+关注
关注
3文章
1372浏览量
40276 -
Linux
+关注
关注
87文章
11292浏览量
209326 -
数据结构
+关注
关注
3文章
573浏览量
40123 -
结构体
+关注
关注
1文章
130浏览量
10840 -
链表
+关注
关注
0文章
80浏览量
10558
发布评论请先 登录
相关推荐
数据结构中最简单的链表
数据结构作为嵌入式工程师必修课程之一,今天,我们就来讲一讲数据结构中最简单的链表,包含链表的初始化、插入和遍历操作。 链表在项目开发中使用的
发表于 06-13 17:40
•367次阅读
Linux内核中的数据结构的一点认识
大家都知道linux内核是世界上优秀的软件之一,作为一款优秀的软件,其中的许多的设计都精妙之处,十分值得学习和借鉴。今天我们就带大家看一下内核中的数据结构中一点设计。打开
发表于 04-20 16:42
OpenHarmony——内核IPC机制数据结构解析
通信的数据结构,可以在任务间传递消息内容或消息的地址。内核用队列控制块来管理消息队列,同时又使用双向环形链表来管理控制块。队列控制块: 管理具体消息队列的数据块,
发表于 09-05 11:02
OpenHarmony——内核IPC机制数据结构解析
通信的数据结构,可以在任务间传递消息内容或消息的地址。内核用队列控制块来管理消息队列,同时又使用双向环形链表来管理控制块。队列控制块:管理具体消息队列的数据块,
发表于 09-08 11:44

Linux 内核数据结构:位图(Bitmap)
除了各种链式和树形数据结构,Linux内核还提供了位图接口。位图在Linux内核中大量使用。下面的源代码文件包含这些
发表于 05-14 17:24
•3475次阅读
你知道Linux内核数据结构中双向链表的作用?
Linux 内核提供一套双向链表的实现,你可以在 include/linux/list.h 中找到。我们以双向链表着手开始介绍
发表于 05-14 17:27
•1876次阅读





 工商网监
工商网监
评论