 半导体Chiplet缓解先进制程焦虑
半导体Chiplet缓解先进制程焦虑
1. Chiplet:延续摩尔定律,规模化落地可期
1.1. Chiplet 综合优势明显,有效延续摩尔定律
摩尔定律实现的维度主要分为制造、设计、封装三方面。在制造方面, 主要通过晶体管微缩工艺实现,从 130nm 逐步向 5nm 甚至是 2nm 迈进; 在设计方面,主要通过各种架构演进、方案设计等方式实现;在封装方 面,主要通过不同模块的异质集成来实现,通过 SiP、WLP 等方法不断 提高系统化的集成密度。
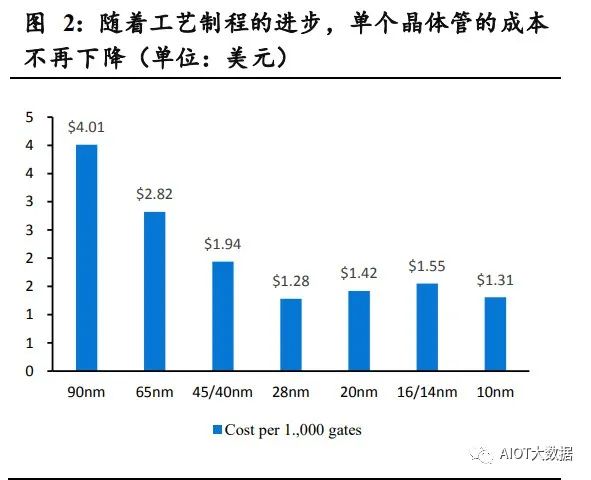
摩尔定律在制造端的提升已经逼近极限,开始逐步将重心转向封装端和 设计端。随着 AI、数字经济等应用场景的爆发,对算力的需求更加旺盛, 芯片的性能要求也在不断提高,业界芯片的制造工艺从 28nm 向 7nm 以 下发展,TSMC 甚至已经有了 2nm 芯片的风险量产规划。但随着线宽逐 步逼近原子级别,工艺制程升级带来的性能、功耗提升的性价比越来越 低,封装端和设计端维度的提升开始逐步进入视野。
Chiplet 方案正是一种通过在封装端和设计端的提升,来进一步提升芯 片的集成化密度,从而延续摩尔定律的新型半导体技术方案。其方案核 心主要包含三个概念,分别是小芯粒、异构异质和系统级集成。 1)小芯粒:原有 SoC 芯片由各种 IP 内核设计组成,小芯粒即在设计端 将各种 IP 单个拆分,进行芯片化。 2)异构异质:将类似 CPU、GPU、DRAM 等不同结构工艺材质的芯 片合在一起,从而减少传输延迟、提高集成度。 3)系统级集成:在前两者的基础上,通过软件设计系统级高密度的方 案,利用各种堆叠封装技术,将更多的异构异质的小芯片进行高密度封 装集成,从而实现良率、成本、性能、商业风险等方面的综合提升。
Chiplet 方案通过将芯片性能的提升和工艺适度解耦合,能够利用先进 封装技术实现综合性能的提升,其主要原因如下:
①小芯片优化成本:将芯片分解成特定的模块,这可以使单个芯片面积 更小并可选择最合适的工艺,从而提高良率、降低制造成本和门槛。 在降低成本方面:当切割芯片的面积越小,绿色芯片的数 量就越多,整体晶圆中可用的芯片面积就越大,单位面积芯片的成本就 越低。另外,硅片化 IP 的复用,也可以显著降低成本。 在提高良率方面:晶圆中存在各种缺陷,当芯片的面积越大,它受影响 的芯片数量比例就越大。例如,一块晶圆中切割 3 片芯片, 有一片受到缺陷影响,良率为 2/3;当一块晶圆切割 25 片芯片,缺陷影 响了 3 片芯片,良率为 22/25,整体良率大于 2/3。 在降低门槛方面:小芯片化后,不同的芯片可以采用最合适的工艺和架 构进行设计制造。例如 I/O die 因为更加先进的工艺对其性能的提升有限, 可以采用 12nm 工艺进行设计制造,CPU die 因为对先进工艺要求更高, 可以采用 7nm/5nm 工艺进行设计制造。整体无需像 SoC 一样,I/O 和 CPU 的 IP 都必须采用最先进的工艺设计制造。
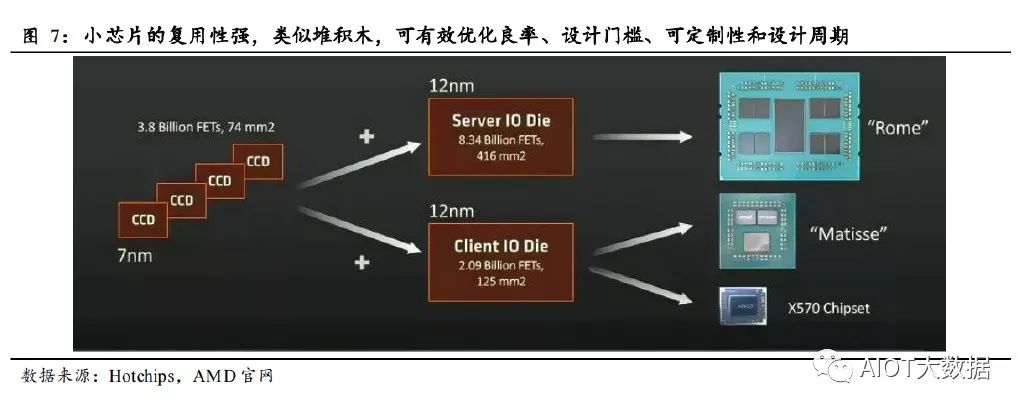
②小芯片复用性强:小芯片可视为固定模块,在不同的产品中根据需求 进行组装复用,类似乐高积木,具有极强的灵活性。通过小芯片化甚至 最理想的 IP 芯片化,不仅可以减少芯片的设计周期,加快迭代速度,还 可以提高芯片的可定制性。 以 AMD 的系列产品为例,将处理器芯片进行解耦合,分成单个 CCD (Core Chiplet Die)芯片和一个 I/O die,CCD 和 I/O 核之间采用第二代 Infinity Fabric 总线连接。其中 CCD 采用 7nm 工艺,I/O 核采用 12nm 工 艺。8 个 CCD 和 1 个 Server I/O die 可组装成 EPYC Rome(霄龙)服务 器处理器;8 个 CCD 和 1 个 Client I/O die 可组装成 Ryzen (锐龙)3000 系列(代号 Matisse)桌面服务器;AMD 的 X570 Chipset 也可用现有的 小芯片进行组装设计。 这种固定模块的小芯片方式,多个小芯片无需重复设计,具有复用价值, 而且芯片可采用最合适的工艺制程,可有效提高良率以及降低设计门槛。 在可定制性、设计周期方面、降低成本,进行极大优化。
③小芯片可高度集成化:小芯片利用芯片互连技术和高密度封装技术可 轻易集成多核,满足高效能运算处理器的需求。单片 SoC 的方案,在集 成多核方案时,受制于可用的光罩尺寸、良率等问题,芯片面积最多只 能达到 800mm2。Chiplet 核心计算单元可从 16 核堆积到 64 核,甚至 96 核以上。另外,对于内存和 Cache 方面,也能实现高密度集成,从而实现更低的延迟或者更高的并行运算速度。
1.2. 整体生态处于早期,有望加速落地
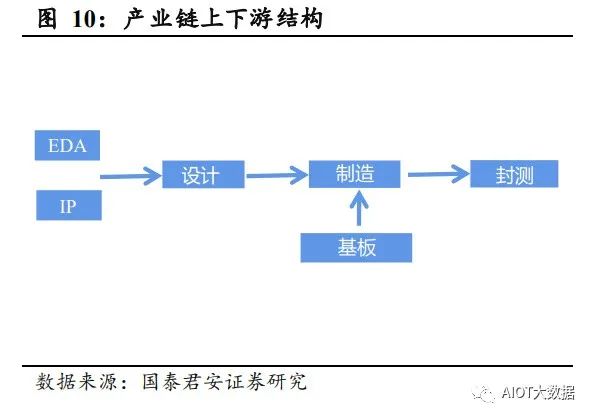
Chiplet 方案主要由三大环节组成,分别是拆、合、封。 1)在“拆”的环节:将原有多个 IP 组成的 SoC 大芯片进行拆分,形成 多个不同的 CPU、I/O 等小芯片。拆解后的小芯片可以采用更加适配的 工艺节点和材质。其中架构设计是关键,需要考虑访问频率、缓存一致 性等各问题。 2)在“合”的环节:将不同的小芯片利用内部总线互连技术进行电路 连接,各个电路互相组合,在功耗、通信延迟、带宽等方面达到最优的 效果。与 SoC 不同的是,前者是芯片间的互连,而后者是 IP 内核间的 互连。 3)在“封”的环节:将组合后的不同的芯片,利用 RDL、TSV、硅转 接板、晶圆等高密度集成的先进封装技术,进行组合。
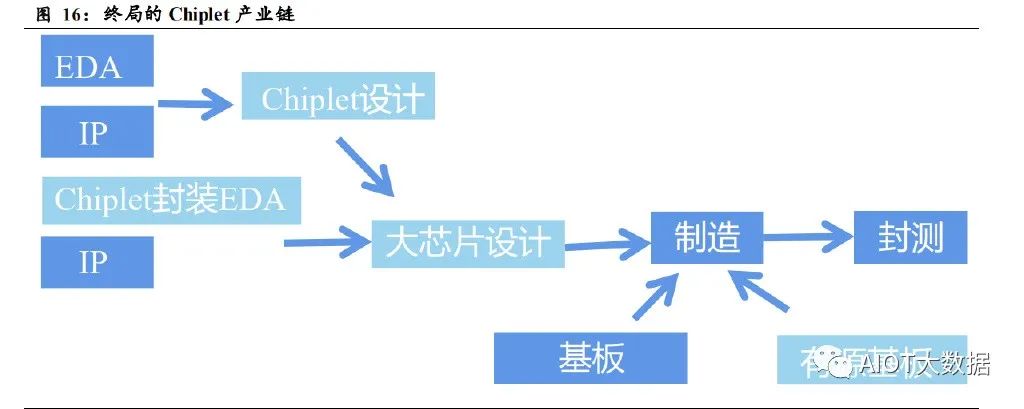
Chiplet 方案的实现包括 Chiplet 的设计制造和连接侧的互连制造。依据 主要的产业链制造顺序而言: 在设计端:利用 EDA 和 IP 核进行分割后的 Chiplet 的设计、连接侧包括 硅转接板或者 RDL 层的互连建模,之后两者协同仿真,得到完整的封 装方案的模型。针对该模型依次进行时序分析、电源网络分析、可靠性 分析以及 PPA 优化分析等,从而实现 Chiplet 和连接侧结合的系统性方 案。 在封装端:利用晶圆厂制造完成的 Chiplet 与连接侧方案进行连接,以 2.5D 的硅转接板为例,将 Chiplet 和进行 TSV 打孔的硅转接板相连,利 用硅转接板内部的 RDL 层进行各个 Chiplet 之间的互连,最后将硅转接 板与基板进行连接,即完成整体 Chiplet 系统性方案的制造。 上述在设计端和封装端的步骤,刚好对应拆、合、封三大环节。
Chiplet 方案目前无法规模化落地的主要技术难点:
一、Chiplet 的统一接口和标准
考虑到互连是 Chiplet 的核心之一,互连接口与协议的落地和推行是实 现技术标准化和产品规模化的关键。2022 年 3 月,Intel、AMD、ARM、 台积电、日月光等巨头成立 Chiplet 标准联盟,制定了通用 Chiplet 的高 速互联标准 UCI(e Universal Chiplet Interconnect express)。2021 年 5 月, CCITA(中国计算机互连技术联盟)针对 Chiplet 标准《小芯片接口总线 技术要求》展开标准制定工作,集结了国内产业链 60 多家单位共同参 与研究。 Chiplet 总线互连接口与协议可以划分为物理层(PHY 层)、数据链路层、 网络层以及传输层。数据链路层及以上的其他接口更多依赖沿用或扩展 已有接口标准及协议。最重要的是物理层的接口研究,因为它与工艺、 功耗和性能等息息相关。物理层主要分为串行和并行两种数据通信技术, 串行主要分为串行器和解串器 SerDes,并行则包括低电压封装互连 LIPINCON 技术(TSMC 提出)、AIB 高级接口总线(Intel 提出)以及信 号引线物理互连 BoW 技术(OCP 提出)等。
互连是技术标准化的重点之一,但芯片间互连协议的标准化方面仍处于 发展演进阶段,相互竞争的标准较多。包括 CXL、CCIX、NVLink 等标 准,都已经在复杂的处理器芯片中得到应用。其中虽然 CXL 发布较晚, 但因为 Intel 的业内影响力和产品效应,大多数厂商纷纷跟随并采纳,技 术发展较快。国内以 CCITA 为主导的技术联盟正在进行相关技术和标准 的研发中。相关国内公司例如超摩科技也已经宣布量产 Chiplet 互联 IP 整体解决方案 CLCI,其协议标准主要采用自有方案,未来会考虑协议 间的兼容性。
二、EDA 工具链和生态系统的完整性、可持续性
新的 EDA 工具链是急切需要的,其主要原因为: 1) 小芯片之间更密集的互连+Chiplet 封装 EDA 的更高要求 Chiplet 方案将芯片进行精细化切割,并进行更为密集的互连,例如 HBM 的芯片间的互连位宽为 1028bit,从而使其整体性能达到接近甚至超过 SoC 内部的传输效率。对于 Chiplet 的封装,也需要进行额外的 EDA 设 计,这些都对 EDA 工具提出了更高的要求。 2) 系统性方案带来的更严苛的可靠性挑战 Chiplet 方案作为一个整体的系统性方案,对热效应、电磁挑战、电容耦 合、电感耦合、信号完整性等方面都提出了全新的要求,需要进行针对 性的仿真建模,这是原有主要针对SoC芯片的EDA工具相对薄弱的点。 当第三方 Chiplet 开始被采用时,对于完整系统的可靠性要求将会更高。 第一种挑战可能可以采用 Cadence 等工具组合设计,但针对于第二种可 靠性调整,则需要进行针对性优化升级。 考虑到无论是 EDA 工具链还是之前的协议标准抑或是制造封装技术都 处于发展初期,为了实现有效的正反馈优化,将终端的测试纠错信息及时反馈到上游的 EDA、设计端并进行改进,构建一个完整的、可持续 的生态系统是极其重要的。
三、核心封装技术的选择
Chiplet 方案对应的封装技术包括 2D 的 MCM、2.1D 的 RDL 方案、2.5D 的 CoWoS 和 3D 的 HBM 等多种技术,需要根据功耗、性能、成本等多 方面进行综合考虑。(基于 PAA的芯片评价体系+实现系统效率最大化) 1)2D 的 MCM/WLCSP 技术属于典型的封装技术,将多个不同的芯片 在基板上进行集成,属于成本低复杂度低,但能有效增加管脚数量,提 高芯片集成密度的方案,在 AMD、国内诸如超摩科技等多种产品中使 用,是当前较为主流的方案。 2)InFO 技术属于 2.1D 方案,介于 MCM 和 2.5D 的 CoWoS 之间,利用 RDL 层进行集成,线间距接近 2 微米,引脚数量约 2500 个,多用于手 机和 IoT 中,苹果最新的 M1 等芯片就是采用该方案。 3)2.5D 和 3D 技术可以在前两者的基础上,利用硅转接板等就技术极强 地增大管脚数量和集成密度,例如 2.5D 的方案相较于 InFO 方案,线间 距减小到 0.4 微米,引脚数量增加到 4000 个,是 InFO 方案的 1.6 倍, 但由于成本过高,多用于云计算、HPC、数据中心中。
Chiplet 方案中多芯片集成的封装方案存在散热的功耗问题、硅转接板 等封装材料太贵的成本问题、复杂度过高的可靠性问题,并非适用于所 有工艺节点,也并非适用于所有下游应用,更多时候作为先进工艺制程 遇到门槛时的一种实现摩尔定律的延伸方案。关于成本最优化的探讨可 参考第二章 2.2 的探讨。
四、产品测试的复杂性
Chiplet 方案由于互连封装方案的不同,其测试大多为定制化方案,且 包含更多的测试流程。除了常规的单片集成 SoC 芯片所需的 CP 测试(芯 片针测)、FT 测试(终测),还要包括介质层测试、MT(中段测试)、 SLT(系统级测试等)。 测试流程中,KGSD(已知良好堆叠芯片)测试需要包含更多的可靠性 测试,是主要的难点之一。以 DRAM 和 HBM 为例进行对比: 1) 在晶圆级测试环节,DRAM 晶圆的测试基本相同,HBM 额外增加 针对逻辑晶圆的逻辑测试,包括测试 IP、PHY 电路中缺陷等。但是 考虑到单颗小芯片的缺陷就会导致堆叠的 KGSD 芯片的性能失败, 因此对单颗小芯片的测试性能要求会更高。 2) 在 KGSD 测试环节,传统的 DRAM 封装级产品测试设备和解决方法 将无法有效试用,其测试的挑战包括动态向量老化应力测试、大量 内部 TSV 结构的可靠性测试、高速性能测试、2.5D SIP 测试等。
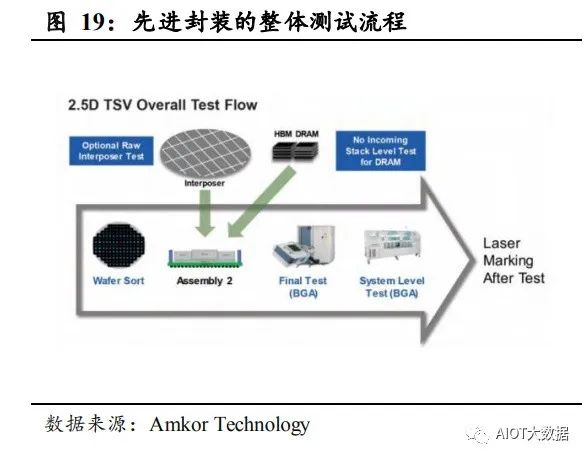
2. Chiplet 封装:高密度集成封装是实现 Chiplet 的核 心
Chipet 封装方案可分为 2D、2.1D、2.5D 和 3D 封装技术。2D 方案性价 比高,但无法承受大面积集成,上升空间有限;2.1D 方案集成度进一步提高,但技术难度相对较大,应用范围偏小;2.5D 方案成本高,但硅转 接板技术相对成熟,可集成密度较高,虽然价格昂贵,但在服务器等应 用领域具有较大潜在价值,另外结合 3D 封装后,整体成长空间最大, 是延续摩尔定律的潜在核心方案。
2.1. 从 2D 到 3D,封装形式多样
先进封装技术不同于传统封装技术,其主要包含 RDL、Bump、Wafer 和 TSV 四个要素。传统封装主要包括 DIP、QFP 等引脚封装和引线框架 封装,而诸如 FC-BGA、FO WLP 和 FI WLP 等包含 RDL、Bump、Wafer 和 TSV 四个要素之一,均属于先进封装。 Chiplet 封装方案是小芯粒的异构异质高密度集成方案,对应不同的封 装类别,以先进封装技术为基础,可主要分为 2D、2.1D、2.5D 和 3D 四大类。考虑到市场上各家公司对于封装方案的定义并不明确,本文粗 浅根据在基板基础上是否有 RDL 层和硅桥、是否有无源硅转接板、是 否有有源硅板之间的堆叠,进行分类,依次划分为 2D、2.1D、2.5D 和 3D 四大类,其中 2D 方案由于不使用任何额外高密度 RDL/硅等转接板, 性价比高,在 Chiplet 的发展初期,产品中应用广泛。
一、2D 方案的客户和产品应用
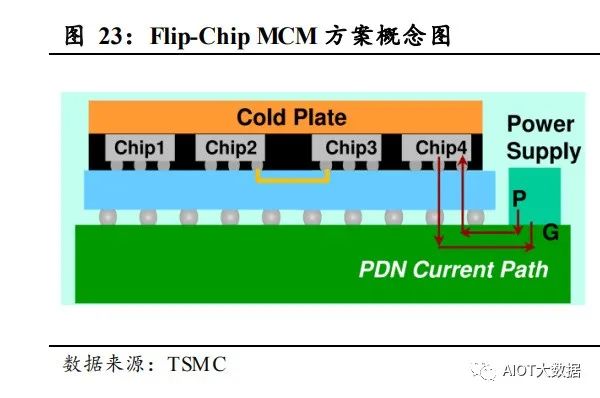
2D 方案主要为简单的 MCM 方案,无需额外的转接板,成本低,性价 比高,应用较为广泛,但无法支撑多芯片大面积应用,在性能提升上空 间有限。2D 方案整体厚度较薄,主要分为 FC-MCM 类的直接通过封装 基板走线实现互连和普通 InFO 类的无需基板直接通过 RDL 层进行互连。 FC-MCM 类受限于 ABF 基板良率低,无法支撑多芯片大面积的应用。 普通 InFO 类由于没有基板,仅凭 PI 材料的 RDL 层,硬度不够,同样 无法支撑大面积的多芯片集成。 2D 方案受益于性价比,国内外客户多家产品有量产,在四种类别中应 用最广,发展最快。AMD 的最初 Zen 架构的系列产品采用的就是 MCM 方案,如锐龙、霄龙等。另外,国内包括超摩科技(高性能 CPU)、龙 芯中科等都有相关方案研究。
二、2.1D 方案的产品和客户应用
2.1D 方案介于 2D 的 MCM 和 2.5D 硅转接板之间,成本相对适中,可 集成度较高,可适用于大规模多芯片集成。2.1D 方案主要在基板上采用 高密度的 RDL 层或者在 RDL 层/基板中内嵌硅桥来增大集成密度。高密 度的 RDL 层方案包括特斯拉的 InFO-SoW(六层 RDL)、TSMC 的 InFO-R/InFO-oS/InFO-LSI 系列、长电的 XDFOI(五层 RDL)等。内嵌 硅桥的方案以 Intel 的 EMIB、日月光的 FOCoS-B 为主。 2.1D 方案的主要缺点在于技术难度相对较大,目前只在少数客户中使用。 例如高密度 RDL 层的 InFO-R 中,本身 InFO 工艺就较为复杂,还需要 在 PI 树脂中进行多层 RDL 高密度布线,难度更加巨大。目前主要在苹 果的 M1 MAX 芯片中使用该方案较多。例如内嵌硅桥的 EMIB和 FOCoS 方案中,需要额外考虑硅桥和 RDL 层/基板的兼容性,目前主要在 Intel 的产品中使用较多。
三、2.5D 方案的产品和客户应用
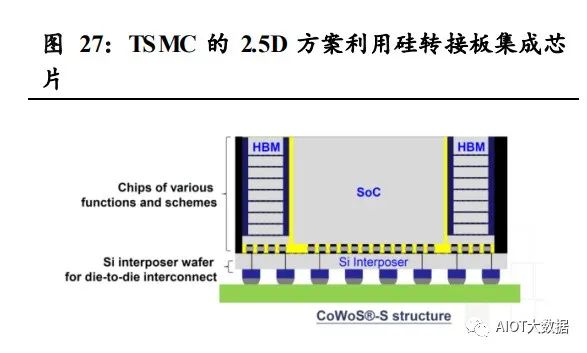
2.5D 方案利用无源硅转接板方案,可实现更高密度、大面积多芯片的集 成方案,传输速度高,性能优越,是潜在延续摩尔定律成长空间的主要 方案。无源硅转接板利用内部 RDL 和 TSV 可实现内部的高密度互连, 加上硅技术较为成熟,成为替代先进工艺延续摩尔定律的中坚力量。另 外 3D 方案的拓展也主要建立在 2.5D 方案的基础上。主要方案包括台积 电的 CoWoS 系列方案,三星的 I-Cube,通富的 VISionS 等。 2.5D 方案整体性能更为优越,但由于增加硅转接板,成本较高,主要用 在服务器、数据中心等高端应用中,发展前景巨大。鲲鹏 920、AMD 的 Zen2 以上架构产品诸如 Rome、Milan 等服务器芯片都应用 CoWoS 方案。 以 AMD 的 Zen4 架构的 EPYC 7004 服务器芯片为例,其内部可封装的 CCD 数量增加到 12 个,内核增加到 96 个,可支持 12 通道的 DDR5 内 存,提供 128 条 PCIE 5.0 通道,性能十分突出。
四、3D 方案的产品和客户应用
3D 方案主要在 2.5D 基础上,利用混合键合等方式实现芯片间的垂直互 连,集成密度最大,性能提升也十分可观,但成本非常高。3D 方案为 有源硅之间的互连,即芯片之间的互连,为满足足够的信息带宽,使用 的互连线的数量和密度都远大于前三种,而且混合键合的难度也远大于 bump 键合,整体成本非常高。主要方案包括 Intel 的 Co-EMIB/Foveros、 三星的 X-Cube、TSMC 的 SoIC、HBM、3D V-Cache 等技术。 3D 方案由于成本非常高,相关应用较少,主要在对性能要求非常苛刻 的高端应用领域。相关的 HBM、3D V-Cache 等产品主要用在对计算要求较高的 AI 芯片中或者对延迟要求非常高的游戏 CPU 芯片中。HBM 主 要将各种 DRAM 芯片进行堆叠,从而扩大内存容量,在高性能计算领 域需求量较大。3D V-Cache 主要将 L3 cache 堆叠在 CPU 上,以减小延 迟,这在游戏领域需求量较大。
2.2. 高性能大芯片是实现成本性能最优化的应用
就成本而言,先进封装只对先进工艺的大芯片即高性能大芯片存在明显 成本效益。MCM 等最基本的 2D 封装不仅满足架构需求,提高性能, 成本还低,可能会被最先大范围使用。2.5D 等封装方案成本高,但结合 3D 封装后,整体可提升的成长空间最大,是潜在核心方案。 多芯片集成的 Chiplet 方案是在以先进工艺为基础的 SoC 方案遇到摩尔 定律发展的门槛时,所延伸的提升性能、减小成本、优化性价比的方案。 SoC 方案为将 A、B、C 等各种 IP 内核进行组合搭配,无需 D2D(Die to Die)的 IP;而 Chiplet 方案为将 A、B、C 等各种内核分别与 D2D IP 进 行组合,依次封装,并在基板或者硅转接板上进行互连组合,并利用高 密度集成封装方案进行封装。 Chiplet 方案的成本随着集成密度的提高而不断提高,需要和小芯片的 成本进行综合考量,实现最优综合性能。例如 2D 方案的 MCM 封装集 成密度最低,bump 密度为 90 微米,成本也最低。而 RDL Interposer 和Si Interposer 的集成密度逐步提高,bump 密度分别达到 45/30 微米,成 本也相对提升,其中硅转接板的成本最高。3D 封装的 bump 密度达到 9 微米,成本是所有集成封装方案中最高的。
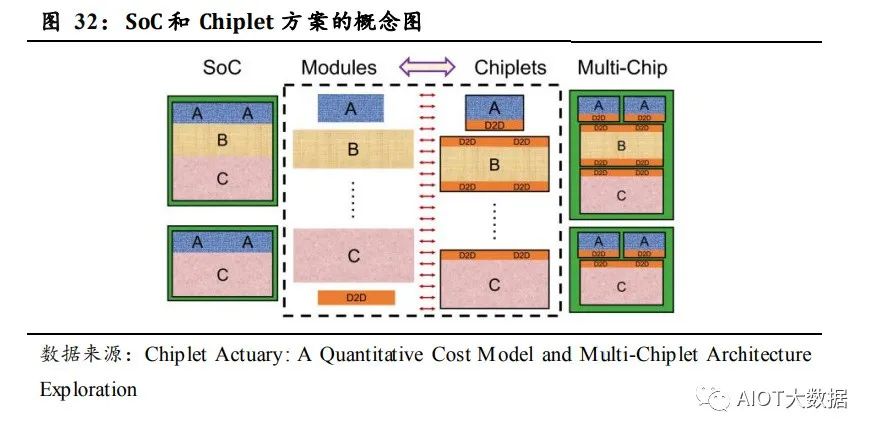
就成本角度进行考量,一块单片 SoC 芯片或者 Chiplet 芯片,主要成本 可粗略划分为 RE(recurring engineering)成本和 NRE(non-recurring engineering)成本。NRE 成本为电路设计中的一次性成本,包括软件、 IP 授权、模块/芯片/封装设计、验证、掩模版等费用,针对于单颗芯片 是摊销后的成本。RE 成本为大规模量产中的制造成本,包括晶圆、封 装、测试等。 根据《Chiplet Actuary: A Quantitative Cost Model and Multi-Chiplet Architecture Exploration》中的成本模型和验证数据:
一、在 RE 成本方面,主要包含五部分:1)原芯片成本;2)芯片缺陷 成本;3)原封装成本;4)封装缺陷成本;5)因为封装缺陷导致的 KGDs 被浪费的成本。对于芯片间 D2D 带来的成本,等同于一块特定的 IP 核。 对于不同的工艺和架构,它在芯片面积中占一定比例。其他诸如 bumping、 wafer sort、测试等成本由于重要性较低,包含如前述五项中,不进行额 外考虑。 就不同的集成的小芯片的数量、不同的芯片面积和不同的工艺节点,针 对不同的封装形式进行考量,得出结论:
① 工艺节点越小,芯片面积越大,多芯片集成的 Chiplet 方案带来的 好处越大。SoC 主要的成本增加来源于面积增大后导致的芯片缺陷成本。 以 800mm2 的 5nm 工艺 SoC 芯片为例,其芯片缺陷成本占总成本超过 50%,而 100mm2 的芯片中的芯片缺陷成本占比不足 10%。当对此芯片 进行芯粒化+高密度封装,芯片缺陷成本减小一半,哪怕叠加 2.5D 封装 带来的封装成本,其总成本仍小于 SoC 方案。 就 2 Chiplets 组成的 14nm 芯片而言,只有当面积大于 700mm2,SoC 的 成本才勉强大于 MCM。而对于 InFO 和 2.5D,哪怕面积大于 900mm2, SoC 方案始终占有成本优势。 就 2 Chiplets 组成的 7nm 芯片而言,当面积大于 500 mm2,SoC 的成本 大于 MCM;当面积大于 800 mm2,SoC 的成本才大于 InFO; 就 2 Chiplets 组成的 5nm 芯片而言,当面积大于 300 mm2,SoC 的成本 大于 MCM;当面积大于 500 mm2,SoC 的成本大于 InFO;当面积大于 700 mm2,SoC 的成本才大于 2.5D 方案;总之,对于任何工艺节点,芯片面积提升带来的好处,先进工艺节点会 早于成熟工艺。成熟工艺节点不适合高密度 Chiplet 的原因在于 14nm 工艺较为成熟,良率较高,面积增大带来的芯片缺陷成本的增加小于 D2D以及更高级封装带来的成本增加。小面积芯片不适合高密度 Chiplet 的原因在于芯片缺陷成本太小,封装类的成本占据主要。 ② 小芯粒数量的提升,对成本的优化具有一定效果。就 5nm,800 mm2 的 MCM 芯片而言,从 3 个小芯粒增加到 5 个小芯粒,芯片的缺陷成本 的减小约为 10%。
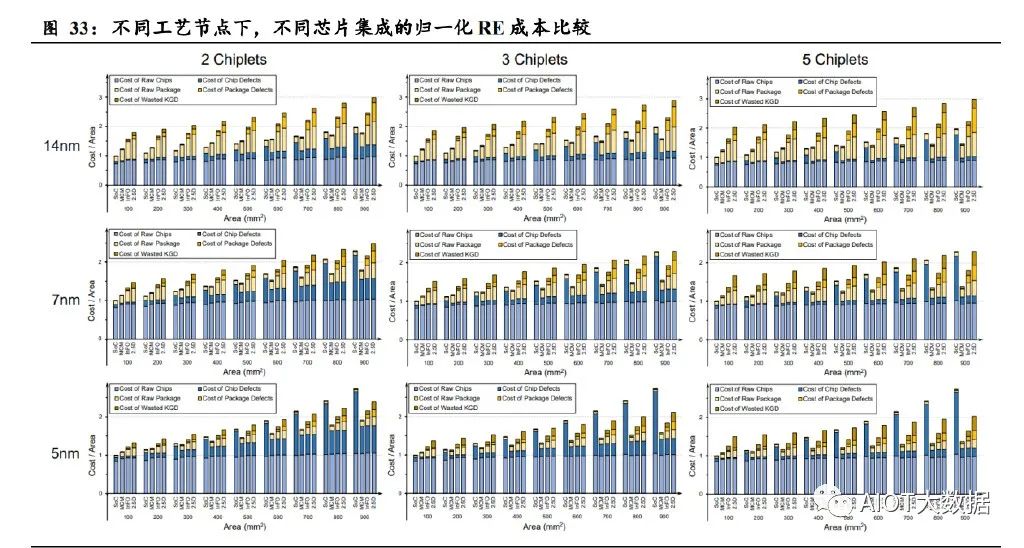
二、在 NRE 成本方面,
多芯片 Chiplet 方案会造成非常高的额外 NRE 成本,只有当量产数量足 够高,才有足够性价比。以 14nm 的 800mm2 的芯片为例,500k 的销量, 对于成本最高的 2.5D 封装,D2D 的互连和封装的成本占比分别小于 2% 和 9%,而 Chiplet 1/2 模块和芯片的成本在 MCM 中占 36%,在 2.5D 中 占 31%,占比非常高,不如采用单集成 SoC 方案。而当销量从 500k 增 加到 10M 时,Chiplet 方案的成本将大幅缩减。
除了面积、工艺、小芯片的数量以外,Chiplet 在多芯片架构复用和异 构方面存也在着巨大的成本优势。多芯片复用架构主要分为三类:① SCMS(单芯片多系统);②OCME(一中心多拓展);③FSMC(固定插 座多组合)。 ① SCMS:芯片的复用,使 Chiplet 相较于 SoC 而言节省一次性投入成 本。该种方案只需要一个芯片即可,适用于同一产品线不同等级的 产品。AMD 和国内最初的产品架构就是采用该方案。 ② OCME:实现了异构工艺,将不同的成熟工艺产品和先进工艺产品 进行拼接。诸如 AMD 的 ZEN3 架构采用的就是该方案。 ③ FSMC:将复用的可能性最大化,即将可复用的芯片最小化,这样一 次性投入成本摊销的收益就越大。多芯片集成的 Chiplet 方案的成本 优势将会最大化。
3. Chiplet 空间:高算力需求打开成长空间,封测端 是主要受益点
3.1. AI+数字经济催生高算力需求,Chiplet 深度受益
ChatGPT作为生成式 AI 的现象级产品,将催生庞大的产业链算力需求。 ChatGPT 是 OpenAI 开发的聊天机器人,在 2022 年 11 月推出,一经推 出,就成为迄今为止用户量增长最快的消费应用程序,仅用 2 月就积累 1 亿用户数量,即使是海外现象级应用 TikTok 也用了 9 个月的时间。未 来国内外诸如百度等大模型公司、科大讯飞等应用端公司都在积极参与, 带来庞大的算力需求。
数字经济推动数据中心建设快速发展,带动计算需求增长。受益于 5G、 人工智能、大数据、云计算等新兴产业发展,对海量数据处理的需求不 断提升,数据中心成为数字化发展的重要基础设施。截止 2021 年底, 我国在用数据中心机架规模达到 520 万架,近五年 CAGR 超过 30%,其 中大型以上机架规模达 420 万架,占比达 80%。进入数字经济时代,数 据量呈指数级增长,对算力提出了巨大需求。据 Cisco 预计,2021 年计 算能力更强的超级数据中心将达到 628 座,占数据中心总量的 53%。
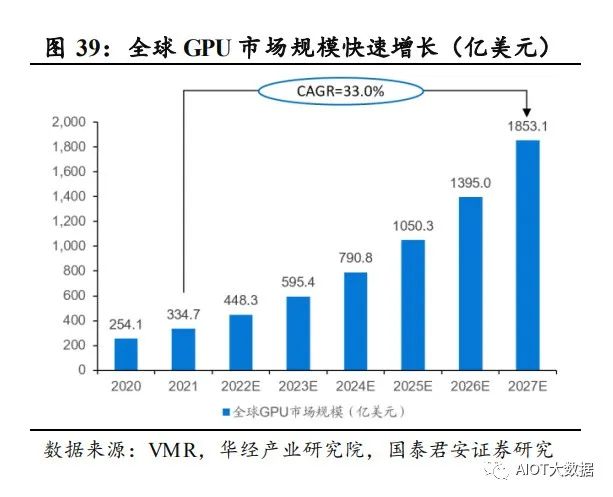
受益于 AI 和数字经济的需求,全球 GPU、MPU、AI 芯片等大算力芯 片需求大幅提升。2027 年全球 GPU 市场规模预计达到 1853.1 亿美元, 21-27 年 CAGR 为 33%。2022 年 MPU 的全球市场规模也已经突破 1000 亿美元。2024 年 AI 的中国市场规模也预计突破 785 亿元,21-24 年 CAGR 为 46%。
3.2. 产业生态发展早期,封测端是主要受益点
Chiplet 生态仍处于发展早期,就产业链而言,价值量的增长点主要集 中在封测端和材料端。目前产业仍处于 Chiplet 生态成长期,设计厂商 主要采用已有的 EDA 和 IP 针对 Chiplets 进行自重用和自迭代,工艺和 互连标准尚未统一。产业链中最大的价值量增长源于新的高密度集成的 封装方案带来的封测端和材料端的应用,未来随着生态和技术的成熟, EDA 等更上游的价值量也会逐步增加。 Chiplet 业务链中,晶圆厂和封测厂都逐步向产业链下游垂直整合,以 扩大自身的业务空间和利润增长点。晶圆厂围绕硅互连技术进行发展, 从带 TSV 的转接板向 RDL 层、微凸点等领域拓展,自上而下,拓展价 值空间。封测厂在争取从原有的基板、C4 凸点向上游 Chiplet 业务链中 的 RDL 层、TSV 转接板、微凸点等方向发展,因为该块业务精细度不 高但有较大业务量。不过,封测厂话语权不如晶圆厂,大多封测厂更多 向下游拓展,将更多的元器件、射频器件、PMIC 等集成到基板中,以 期获得更大的价值量增长。
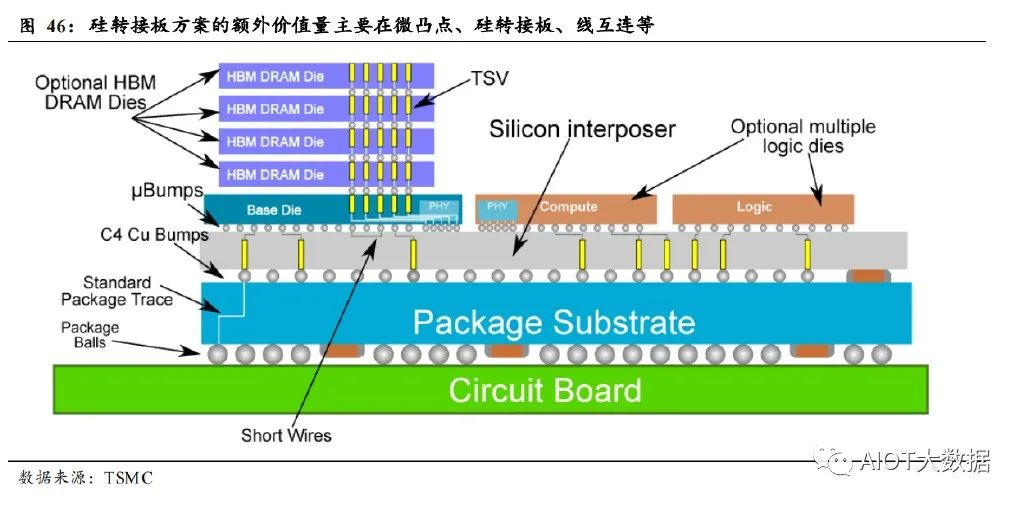
在封装端,对于封装厂而言,价值量额外增长主要集中在微凸点、转接 板、线互连等领域。 ① 在MCM的2D领域,只增加了额外的基板内互连,价值量增长最低。 ② 在 RDL 转接板的 2.1D 领域(RDL 整体较薄,介于 2.5D 和 2D 之间, 又可称为 2.1D),主要为台积电的 InFO 和长电的 XDFOI 等方案。 InFO 方案是 Chipfirst 技术,没有微凸点,由于该类方案主要由 TSMC 主导,下游封测厂话语权较小,价值量仍主要局限于原有封测领域, 如 C4 bump 和基板等。XDFOI 方案是 chiplast 方案,存在微凸点, 该类方案包含多层 RDL 层、微凸点、互连线等,封测厂可做价值量 更大。 ③ 在硅转接板的 2.5D 领域,主要为台积电的 CoWoS 等方案,该方案 价值量较多,包括微凸点、RDL、硅转接板、TSV 等,但同样受限 于 TSMC 等晶圆厂较为强势的话语权,大多硅转接板等价值量都被 晶圆厂拿走。但是台积电等晶圆厂开价过高,终端厂等正尝试分散 供应链,各环节找不同的厂商,以实现利益最大化。 ④ 在 3D 领域,如 HBM 方案,由于精细要求较高,这部分基本全部依 赖晶圆厂,在晶圆制造领域直接堆叠完成。
在测试端,受益于小芯粒带来更多的测试需求以及 KGSD 带来更复杂的 测试要求,相关测试公司和测试设备公司将深度受益。例如伟测科技、 长川科技、和林微纳等都将较为受益。 在材料端,受益于 Chiplet 的突破和高算力的需求,ABF 膜的需求在不 断增长,相关基板产业链公司将深度受益。例如生益科技、深南电路等 都将较为受益。
审核编辑 :李倩
-
半导体
+关注
关注
335文章
27917浏览量
224723 -
先进制程
+关注
关注
0文章
85浏览量
8477 -
chiplet
+关注
关注
6文章
437浏览量
12658
原文标题:半导体Chiplet缓解先进制程焦虑
文章出处:【微信号:AIOT大数据,微信公众号:AIOT大数据】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
SEMI-e 2025:聚焦半导体制造与先进封装领域,探索行业发展新路径
台积电加速美国先进制程落地
三星SF4X先进制程获IP生态关键助力
台积电美国芯片量产!台湾对先进制程放行?
Chiplet技术革命:解锁半导体行业的未来之门

Chiplet在先进封装中的重要性
芯和半导体将出席SiP及先进半导体封测技术论坛
喆塔科技先进制程AI赋能中心&amp;校企联合实验室落户苏州

国产半导体新希望:Chiplet技术助力“弯道超车”!






 工商网监
工商网监
评论