 解析ChatGPT背后的技术演进
解析ChatGPT背后的技术演进
解析ChatGPT背后的技术演进
一、OpenAI正式发布多模态大模型GPT-4,实现多重能力跃升
(一)多模态大模型GPT-4是OpenAI公司GPT系列最新一代模型
美国OpenAI公司成立于2015年12月,是全球顶级的人工智能研究机构之一,创始人 包括Elon Musk、著名投资者Sam Altman、支付服务PayPal创始人Peter Thiel等人。 OpenAI作为人工智能领域的革命者,成立至今开发出多款人工智能产品。2016年, OpenAI推出了用于强化学习研究的工具集OpenAI Gym;同时推出开源平台OpenAI Universe,用于测试和评估智能代理机器人在各类环境中的表现。2019年,OpenAI 发布了GPT-2模型,可根据输入文本自动生成语言,展现出人工智能创造性思维的 能力;2020年更新了GPT-3语言模型,并在其基础上发布了OpenAI Codex模型,该 模型可以自动生成完整有效的程序代码。
2021年1月,OpenAI发布了OpenAI CLIP, 用于进行图像和文本的识别分类;同时推出全新产品DALL-E,该模型可以根据文字 描述自动生成对应的图片,2022年更新的DALL-E2更是全方位改进了生成图片的质 量,获得了广泛好评。 2022年12月,OpenAI推出基于GPT-3.5的新型AI聊天机器人ChatGPT,在发布进 两个月后拥有1亿用户,成为史上用户增长最快的应用;美东时间2023年3月14日, ChatGPT的开发机构OpenAI正式推出多模态大模型GPT-4。
GPT(General Pre-Training)系列模型即通用预训练语言模型,是一种利用 Transformer作为特征抽取器,基于深度学习技术的自然语言处理模型。 GPT系列模型由OpenAI公司开发,经历了长达五年时间的发展: (1)其最早的产品GPT模型于2018年6月发布,该模型可以根据给定的文本序列进 行预测下一个单词或句子,充分证明通过对语言模型进行生成性预训练可以有效减 轻NLP任务中对于监督学习的依赖; (2)2019年2月GPT-2模型发布,该模型取消了原GPT模型中的微调阶段,变为无 监督模型,同时,GPT-2采用更大的训练集尝试zero-shot学习,通过采用多任务模 型的方式使其在面对不同任务时都能拥有更强的理解能力和较高的适配性;
(3)GPT-3模型于2020年6月被发布,它在多项自然语言处理任务上取得了惊人的 表现,并被认为是迄今为止最先进的自然语言处理模型之一。GPT-3训练使用的数 据集为多种高质量数据集的混合,一次保证了训练质量;同时,该模型在下游训练 时用Few-shot取代了GPT-2模型使用的zero-shot,即在执行任务时给予少量样例, 以此提高准确度;除此之外,它在前两个模型的基础上引入了新的技术——“零样 本学习”,即GPT-3即便没有对特定的任务进行训练也可以完成相应的任务,这使 得GPT-3面对陌生语境时具有更好的灵活性和适应性。
(4)2022年11月,OpenAI发布GPT-3.5模型,是由GPT-3微调出来的版本,采用 不同的训练方式,其功能更加强大。基于GPT-3.5模型,并加上人类反馈强化学习 (RLHF)发布ChatGPT应用,ChatGPT的全称为Chat Generative Pre-trained Transformer,是建立在大型语言模型基础上的对话式自然语言处理工具,表现形式 是一种聊天机器人程序,能够学习及理解人类的语言,根据聊天的上下文进行互动, 甚至能够完成翻译、编程、撰写论文、编辑邮件等功能。 (5)2023年3月,OpenAI正式发布大型多模态模型GPT-4(输入图像和文本,输出 文本输出),此前主要支持文本,现模型能支持识别和理解图像。

(二)GPT大模型通过底层技术的叠加,实现组合式的创新
由于OpenAI并没有提供关于GPT-4用于训练的数据、算力成本、训练方法、架构等 细节,故我们本章主要讨论ChatGPT模型的技术路径。 ChatGPT模型从算法分来上来讲属于生成式大规模语言模型,底层技术包括 Transformer架构、有监督微调训练、RLHF强化学习等,ChatGPT通过底层技术 的叠加,实现了组合式的创新。 GPT模型采用了由Google提出的Transformer架构。Transformer架构采用自注意 力机制的序列到序列模型,是目前在自然语言处理任务中最常用的神经网络架构之 一。相比于传统的循环神经网络(RNN)或卷积神经网络(CNN),Transformer 没有显式的时间或空间结构,因此可以高效地进行并行计算,并且Transformer具有 更好的并行化能力和更强的长序列数据处理能力。
ChatGPT模型采用了“预训练+微调”的半监督学习的方式进行训练。第一阶段是 Pre-Training阶段,通过预训练的语言模型(Pretrained Language Model),从大 规模的文本中提取训练数据,并通过深度神经网络进行处理和学习,进而根据上下 文预测生成下一个单词或者短语,从而生成流畅的语言文本;第二阶段是Fine-tuning 阶段,将已经完成预训练的GPT模型应用到特定任务上,并通过少量的有标注的数 据来调整模型的参数,以提高模型在该任务上的表现。
ChatGPT在训练中使用了RLHF人类反馈强化学习模型,是GPT-3模型经过升级并 增加对话功能后的最新版本。2022年3月,OpenAI发布InstructGPT,这一版本是 GPT-3模型的升级版本。相较于之前版本的GPT模型,InstructGPT引入了基于人类 反馈的强化学习技术(Reinforcement Learning with Human Feedback,RLHF), 对模型进行微调,通过奖励机制进一步训练模型,以适应不同的任务场景和语言风 格,给出更符合人类思维的输出结果。
RLHF的训练包括训练大语言模型、训练奖励模型及RLHF微调三个步骤。首先,需 要使用预训练目标训练一个语言模型,同时也可以使用额外文本进行微调。其次, 基于语言模型训练出奖励模型,对模型生成的文本进行质量标注,由人工标注者按 偏好将文本从最佳到最差进行排名,借此使得奖励模型习得人类对于模型生成文本 序列的偏好。最后利用奖励模型输出的结果,通过强化学习模型微调优化,最终得 到一个更符合人类偏好语言模型。
(三)GPT-4相较于ChatGPT实现多重能力跃迁
ChatGPT于2022年11月推出之后,仅用两个月时间月活跃用户数便超过1亿,在短 时间内积累了庞大的用户基数,也是历史上增长最快的消费应用。多模态大模型GPT-4是OpenAI的里程碑之作,是目前最强的文本生成模型。 ChatGPT推出后的三个多月时间里OpenAI就正式推出GPT-4,再次拓宽了大模型的 能力边界。GPT-4是一个多模态大模型(接受图像和文本输入,生成文本),相比 上一代,GPT-4可以更准确地解决难题,具有更广泛的常识和解决问题的能力:更 具创造性和协作性;能够处理超过25000个单词的文本,允许长文内容创建、扩展 对话以及文档搜索和分析等用例。
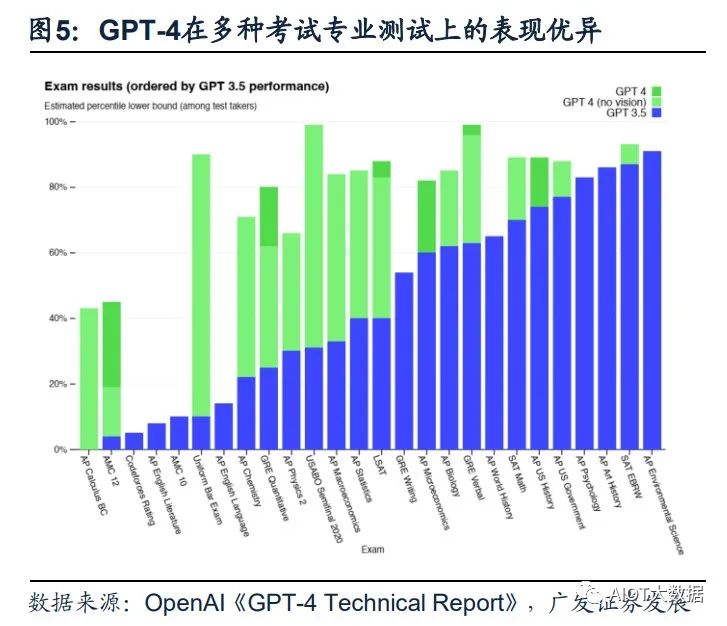
(1)GPT-4具备更高的准确性及更强的专业性。GPT-4在更复杂、细微的任务处理 上回答更可靠、更有创意,在多类考试测验中以及与其他LLM的benchmark比较中 GPT-4明显表现优异。GPT-4在模拟律师考试GPT-4取得了前10%的好成绩,相比 之下GPT-3.5是后10%;生物学奥赛前1%;美国高考SAT中GPT-4在阅读写作中拿 下710分高分、数学700分(满分800)。
(2)GPT能够处理图像内容,能够识别较为复杂的图片信息并进行解读。GPT-4 突破了纯文字的模态,增加了图像模态的输入,支持用户上传图像,并且具备强大 的图像能力—能够描述内容、解释分析图表、指出图片中的不合理指出或解释梗图。 在OpenAI发布的产品视频中,开发者给GPT-4输入了一张“用VGA电脑接口给 iPhone充电”的图片,GPT-4不仅可以可描述图片,还指出了图片的荒谬之处。
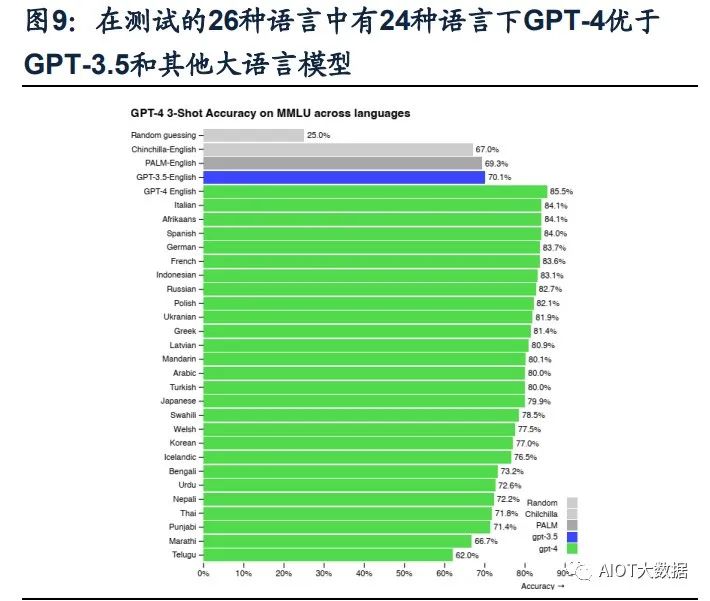
(3)GPT-4可以处理超过25000字的文本。在文本处理上,GPT-4支持输入的文字 上限提升至25000字,允许长文内容创建、扩展对话以及文档搜索和分析等用例。 且GPT-4的多语言处理能力更优,在GPT-4的测评展示中,GPT-4可以解决法语的 物理问题,且在测试的英语、拉脱维亚语、威尔士语和斯瓦希里语等26种语言中, 有24种语言下,GPT-4优于GPT-3.5和其他大语言模型(Chinchilla、PaLM)的英 语语言性能。(4)具备自我训练与预测能力,同时改善幻觉、安全等局限性。GPT-4的一大更新 重点是建立了一个可预测拓展的深度学习栈,使其具备了自我训练及预测能力。同 时,GPT-4在相对于以前的模型已经显著减轻了幻觉问题。在OpenAI的内部对抗性 真实性评估中,GPT-4的得分比最新的GPT-3.5模型高 40%;在安全能力的升级上, GPT-4明显超出ChatGPT和GPT3.5。
(四)商业模式愈发清晰,微软Copilot引发跨时代的生产力变革
OpenAI已正式宣布为第三方开开发者开放ChatGPT API,价格降低加速场景应用 爆发。起初ChatGPT免费向用户开放,以获得用户反馈;今年2月1日,Open AI推 出新的ChatGPT Plus订阅服务,收费方式为每月20美元,订阅者能够因此而获得更 快、更稳定的响应并优先体验新功能。3月2日,OpenAI官方宣布正式开放ChatGPT API(应用程序接口),允许第三方开发者通过API将ChatGPT集成至他们的应用程 序和服务中,价格为1ktokens/$0.002,即每输出100万个单词需要2.7美元,比已有 的GPT-3.5模型价格降低90%。模型价格的降低将推动ChatGPT被集成到更多场景 或应用中,丰富ChatGPT的应用生态,加速多场景应用的爆发。
GPT-4发布后OpenAI把ChatGPT直接升级为GPT-4最新版本,同时开放了GPT-4 的API。ChatGPT Plus付费订阅用户可以获得具有使用上限的GPT-4访问权限(每4 小时100条消息),可以向GPT-4模型发出纯文本请求。用户可以申请使用GPT-4 的API,OpenAI会邀请部分开发者体验,并逐渐扩大邀请范围。该API的定价为每输 入1000个字符(约合750个单词),价格为0.03美元;GPT-4每生成1000个字符价格为 0.06美元。 Office引入GPT-4带来的结果是生产力、创造力的全面跃升。微软今天宣布,其与 OpenAI共同开发的聊天机器人技术Bing Chat正在GPT-4上运行。
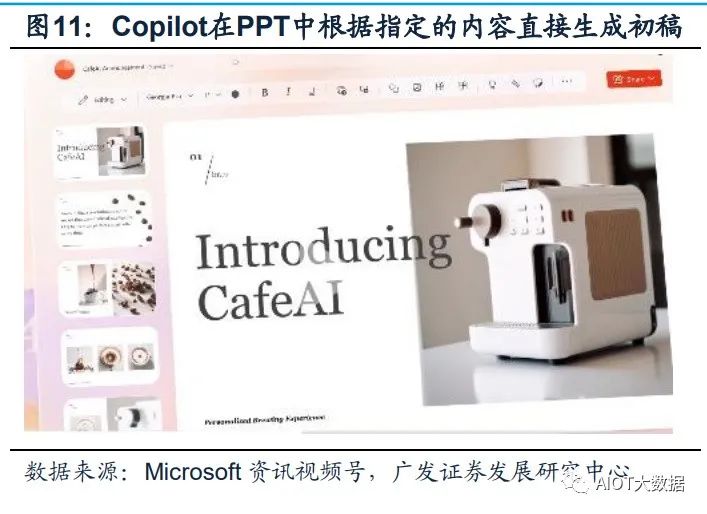
Copilot OpenAI发布升级后的GPT-4后,微软重磅发布了GPT-4平台支持的新AI功能, Microsoft 365 Copilot,并将其嵌入Word、PowerPoint、Excel、Teams等Office办 公软件中。Copilot可以在一篇速记的基础上快速生成新闻草稿、并完成草稿润色; 在Excel中完成各种求和、求平均数,做表格、归纳数据、甚至是完成总结提取;在 PPT上可以直接将文稿内容一键生成;在Outlook邮件中自动生成内容、并自由调整 写作风格、插入图表;在Teams中总结视频会议的要点/每个发言人谁说了核心内容, 跟进会议流程和内容,自动生成会议纪要、要点和任务模板。基于GPT-4的Copilot 可以看作是一个办公AI助理,充分发挥出了AI对于办公场景的赋能作用,有望从根 本上改变工作模式并开启新一轮生产力增长浪潮。
二、GPT-4带动多模态x多场景落地,AIGC蓝海市场打开
(一)历经三阶段发展,AIGC技术升级步入深化阶段
AIGC全程为AI-Generated Content,人工智能生成内容,是继专业生成内容(PGC, Professional Generate Content)和用户生成内容(UGC,User Generate Content) 之后,利用AI自动生成内容的新型生产方式。传统AI大多属于分析式AI,对已有数 据进行分析并应用于相应领域。以AIGC为典型的生成式AI不在局限于分析固有数据, 而是基于训练数据和算法模型自主生成创造新的文本、3D、视频等各种形式的内容。
历经三阶段迭代,AIGC现已进入快速发展阶段: (1)早期萌芽阶段(1950s-1990s),受限于科技水平及高昂的系统成本,AIGC 仅限于小范围实验。 (2)沉淀积累阶段(1990s-2010s),AIGC开始从实验性向实用性逐渐转变。但 由于其受限于算法瓶颈,完成创作能力有限,应用领域仍具有局限性; (3)快速发展阶段(2010s-至今),GAN(Generative Adversarial Network,生成 式对抗网络)等深度学习算法的提出和不断迭代推动了AIGC技术的快速发展,生成 内容更加多元化。
AIGC可分为智能数字内容孪生、智能数字内容编辑及智能数字内容创作三大层次。 生成式AI是指利用现有文本、音频文件或图像创建新内容的人工智能技术,其起源 于分析式AI,在分析式AI总结归纳数据知识的基础上学习数据产生模式,创造出新 的样本内容。在分析式AI的技术基础上,GAN、Transformer网络等多款生成式AI 技术催生出许多AIGC产品,如DALL-E、OpenAI系列等,它们在音频、文本、视觉 上有众多技术应用,并在创作内容的方式上变革演化出三大前沿能力。AIGC根据面 向对象、实现功能的不同可以分为智能数字内容孪生、智能数字内容编辑及智能数 字内容创作三大层次。
(二)生成算法+预训练模型+多模态推动AIGC的爆发
AIGC的爆发离不开其背后的深度学习模型的技术加持,生成算法、预训练和多模态 技术的不断发展帮助了AIGC模型具备通用性强、参数海量、多模态和生成内容高质 量的特质,让AIGC实现从技术提升到技术突破的转变。 (1)生成算法模型不断迭代创新,为AIGC的发展奠定基础。早期人工智能算法学 习能力不强,AIGC技术主要依赖于事先指定的统计模型或任务来完成简单的内容生 成和输出,对客观世界和人类语言文字的感知能力较弱,生成内容刻板且具有局限 性。GAN(Generative Adversarial Network,生成式对抗网络)的提出让AIGC发展 进入新阶段,GAN是早期的生成模型,利用博弈框架产生输出,被广泛应用于生成 图像、视频语音等领域。随后Transformer、扩散模型、深度学习算法模型相继涌现。
Transformer被广泛应用于NLP、CV等领域,GPT-3、LaMDA等预训练模型大多是 基于transformer架构构建的。ChatGPT是基于Transformer架构上的语言模型, Transformer负责调度架构和运算逻辑,进而实现最终计算。Tansformer是谷歌于 2017年《Attention is All You Need》提出的一种深度学习模型架构,其完全基于注 意力机制,可以按照输入数据各部分重要性来分配不同的权重,无需重复和卷积。 相较于循环神经网络(RNN)流水线式的序列计算,Transformer可以一次处理所有 的输入,摆脱了人工标注数据集的缺陷,实现了大规模的并行计算,模型所需的训 练时间明显减少,大规模的AI模型质量更优。
Transformer的核心构成是编码模块和解码模块。GPT使用的是解码模块,通过模 块间彼此大量堆叠的方式形成了GPT模型的底层架构,模块分为前馈神经网络层、 编解码自注意力机制层(Self-Attention)、自注意力机制掩码层。自注意力机制层 负责计算数据在全部内容的权重(即Attention),掩码层帮助模型屏蔽计算位置右 侧未出现的数据,最后把输出的向量结果输入前馈神经网络,完成模型参数计算。
(2)预训练模型引发AIGC技术能力的质变。AI预训练模型是基于大规模宽泛的数 据进行训练后拥有适应广泛下游任务能力的模型,预训练属于迁移学习的领域,其 主旨是使用标注数据前,充分利用大量无标注数据进行训练,模型从中全面学习到 与标注无关的潜在知识,进而使模型灵活变通的完成下游任务。视觉大模型提升 AIGC感知能力,语言大模型增强AIGC认知能力。
NLP模型是一种使用自然语言处理(Natural Language Processing,NLP)技术来解决自然语言相关问题的机器学习模型。在NLP领域,AI大模型可适用于人机语言交互,并进行自然语言处理从实现相应的文本分类、文本生成、语音识别、序列标注、机器翻译等功能。NLP的研究经过了以规则为基础的研究方法和以统计为基础的研究方法的发展,目前以基于Transformer的预训练模型已成为当前NLP领域的研究热点,BERT、GPT等模型均采用这一方法。CV模型指计算机视觉模型,是一种基于图像或视频数据的人工智能模型。常见的CV 模型有采用深度学习的卷积神经网络(CNN)和生成对抗网络(GAN)。
近年来以 视觉Transformer(ViT)为典型的新型神经网络,通过人类先验知识引入网络设计, 使得模型的收敛速度、泛化能力、扩展性及并行性得到飞速提升,通过无监督预训 练和微调学习,在多个计算机视觉任务,如图像分类、目标检测、物体识别、图像 生成等取得显著的进步。
(3)多模态技术拓宽了AIGC技术的应用广度。多模态技术将不同模态(图像、声 音、语言等)融合在预训练模型中,使得预训练模型从单一的NLP、CV发展成音视 频、语言文字、文本图像等多模态、跨模态模型。多模态大模型通过寻找模态数据 之间的关联点,将不同模态的原始数据投射在相似的空间中,让模态之间的信号相 互理解,进而实现模态数据之间的转化和生成。这一技术对AIGC的原创生成能力的 发展起到了重要的支持作用,2021年OpenAI推出AI绘画产品DALL.E可通过输入文 字理解生成符合语义且独一无二的绘画作品,其背后离不开多模态技术的支持。
(三)多模态x多场景落地,AIGC爆发商业潜力
ChatGPT的广泛应用意味着AIGC规模化、商业化的开始。ChatGPT是文字语言模 态AIGC的具体应用,在技术、应用领域和商业化方面和传统AI产品均有所不同。 ChatGPT已经具备了一定的对现实世界内容进行语义理解和属性操控的能力,并可 以对其回以相应的反馈。ChatGPT是AIGC重要的产品化应用,意味着AIGC规模化、 商业化的开始。创新工场董事长兼CEO李开复博士在3月14日表示,ChatGPT快速 普及将进一步引爆AI 2.0商业化。AI 2.0 是绝对不能错过的一次革命。
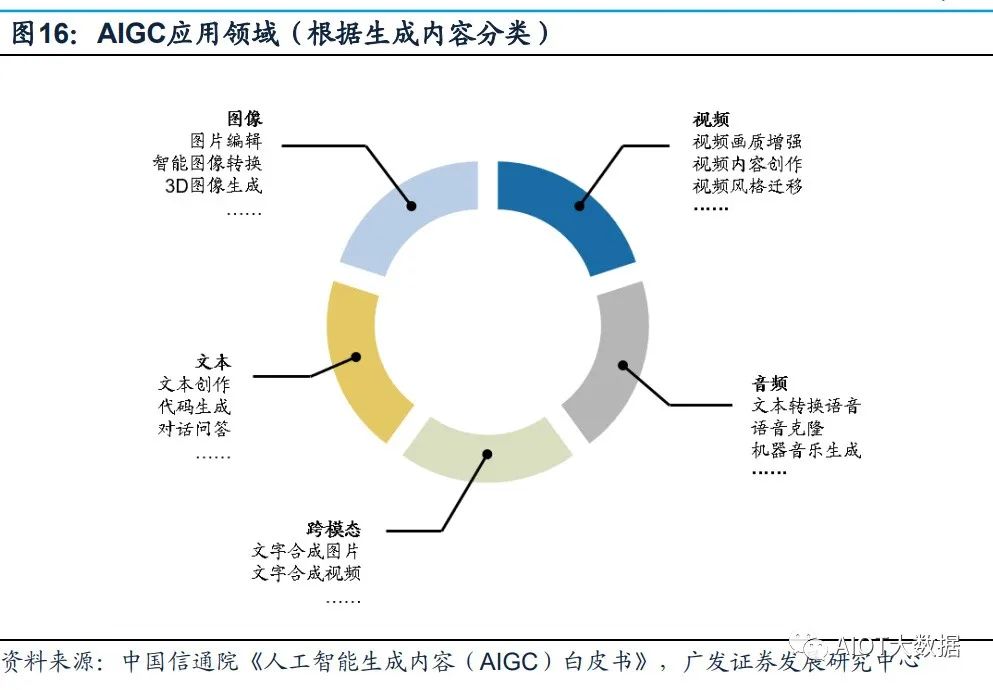
多家公司正加紧研发ChatGPT类似产品,引爆新一轮科技企业AI军备竞赛。在GPT4 推出之后,Google开放自家的大语言模型API「PaLM API」,此外还发布了一款帮 助开发者快速构建AI程序的工具 MakerSuite。2月底,META公布一款全新的AI大型 语言模型LLaMA,宣称可帮助研究人员降低生成式AI工具可能带来的“偏见、有毒 评论、产生错误信息的可能性”等问题。 AIGC的应用领域分为视频、音频、文本、图像、跨模态生成五个部分。
AIGC以其 真实性、多样性、可控性、组合性的特质,为各行业、各领域提供了更加丰富多元、 动态且可交互的内容。根据AIGC生成内容的模态不同,可将AIGC的应用领域分为 视频、音频、文本、图像、跨模态生成五个部分。其中,在图像、文本、音频等领 域,AIGC已经得到了较大优化,生成内容质量得到明显提升;而在视频与跨模态内 容生成方面,AIGC拥有巨大发展潜力。
三、高算力需求带动基础设施迭代加速
(一)AI大模型驱动高算力需求
数据、算力及模型是人工智能发展的三要素。以GPT系列为例: (1)数据端:自OpenAI于2018年发布GPT-1,到2020年的GPT-3,GPT模型参数 数量和训练数据量实现指数型增长。参数数量从GPT-1的1.17亿增长到GPT-3的 1750亿,训练数据量从5GB增长到的45TB; (2)模型端:ChatGPT在以往模型的基础上,在语料库、计算能力、预训练、自我 学习能力等方面有了明显提升,同时Transformer架构突破了人工标注数据集的不足, 实现与人类更顺畅的交流; (3)算力端:根据OpenAl发布的《Language Models are Few-Shot Learners》, 训练13亿参数的GPT-3 XL模型训练一次消耗的算力约为27.5 PFlop/s-dav,训练 1750亿参数的完整GPT-3模型则会消耗算力3640 PFlop/s-dav(以一万亿次每秒速 度计算,需要3640天完成)。
在人工智能发展的三要素中,数据与算法都离不开算力的支撑。随着AI算法突飞猛 进的发展,越来越多的模型训练需要巨量算力支撑才能快速有效实施,同时数据量 的不断增加也要求算力配套进化。如此看来,算力成为AI突破的关键因素。 AI大模型的算力需求主要来自于预训练、日常运营和模型微调。 (1)预训练:在完成完整训练之前,搭建一个网络模型完成特定任务,在训练网络 过程中不断调整参数,直至网络损失和运行性能达到预期目标,此时可以将训练模 型的参数保存,用于之后执行类似任务。根据中国信通院数据,ChatGPT基于GPT3.5 系列模型,模型参数规模据推测达十亿级别,参照参数规模相近的GPT-3 XL模型, 则ChatGPT完整一次预训练消耗算力约为27.5 PFlop/s-dav。
(2)日常运营:满足用户日常使用数据处理需求。根据Similarweb的数据,23年1月份ChatGPT月活约6.16亿,跳出率13.28%每次访问页数5.85页,假设每页平均200 token。同时假设:模型的FLlops利用率为21.3%与训练期间的GPT-3保持一致;完整参数模型较GPT-3上升至2500亿;以FLOPs为指标,SOTA大型语言在在推理过程中每个token的计算成本约为2N。根据以上数据及假设,每月日常运营消耗算力约为6.16亿*2*(1-13.28%)*5.85*200*2500亿/21.3%=14672PFlop/s-day。(3)模型微调:执行类似任务时,使用先前保存的模型参数作为初始化参数,在训练过程中依据结果不断进行微调,使之适应新的任务。
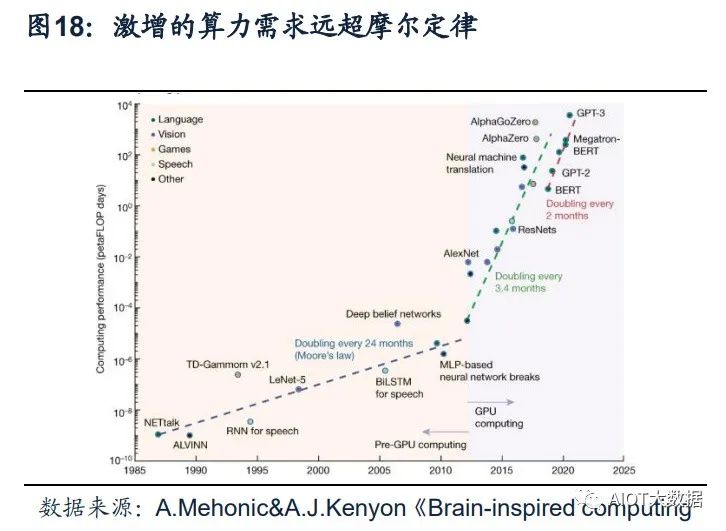
ChatGPT引发新一轮AI算力需求爆发。根据OpenAI发布的《AI and Compute》分 析报告中指出,自2012年以来,AI训练应用的算力需求每3.4个月就回会翻倍,从 2012年至今,AI算力增长超过了30万倍。据OpenAI报告,ChatGPT的总算力消耗 约为3640PF-days(即假如每秒计算一千万亿次,需要计算3640天),需要7-8个算 力500P的数据中心才能支撑运行。上海新兴信息通信技术应用研究院首席专家贺仁 龙表示,“自2016年阿尔法狗问世,智能算力需求开启爆发态势。如今ChatGPT则 代表新一轮AI算力需求的爆发”。
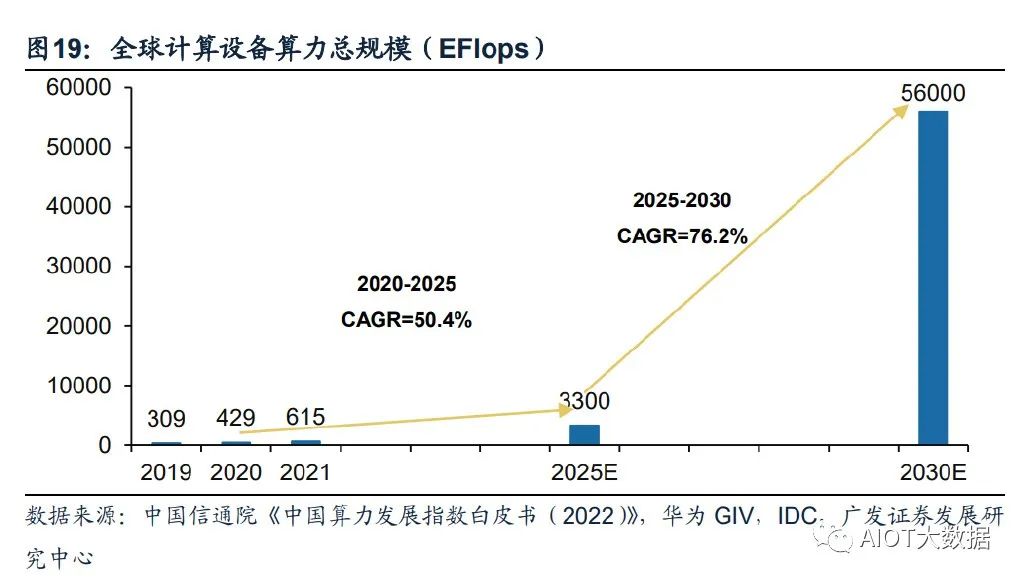
全球算力规模将呈现高速增长态势。根据国家数据资源调查报告数据,2021年全球 数据总产量67ZB,近三年平均增速超过26%,经中国信息通信研究院测算,2021 年全球计算设备算力总规模达到615EFlops,增速达44%。根据中国信通院援引的 IDC数据,2025年全球算力整体规模将达3300EFlops,2020-2025年的年均复合增 长率达到50.4%。结合华为GIV预测,2030年人类将迎来YB数据时代,全球算力规 模达到56ZFlops,2025-2030年复合增速达到76.2%。
(二)云商/运营商推进AI领域算力基础设施投入
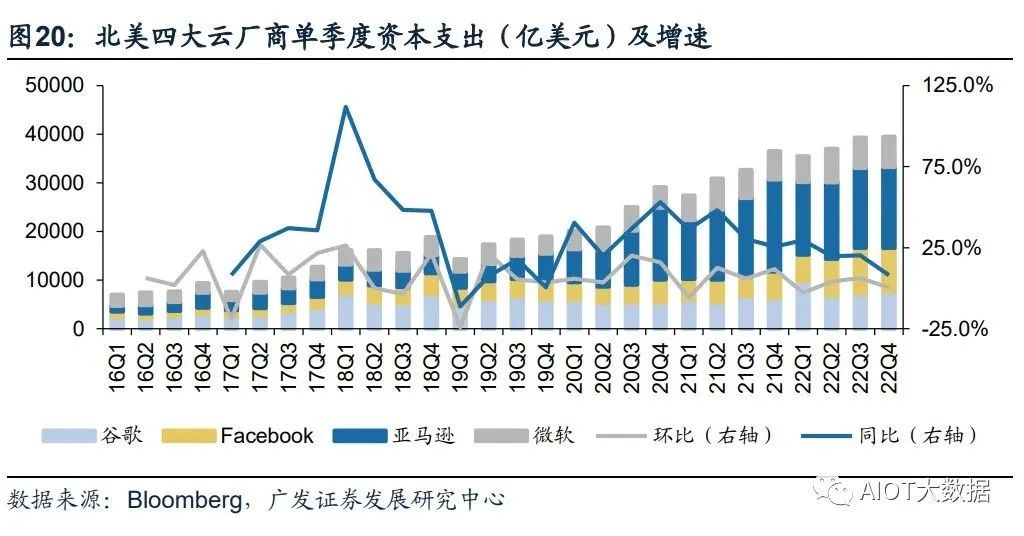
北美云厂商资本支出向技术基础设施和新数据中心架构倾斜。22Q4亚马逊资本支出 主要用于技术基础设施的投资,其中大部分用于支持AWS业务增长与支持履行网络 的额外能力。预计未来相关投资将延续,并增加在技术基础设施方面的支出。谷歌 指引2023年资本开支与2022年基本持平,其中技术基础设施有所增加,而办公基础 设施将减少。Meta2022年资本开支为314.3亿美元,同比增长69.3%,但同时Meta 略微调低其2023年资本开支预期至300-330亿美元(此前预期为340-370亿美元), 主要原因系减少数据中心建设的相关支出,转向新的更具成本效益的、同时支持AI 和非AI工作量的数据中心新架构。
国内三大运营商积极布局算力网络,资本支出向新兴业务倾斜。电信运营商作为数 字基座打造者,运营商数字业务板块成为收入增长的主要引擎,近几年资本支出由 主干网络向新兴业务倾斜。中国移动计划2022年全年算力网络投资480亿元,占其 总资本开支的39.0%。2022Q3,中国移动算力规模达到7.3EFLOPS,并计划在2025 年底达到20EFLOPS以上。中国电信产业数字化资本开支占比同比上升9.3pc,算力 总规模计划由2022年中的3.1EFLOPS提升至2025年底的16.3EFLOPS。中国联通 2022年预计算力网络资本开支达到145亿,同比提升43%,云投资预计提升88%。
作为算力基础设施建设的主力军,三大运营商目前已经进行前瞻性的基础设施布局。 通信运营商自身拥有优质网络、算力、云服务能力的通信运营商,同时具备天然的 产业链优势,依靠5G+AI技术优势,为下游客户提供AI服务能力,是新型信息服务 体系中重要的一环,助力千行百业数字化转型。在移动网络方面,中国运营商已建 设覆盖全国的高性能高可靠4/5G网络;在固定宽带方面,光纤接入(FTTH/O)端 口达到10.25亿个,占比提升至95.7%;在算力网络方面,运营商在资本开支结构上 向算力网络倾斜,提升服务全国算力网络能力。在AI服务能力方面,加快AI领域商 业化应用推出,发挥自身产业链优势,助力千行百业数字化转型。
(三)算力需求带动数据中心架构及技术加速升级
1、数据中心呈现超大规模发展趋势。超大规模数据中心,即Hyperscale Data Center,与传统数据中心的核心区别在于 超大规模数据中心具备更强大的可扩展性及计算能力。1)规模上,超级数据中心可 容纳的规模要比传统数据中心大得多,可以容纳数百万台服务器和更多的虚拟机;2) 性能上,超级数据中心具有更高的可扩展性和计算能力,能够满足数据处理数量和 速率大幅提升的需求。
具体来讲,相较于传统数据中心,超大规模数据中心的优势在于: (1)可扩展性:超大规模数据中心的网络基础架构响应更迅速、扩展更高效且更具 成本效益,并且提供快速扩展存储和计算资源以满足需求的能力,超大规模数据中 心通过在负载均衡器后水平扩展,快速旋转或重新分配额外资源并将其添加到现有 集群,可以实现快速向集群添加额外资源,从而在不中断操作的情况下进行扩展; (2)定制化:超大规模数据中心采用更新的服务器设计,具有更宽的机架,可以容 纳更多组件并且允许定制化设计服务器,使得服务器能够同时接入多个电源和硬盘 驱动器;
(3)自动化服务:超大规模数据中心提供自动化服务,帮助客户管理高流量网站和 需要专门处理的高级工作负载,例如密码学、基因处理和三维渲染; (4)冷却效率更高:超大规模数据中心对其电源架构进行了优化,并将冷却能力集 中在托管高强度工作负载的服务器,大大降低了成本和对环境的影响,电源使用效 率和冷却效率远高于传统数据中心;
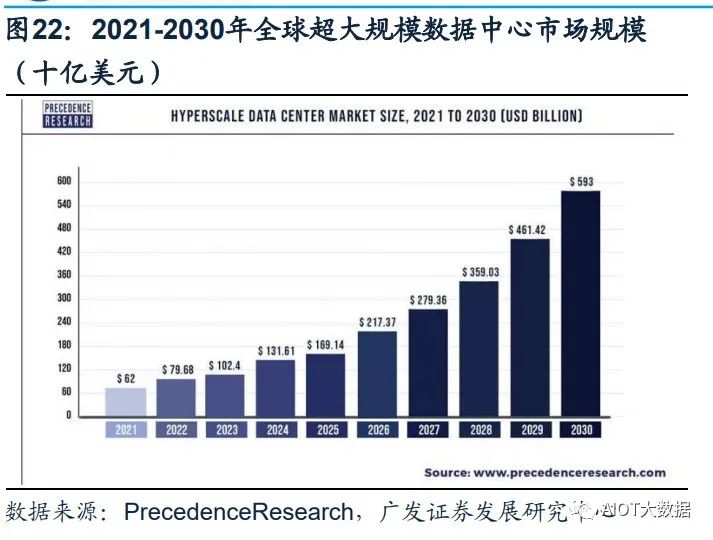
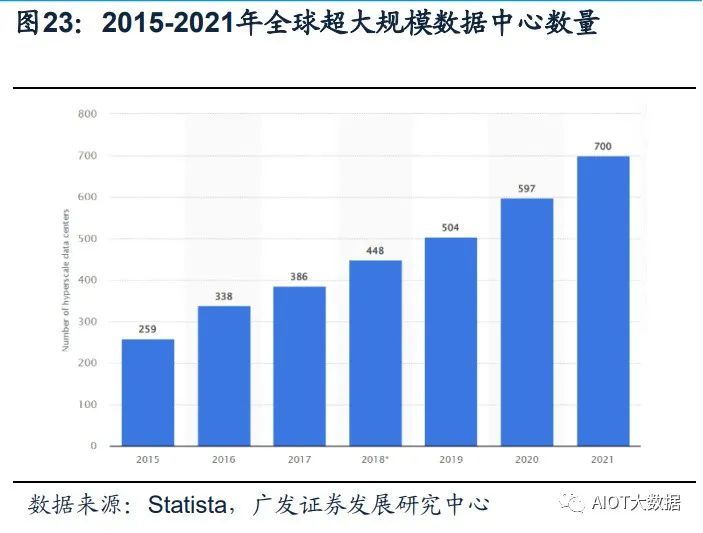
(5)工作负载更平衡:超大规模数据中心有效地将工作负载分布在多台服务器上, 从而避免单台服务器过热。避免了过热的服务器损坏附近的服务器,从而产生不必 要的连锁反应。 Statista数据显示,全球超大规模数据中心的数量从2015年的259个,提升到2021年 的700个。根据PrecedenceResearch的报告显示,全球超大规模数据中心市场规模 在2021年为620亿美元,到2030年将达到5930亿美元,预计在2022-2030年间以 28.52%的复合增长率(CAGR)增长。
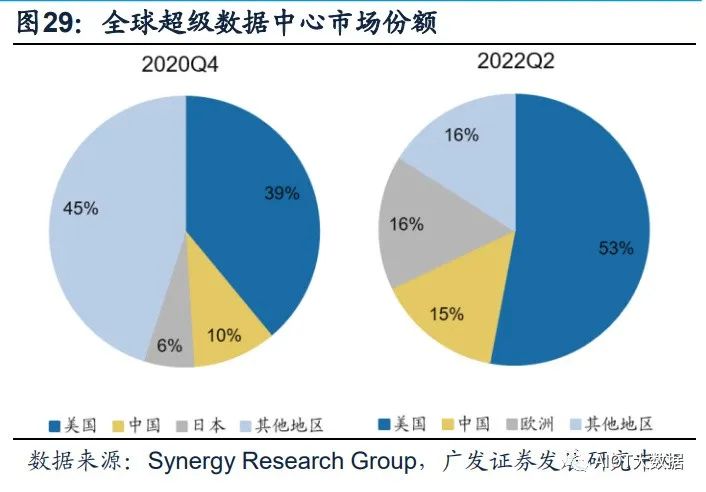
海内外云商均具备自己的超大规模数据中心。Structure Research在其报告中估计, 到2022年全球超大规模自建数据中心总容量将达到13177兆瓦(MW)。全球四大 超大规模数据中心平台——AWS、谷歌云、Meta和微软Azure——约占该容量的78%。 全球占主导地位的超大规模数据中心企业仍然是亚马逊、谷歌、Meta和微软,在中 国,本土企业阿里巴巴、华为、百度、腾讯和金山云都是领先的超大规模数据中心 企业。
2、IB网络技术将更广泛应用于AI训练超算领域。超级数据中心是具有更大规模和更高计算能力的数据中心。随着对数据处理数量和 速率需求的提升,数据中心的可扩展性需求也在迅速提升。超级数据中心在规模和 性能上较传统数据中心都有了大幅升级,能够满足超高速度扩展以满足超级需求的 能力。
泛AI应用是超算中心的重要下游。自20世纪80年代以来,超级计算主要服务于科研 领域。传统超算基本上都是以国家科研机构为主体的超算中心,如气象预测、地震 预测、航空航天、石油勘探等。截止2022年底,国内已建成10家国家超级计算中心, 不少省份都建立起省级超算中心,服务于当地的中科院、气象局以及地震爆炸模型。 一方面,行业头部企业将超算应用于芯片设计、生物医疗、材料测试等工业应用场 景;另一方面,自动驾驶训练、大语言模型训练、类ChatGPT等AI训练的需求,也 推动超算应用场景延伸至图像识别、视频识别定位、智能驾驶场景模拟以及对话和 客服系统等,成为超算中心的重要下游。
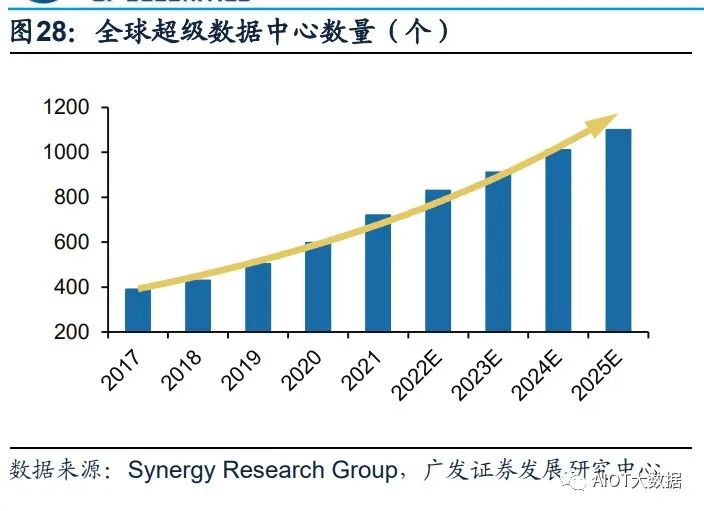
超级数据中心成为算力储备的重要方向,中美加速算力基建布局。凭借其在算力能 力及能耗效率的巨大提升,超级数据中心在算力储备中的地位日渐凸显。根据 Synergy Research Group数据,全球超级数据中心数量从2017年的390个增长至 2021年二季度的659个,增长近一倍,预计2024年总数将超1000个。份额方面,中 美持续加强超级数据中心的布局,占全球市场份额持续提升。
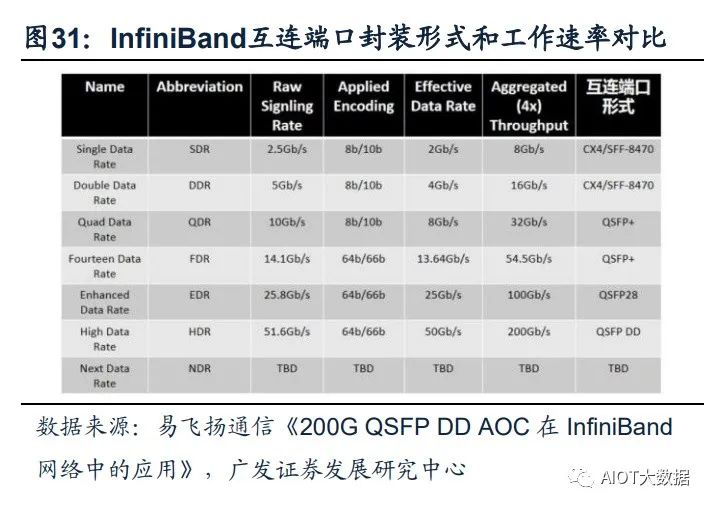
InfiniBand网络满足大带宽和低时延的需求,成为超算中心的主流。InfiniBand(简 称IB)是一个用于高性能计算的计算机网络通信标准,主要应用于大型或超大型数 据中心。IB网络的主要目标是实现高的可靠性、可用性、可扩展性及高性能,且能 在单个或多个互联网络中支持冗余的I/O通道,因此能够保持数据中心在局部故障时 仍能运转。相比传统的以太网络,带宽及时延都有非常明显的优势。(一般InfiniBand 的网卡收发时延在600ns,而以太网上的收发时延在10us左右,英伟达推出的 MetroX-3提升长距离InfiniBand系统带宽至400G)。作为未来算力的基本单元,高 性能的数据中心越来越多的采用InfiniBand网络方案,尤其在超算中心应用最为广 泛,成为AI训练网络的主流。
(四)细分受益环节
GPT-4多模态大模型将引领新一轮AI算力需求的爆发,超大规模数据中心及超算数 据中心作为泛AI领域的重要基础设施支持,其数量、规模都将相应增长,带动整个 算力基础设施产业链(如高端服务器/交换机、CPO技术、硅光、液冷技术)的渗透 加速。同时在应用侧,Copilot的推出加速AI在办公领域的赋能,看好办公场景硬件 配套厂商机会。
1、服务器/交换机: AIGC带动算力爆发式增长,全球进入以数据为关键生产要素的数字经济时代。从国 内三大运营商资本支出结构上看,加码算力基础设施投资成重要趋势。重点推荐: 中兴通讯。公司作为运营商板块算力投资的核心受益标的,持续在服务器及存储、 交换机/路由器、数据中心等算力基础设施领域加强布局,将作为数字经济筑路者充 分受益我国数字经济建设。
算力需求带动上游硬件设备市场规模持续增长,高规格产品占比提升。伴随着数据 流量持续提升,交换机作为数据中心必要设备,预计全球数据中心交换机保持稳定 增长。2021年全球数据中心交换机市场规模为138亿美元,预计到2031年将达246 亿美元,2022年至2031年复合年增长率为5.9%。多元开放的AI服务器架构为可以人 工智能发展提供更高的性能和可扩展性的AI算力支撑,随着AI应用的发展,高性能 服务器数量有望随之增长,带动出货量及服务器单价相应提升。根据IDC报告, 2022Q3,200/400GbE交换机市场收入环比增长25.2%,100GbE交换机收入同比增 长19.8%,高速部分呈现快速增长。
2、光模块/光芯片: 算力需求提升推动算力基础设施升级迭代,传统可插拔光模块技术弊端和瓶颈开始 显现。(1)功耗过高,AI技术的加速落地,使得数据中心面临更大的算力和网络流 量压力,交换机、光模块等网络设备升级的同时,功耗增长过快。以博通交换机芯 片为例,2010年到2022年交换机芯片速率从640G提升到51.2T,光模块速率从10G 迭代到800G。速率提升的同时,交换机芯片功耗提升了约8倍,光模块功耗提升了 26倍,SerDes功耗提升了25倍。(2)交换机端口密度难以继续提升,光模块速率 提升的同时,自身体积也在增大,而交换机光模块端口数量有限。(3)PCB材料遭 遇瓶颈,PCB用于传输高速电信号,传统可插拔光模块信号传输距离长、传输损失 大,更低耗损的可量产PCB材料面临技术难题难以攻克。
NPO/CPO技术有望成为高算力背景下的解决方案。CPO(光电共封装技术)是一 种新型的高密度光组件技术,将交换芯片和光引擎共同装配在同一个Socketed(插 槽)上,形成芯片和模组的共封装。CPO可以取代传统的插拔式光模块技术,将硅 光电组件与电子晶片封装相结合,从而使引擎尽量靠近ASIC,降低SerDes的驱动功 耗成本,减少高速电通道损耗和阻抗不连续性,实现更高密度的高速端口,提升带 宽密度,大幅减少功耗。
CPO技术的特点主要有:(1)CPO技术缩短了交换芯片和光引擎之间的距离(控制在5~7cm),使得高速电信号在两者之间实现高质量传 输,满足系统的误码率(BER)要求;(2)CPO用光纤配线架取代更大体积的可 插拔模块,系统集成度得到提升,实现更高密度的高速端口,提升整机的带宽密度; (3)降低功耗,根据锐捷网络招股说明书,采用CPO技术的设备整机相比于采用可 插拔光模块技术的设备,整机功耗降低23%。
高算力背景下,数据中心网络架构升级带动光模块用量扩张及向更高速率的迭代。 硅光、相干及光电共封装技术(CPO)等具备高成本效益、高能效、低能耗的特点, 被认为是高算力背景下的解决方案。CPO将硅光电组件与电子晶片封装相结合,使 引擎尽量靠近ASIC,减少高速电通道损耗,实现远距离传送。目前,头部网络设备 和芯片厂商已开始布局硅光、CPO相关技术与产品。
3、数据中心: IDC数据中心:“东数西算”工程正式全面启动一周年,从系统布局进入全面建设阶 段。随着全国一体化算力网络国家枢纽节点的部署和“东数西算”工程的推进,算 力集聚效应初步显现,算力向规模化集约化方向加速升级,同时数据中心集中东部 的局得到改善,西部地区对东部地区数据计算需求的支撑作用越发明显。我们认为 政策面推动供给侧不断出清,AI等应用将带动新一轮流量需求,有望打破数据中心 近两年供给过剩的局面,带动数据中心长期发展。
液冷温控:随云计算、AI、超算等应用发展,数据中心机柜平均功率密度数预计将 逐年提升,高密度服务器也将被更广泛的应用于数据中心中。数据中心液冷技术能 够稳定CPU温度、保障CPU在一定范围内进行超频工作不会出现过热故障,有效提 升了服务器的使用效率和稳定性,有助于提高数据中心单位空间的服务器密度,大幅 提升数据中心运算效率,液冷技术有望在超高算力密度场景下持续渗透。
4、运营商: 通信运营商自身拥有优质网络、算力、云服务能力的通信运营商,同时具备天然的 产业链优势,依靠5G+AI技术优势,为下游客户提供AI服务能力,是新型信息服务 体系中重要的一环,助力千行百业数字化转型。作为算力基础设施建设的主力军已 经进行前瞻性的基础设施布局。中国移动打造九天人工智能平台,推进AI商业化, 赋能中国移动内外部数智化转型;中国电信全面布局大模型技术,积极探索产业版 “ChatGPT”的商业化应用;中国联通全力升级算力网络,推动5G和AI技术的融合。
5、企业通信: 3月16日晚微软正式宣布推出Microsoft 365 Copilot,将大型语言模型(LLMs)的能 力嵌入到Office办公套件产品中。基于GPT-4的Copilot以其视频+图文的多模态分析 以及更强大生成与理解能力,可更深度、全面发挥视频会议AI助理功能,比如可以确定目标捕捉发言总结某人谈话要点、全面理解会议主要内容并自动整理及发送会 议纪要等。随着Copilot更强大功能对微软办公套件的加持,有望带动Teams需求的 增长,中国企业通信终端厂商将作为微软重要的硬件合作伙伴有望深度受益。
GPT将如何影响我们的工作?
(报告出品方/作者:东北证券,黄净、吴雨萌)
1. 总结:GPT 对工作的冲击将跨越各个职业
3 月 17 日,OpenAI 官网发布最新研究论文 GPTs are GPTs: An early look at the labor market impact potential of large language models,对 LLM 语言模型,特别是 GPT, 对美国不同职业和行业的潜在影响进行了探讨。我们将论文中的结论进行了汇总:
1、 多数职业将受到 GPT 的冲击:80%的工人有至少 10%的任务可以被 GPT 减少 ≥50%的工作时间;19%的工人有至少 50%的任务可以被 GPT 减少≥50%的工 作时间;
2、 GPT 的影响横跨各类薪资层级:尽管存在部分特殊情况,但整体来看,工资越 高,受 GPT 冲击的程度越大;
3、 职业技能与 GPT 的冲击程度有关:科学和批判性思维技能最不容易受 GPT 冲 击,而编程和写作技能受影响的程度最高;
4、 高学历更容易受到 GPT 的冲击:持有学士、硕士和更高学位的人比没有正规教 育学历的人更容易受到 GPT 的冲击;
5、 在职培训时间时长与 GPT 冲击程度有关:在职培训时长最长的职业收入水平偏 低,且受 GPT 冲击程度最低,而没有在职培训或只需实习的工作则表现出更高 的收入水平和更容易受 GPT 冲击的属性。
6、 证券相关和数据处理行业受 GPT 影响程度最高:在人类打分和 GPT 打分模式 下,证券商品合约及其他金融投资和数据处理托管分别是受 GPT 冲击程度最高 的行业;在直接调用 GPT 模型的情况下,口译笔译和数学家分别是受影响最大 的职业;在进一步开发 GPT 衍生功能的情况下,数学家和会计审计则分别为受 影响最大的职业。
2. 统计指标来源及解释
2.1. 数据来源
2.1.1. 美国职业、工作活动和任务数据的来源
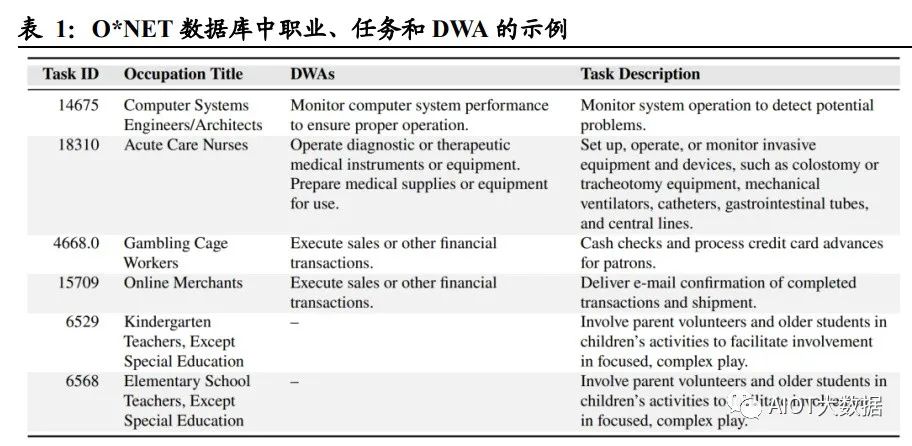
论文中使用了 O*NET 27.2 数据库,包含 1016 种职业,以及各个职业的工作活动 (Detailed Work Activities,简称 DWA)和任务(Task)。论文中对工作活动和任务 给出了定义: 详细工作活动 DWA 是由完成任务构成的综合操作,大多数工作活动与一个或 多个任务相对应,该数据集中包括 2087 种 DWA; 任务 Task 是某个特定职业的基础单位,一项任务可以与 0 个、1 个或多个 DWA 关联,且每个任务都有与之对应的职业,该数据集中包括 19265 种任务。 例如,对于职业“急症护理护士”,其工作活动 DWA 包括“操作诊断或治疗性医疗仪 器或设备”和“准备医疗用品或设备”,其任务包括“设置、操作或监测侵入性设备和 装置,例如结肠造口术或气管切开术设备、机械呼吸机、导管、胃肠道管和中心插 管”。
2.1.2. 工资、就业及人口数据来源
论文选取了美国劳工统计局(Bureau of Labor Statistics,以下简称 BLS)提供的 2020 年和 2021 年职业就业系列中的就业和工资数据。该数据集包括职业名称、每个职 业的工人数量、2031 年职业水平的就业预测、职业准入的教育水平以及获得职业能 力所需的在职培训情况。BLS 数据库可以同 O*NET 数据库进行联动:通过当前人 口调查(Current Population Survey,简称 CPS),将 O*NET 中的任务和工作活动数 据集与 BLS 劳动力人口统计数据联系起来,形成截面数据。
2.2. 暴露度 Exposure:用于衡量 GPT 对各职业的冲击程度
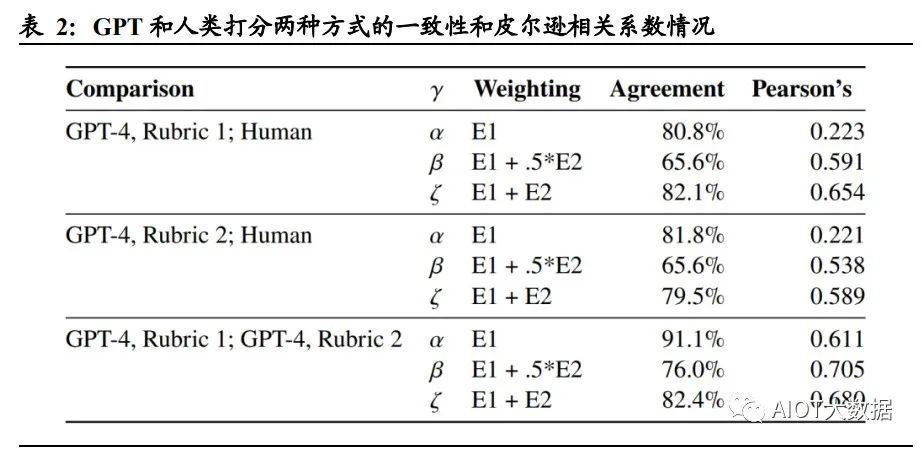
论文中设定了暴露度 Exposure 这一指标,作为重点讨论的对象。暴露度 Exposure 用于衡量 GPT 对特定工作活动和任务的冲击程度,即保证一项工作活动和任务完成 质量相同的情况下,使用 GPT 或 GPT 驱动的系统是否能够将执行工作活动或任务 的所需时间减少 50%以上。 论文采用了两种暴露度的注释方式,分别为人工评分法与 GPT-4 评级法: 人工评分:通过对 O*NET 数据库中的每一个工作活动 DWA 和任务进行人为 归类并注释打分。 GPT-4 评级:采用早期版本的 GPT-4 对工作活动和任务进行注释打分。
论文将暴露度分为以下三类: E0 无暴露度:如果经验丰富的工人在高质量完成任务时所需的时间没有明显减少 50%,或使用 GPT 相关技术会降低工作活动/任务的完成质量,则定义为 E0(例: 需要高强度人际互动的任务)。 E1 直接暴露:在保证完成质量相同的前提下,如果通过 ChatGPT 或 OpenAI 直接访 问 LLM 或 GPT-4 可以将完成工作活动或任务所需时间减少 50%及以上,则将其定 义为 E1(例:指令编写、转换文本和代码的任务)。 E2 LLM+暴露:直接访问 LLM 不能将完成任务所需的时间减>50%,但在 LLM 基 础上开发额外功能后可以达成目的,则定义该类工作活动和任务为 E2(例:总结超过 2000 字的文档并回答关于文档的问题)。 为了更为准确地衡量暴露度这一指标的统计学意义,论文中构建了三个度量指标, α、β 和 ζ,分别衡量低、中、高水平下的 GPT 对各职业的冲击程度。其中,α=E1, 代表一个职业受 GPT 冲击程度的下限;β=E1+0.5*E2,其中 E2 的 0.5 倍权重旨在解 释通过补充工具或应用程序来完成任务/工作活动需要额外计算的暴露度;ζ=E1+E2, 代表一个职业受 GPT 冲击程度的上限,可用于评估一项工作/任务对于 GPT 及 GPT 驱动的系统的最大暴露度(即GPT进一步开发后,一项工作/任务受到的最大影响)。
3. 研究结论:30%的职业或任务将受到 GPT 冲击
前文将暴露度 Exposure 这一指标的定义进行了描述,论文中还将暴露度的衡量指标 α、β 和 ζ 进行了统计数据的汇总。不论采取人类打分的方式还是 GPT-4 打分,暴露 度α的均值在0.14左右,表示了从平均意义上说,15%左右的职业/任务暴露于GPT, 即 15%左右的工作可能会被现有的 LLM/GPT-4 降低 50%以上的工作时间。类似 地,暴露度 β 和 ζ 均值分别在 0.3 和 0.5 左右,代表 30%/50%的职业或任务将受到 中/高水平的 GPT 冲击,即减少工作时间 50%及以上。
4. 研究结论:工资水平与 GPT 冲击程度呈正相关
论文探索了职业、工人分布程度与暴露度之间的关系。对于中等水平的 GPT(β) 来说,约 19%的工人有 50%以上的任务将受到 GPT 的冲击,80%的工人有 10%以 上的任务受到了 GPT 的冲击;18%的职业中有 50%以上的任务受到了 GPT 的冲 击。
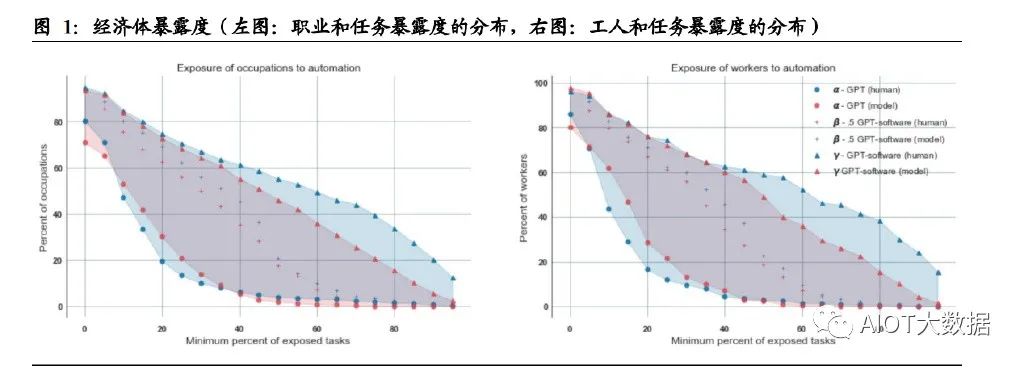
论文还对工资、就业水平与暴露度的相关性进行了探讨。两种打分模式下,尽管存 在一些高暴露度的低工资职业和低暴露度的高工资职业,整体图表显示,工资越高, 受 GPT 影响的程度也随之增加。而 GPT 冲击程度与就业水平则并无显著关联。
5. 研究结论:科学和批判性思维是受 GPT 冲击最小的技能
论文研究了不同职业中技能重要性与 GPT 暴露度之间的关系。作者将 O*NET 数据 库中的基本技能进行标准化,并将其与暴露度指标(α,β,ζ)进行回归分析,检验 技能重要性和暴露度之间的关联度。结果表明,科学和批判性思维技能(Science and CriticalThinking)与暴露度呈强烈的负相关(以β作为研究,相关系数分别-0.23 和 -0.19),即需要该技能的职业或任务不太可能受到 GPT 的冲击;相反,编程和写作 技能(Programming and Writing)与暴露度呈现出强正相关(相关系数分别为 0.62 和 0.47),即涉及该技能的职业更容易受到 GPT 的冲击。
6. 研究结论:学历水平和在职培训时长与 GPT 冲击程度相关
论文研究了不同工作类型的准入壁垒与暴露程度的关系。作者选取 O*NET 数据库 中的“工作区(Job Zone)”概念作为变量,同一工作区中的职业在准入教育水平、 准入相关经验、在职培训程度方面具有更高的相似度。O*NET 数据库将工作区分为 5 种,随着准入工作经验的增加,各工作区收入的中位数单调递增,如工作区 1 的 准入工作经验是 3 个月,收入的中位数为 30,230 美元,而工作区 5 的准入工作经验 是≥4 年,收入中位数为 80,980 美元。 研究结果显示,从工作区 1 到工作区 4,暴露度水平逐渐增加,但在工作区 5 则保 持相似甚至有所降低。平均来说,在不同工作区,50%以上任务受到 GPT 冲击的职 业比例分别为 0.00%(工作区 1)、6.11%(工作区 2)、10.57%(工作区 3)、34.5% (工作区 4)和 26.45%(工作区 5)。
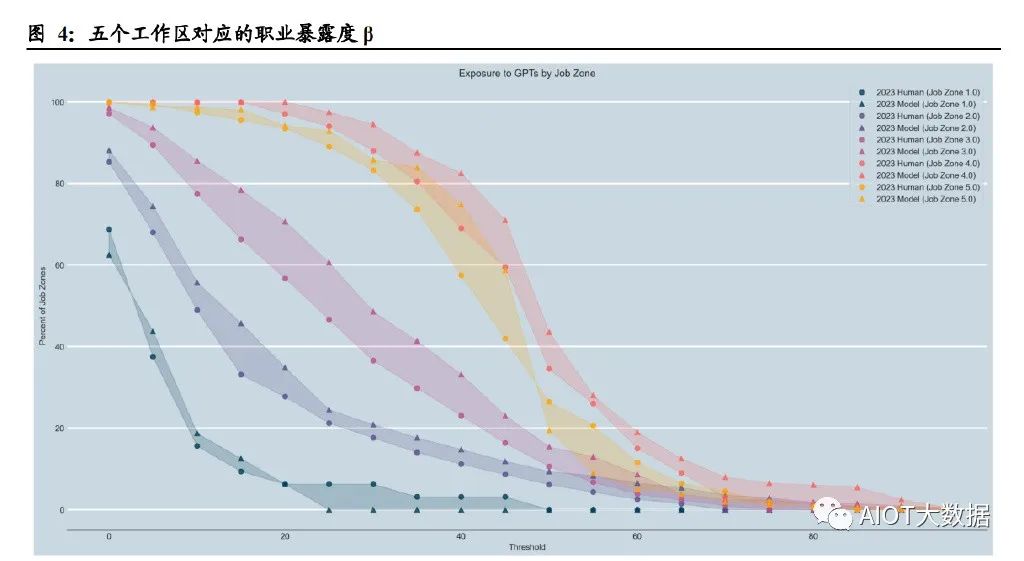
论文还单独研究了职业准入教育水平和在职培训情况与暴露度的关系。结果表明, 持有学士、硕士和更高学位的人比没有正规教育学历的人更容易受到GPT的冲击; 在职培训时间最长的职业受 GPT 冲击程度最低(且这类工作的收入水平更低),而 没有在职培训或只需要实习的工作表现出更高的收入水平和更容易受 GPT 冲击的 属性。
7. 研究结论:证券投资和数据处理可能是受冲击程度最高的职业
论文中对各行业受 GPT 冲击的程度进行了排序。结果表明,人类打分模式下,证券 商品合约及其他金融投资及相关活动是受 GPT 冲击最为严重的行业,而 GPT 打分 模式下,数据处理托管和相关服务的受冲击程度最高。 在直接调用 GPT 模型的情况下(暴露度 α),口译笔译和数学家分别是两种打分模 式下受影响最大的职业。在进一步开发 GPT 衍生功能的情况下(暴露度 ζ),人类打 分模式中,有 15 项职业的所有任务都将被 GPT 降低 50%以上的工作时间,包括数 学家、税务准备、量化分析师、作家、网页和数字化页面设计师;GPT 打分模式中, 有 86 项职业的所有任务都将被 GPT 降低 50%以上的工作时间,包括审计会计、新 闻分析记者、法务专员、临床数据经理、气象变化政策分析师等。从方差角度看, 搜索营销策略师、平面设计师、投资基金经理、财务经理、汽车损坏保险估价师可 能是受 GPT 影响程度争议最大的几项职业。
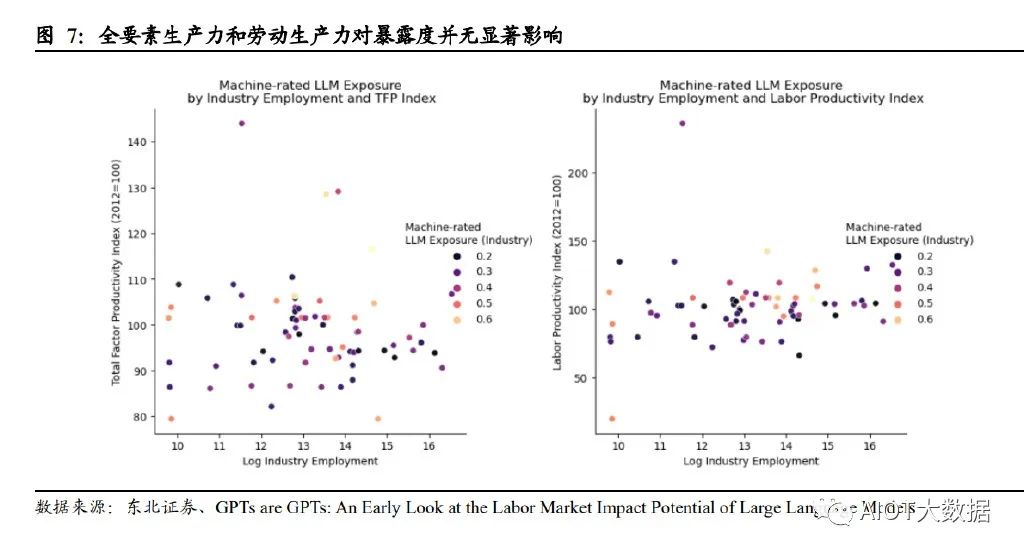
此外,论文研究表明,近期的生产增长率(包含全要素和劳动力两方面)与暴露度 并无显著相关性。换言之,如果 LLM 有可能在不同行业之间以不同程度提高生产力, 那么生产力最高的企业可能会良性循环。由于这些行业的生产需求普遍缺乏弹性, 生产率最高的部门在经济投入中所占的比例将缩小。
8. 对国内的探讨:卖方分析师≥80%的工作可能受 GPT 冲击
我们采用了论文中类似的方法,试图对国内证券行业相关工作进行打分,并计算了 其可能受 GPT 冲击的程度。论文中采用的 O*NET 数据库将每一项职业对应的任务、 工作活动都进行了定义,但由于国内暂无类似的数据库和较为详细的职业分类,我 们仍采用了 O*NET 数据库中的分类,但依据国内的情况做了本土化调整,例如, O*NET 数据库中的金融投资分析师(Financial and InvestmentAnalysts)职业包含任 务“对绿色建筑和绿色改造项目进行投资财务分析(Conduct financial analyses related to investments in green construction or green retrofitting projects)”,而中国的分析师普 遍不涉及这项工作,因此予以删除调整。
我们选取了 O*NET 数据库中的Financial and Investment Analysts金融和投资分析师、 Investment Fund Managers 投资基金经理这两项职业和对应的任务与工作活动 (DWA),并根据中国的实际情况,将其重新组合为二级卖方分析师、一级市场投 行和基金经理。采用与论文相同的标准,对这些职业的任务/工作活动进行了打分, 并计算了暴露度β和ζ。结果显示,按任务情况进行计算,三种行业对比下,二级 卖方分析师受 GPT 冲击的程度高于投行一级市场和基金经理。在经过专业知识训 练的 LLM 和 GPT 的帮助下(代表暴露度ζ),卖方分析师可能有 82%的任务将被 减少 50%以上的工作时间,基金经理可能有 55%的任务被减少 50%以上的工作时 间。按照工作活动计算,二级卖方分析师和一级市场投行受 GPT 影响的程度相差不 大,约为 65%左右,但仍显著高于基金经理。
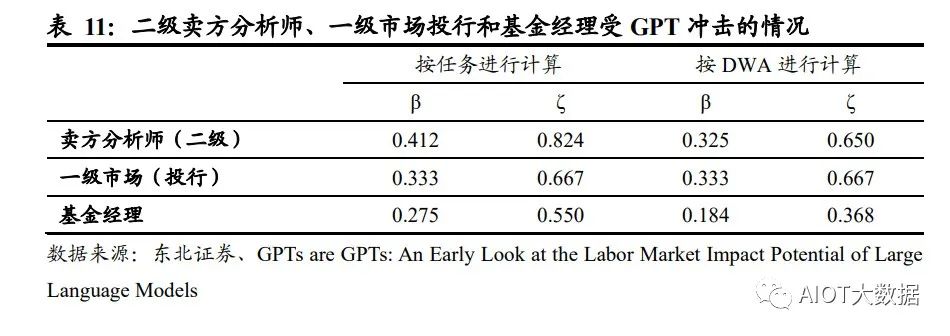
在论文中,作者将 E1 直接暴露定义为运用现有 ChatGPT 和 OpenAI 接口直接方位 LLM 可以减少50%以上的工作时间,对应的工作内容包括编写文本(2000 字以内)、 翻译、准备短资料等,而证券业的任务由于涉及专业知识、撰写长度超过 2000 字的 报告等,因此在进行打分时,不存在直接暴露 E1 的情况,所有任务及工作活动均 被归类为无暴露(E0)或 LLM+暴露(E2)。另外,在打分过程中,根据论文作者 的标准,我们将法律法规要求人类完成的任务、需要确认/授权/决策的任务、涉及雇 佣员工和培训团队的任务以及涉及大量人际交流的任务归类为无暴露(E0),分析 类、文本整理类、资料搜集类工作定义为 LLM+暴露(E2)。值得注意的是,由于基 金经理这一职业涉及更多审查合规性、响应监管要求等任务,因此展现出较分析师 更低的暴露度(ζ),即受 GPT 的影响低于分析师。
根据论文中对于不同行业的暴露度统计,按照人类打分,美国证券商品合约及其他金融投资的暴露度β在 0.6-0.7 之间,我们将这一数值作为美国证券行业受到 GPT 冲击的平均水平。为了方便对比,我们采用暴露度β进行对比,国内卖方分析师、 一级市场(投行)和基金经理分别对应的暴露度 0.41、0.33 和 0.28,证明国内卖方 分析师、一级市场(投行)和基金经理受到 GPT 冲击的情况略好于美国证券行业 受冲击的平均水平。我们推测可能由以下原因导致:
1、 美国拥有更高比例的量化分析师:论文中特别提到,在经过专业知识训练的 LLM 和 GPT 的帮助下(暴露度ζ),人类打分模式下,量化分析师的暴露度是 100%,即量化分析师所有的任务都可以在 GPT 的帮助下大幅降低工作时间;美 国量化分析行业发展相对靠前,量化分析师可能拥有更高的权重,从而拉高行 业整体的暴露度;
2、 不同证券市场的有效性可能对工作任务的打分产生影响:美国资本市场被认为 是半强有效市场,较 A 股相比,美股市场的信息更加公开透明;GPT 在公开信 息的搜集整理、归纳总结方面具有明显的优势,因此相比国内,GPT 和 LLM 能 够更好地帮助美国的证券从业者降低工作时长,从而表现出更高的暴露度。
GPT~4引发新一轮AI算力需求爆发
(报告出品方/作者:广发证券,李娜,王亮)
一、OpenAI正式发布多模态大模型GPT-4,实现多重能力跃升
(一)多模态大模型GPT-4是OpenAI公司GPT系列最新一代模型
美国OpenAI公司成立于2015年12月,是全球顶级的人工智能研究机构之一,创始人 包括Elon Musk、著名投资者Sam Altman、支付服务PayPal创始人Peter Thiel等人。 OpenAI作为人工智能领域的革命者,成立至今开发出多款人工智能产品。2016年, OpenAI推出了用于强化学习研究的工具集OpenAI Gym;同时推出开源平台OpenAI Universe,用于测试和评估智能代理机器人在各类环境中的表现。2019年,OpenAI 发布了GPT-2模型,可根据输入文本自动生成语言,展现出人工智能创造性思维的 能力;2020年更新了GPT-3语言模型,并在其基础上发布了OpenAI Codex模型,该 模型可以自动生成完整有效的程序代码。
2021年1月,OpenAI发布了OpenAI CLIP, 用于进行图像和文本的识别分类;同时推出全新产品DALL-E,该模型可以根据文字 描述自动生成对应的图片,2022年更新的DALL-E2更是全方位改进了生成图片的质 量,获得了广泛好评。 2022年12月,OpenAI推出基于GPT-3.5的新型AI聊天机器人ChatGPT,在发布进 两个月后拥有1亿用户,成为史上用户增长最快的应用;美东时间2023年3月14日, ChatGPT的开发机构OpenAI正式推出多模态大模型GPT-4。
GPT(General Pre-Training)系列模型即通用预训练语言模型,是一种利用 Transformer作为特征抽取器,基于深度学习技术的自然语言处理模型。 GPT系列模型由OpenAI公司开发,经历了长达五年时间的发展: (1)其最早的产品GPT模型于2018年6月发布,该模型可以根据给定的文本序列进 行预测下一个单词或句子,充分证明通过对语言模型进行生成性预训练可以有效减 轻NLP任务中对于监督学习的依赖; (2)2019年2月GPT-2模型发布,该模型取消了原GPT模型中的微调阶段,变为无 监督模型,同时,GPT-2采用更大的训练集尝试zero-shot学习,通过采用多任务模 型的方式使其在面对不同任务时都能拥有更强的理解能力和较高的适配性;
(3)GPT-3模型于2020年6月被发布,它在多项自然语言处理任务上取得了惊人的 表现,并被认为是迄今为止最先进的自然语言处理模型之一。GPT-3训练使用的数 据集为多种高质量数据集的混合,一次保证了训练质量;同时,该模型在下游训练 时用Few-shot取代了GPT-2模型使用的zero-shot,即在执行任务时给予少量样例, 以此提高准确度;除此之外,它在前两个模型的基础上引入了新的技术——“零样 本学习”,即GPT-3即便没有对特定的任务进行训练也可以完成相应的任务,这使 得GPT-3面对陌生语境时具有更好的灵活性和适应性。
(4)2022年11月,OpenAI发布GPT-3.5模型,是由GPT-3微调出来的版本,采用 不同的训练方式,其功能更加强大。基于GPT-3.5模型,并加上人类反馈强化学习 (RLHF)发布ChatGPT应用,ChatGPT的全称为Chat Generative Pre-trained Transformer,是建立在大型语言模型基础上的对话式自然语言处理工具,表现形式 是一种聊天机器人程序,能够学习及理解人类的语言,根据聊天的上下文进行互动, 甚至能够完成翻译、编程、撰写论文、编辑邮件等功能。 (5)2023年3月,OpenAI正式发布大型多模态模型GPT-4(输入图像和文本,输出 文本输出),此前主要支持文本,现模型能支持识别和理解图像。
(二)GPT大模型通过底层技术的叠加,实现组合式的创新
由于OpenAI并没有提供关于GPT-4用于训练的数据、算力成本、训练方法、架构等 细节,故我们本章主要讨论ChatGPT模型的技术路径。 ChatGPT模型从算法分来上来讲属于生成式大规模语言模型,底层技术包括 Transformer架构、有监督微调训练、RLHF强化学习等,ChatGPT通过底层技术 的叠加,实现了组合式的创新。 GPT模型采用了由Google提出的Transformer架构。Transformer架构采用自注意 力机制的序列到序列模型,是目前在自然语言处理任务中最常用的神经网络架构之 一。相比于传统的循环神经网络(RNN)或卷积神经网络(CNN),Transformer 没有显式的时间或空间结构,因此可以高效地进行并行计算,并且Transformer具有 更好的并行化能力和更强的长序列数据处理能力。
ChatGPT模型采用了“预训练+微调”的半监督学习的方式进行训练。第一阶段是 Pre-Training阶段,通过预训练的语言模型(Pretrained Language Model),从大 规模的文本中提取训练数据,并通过深度神经网络进行处理和学习,进而根据上下 文预测生成下一个单词或者短语,从而生成流畅的语言文本;第二阶段是Fine-tuning 阶段,将已经完成预训练的GPT模型应用到特定任务上,并通过少量的有标注的数 据来调整模型的参数,以提高模型在该任务上的表现。
ChatGPT在训练中使用了RLHF人类反馈强化学习模型,是GPT-3模型经过升级并 增加对话功能后的最新版本。2022年3月,OpenAI发布InstructGPT,这一版本是 GPT-3模型的升级版本。相较于之前版本的GPT模型,InstructGPT引入了基于人类 反馈的强化学习技术(Reinforcement Learning with Human Feedback,RLHF), 对模型进行微调,通过奖励机制进一步训练模型,以适应不同的任务场景和语言风 格,给出更符合人类思维的输出结果。
RLHF的训练包括训练大语言模型、训练奖励模型及RLHF微调三个步骤。首先,需 要使用预训练目标训练一个语言模型,同时也可以使用额外文本进行微调。其次, 基于语言模型训练出奖励模型,对模型生成的文本进行质量标注,由人工标注者按 偏好将文本从最佳到最差进行排名,借此使得奖励模型习得人类对于模型生成文本 序列的偏好。最后利用奖励模型输出的结果,通过强化学习模型微调优化,最终得 到一个更符合人类偏好语言模型。
(三)GPT-4相较于ChatGPT实现多重能力跃迁
ChatGPT于2022年11月推出之后,仅用两个月时间月活跃用户数便超过1亿,在短 时间内积累了庞大的用户基数,也是历史上增长最快的消费应用。多模态大模型GPT-4是OpenAI的里程碑之作,是目前最强的文本生成模型。 ChatGPT推出后的三个多月时间里OpenAI就正式推出GPT-4,再次拓宽了大模型的 能力边界。GPT-4是一个多模态大模型(接受图像和文本输入,生成文本),相比 上一代,GPT-4可以更准确地解决难题,具有更广泛的常识和解决问题的能力:更 具创造性和协作性;能够处理超过25000个单词的文本,允许长文内容创建、扩展 对话以及文档搜索和分析等用例。
(1)GPT-4具备更高的准确性及更强的专业性。GPT-4在更复杂、细微的任务处理 上回答更可靠、更有创意,在多类考试测验中以及与其他LLM的benchmark比较中 GPT-4明显表现优异。GPT-4在模拟律师考试GPT-4取得了前10%的好成绩,相比 之下GPT-3.5是后10%;生物学奥赛前1%;美国高考SAT中GPT-4在阅读写作中拿 下710分高分、数学700分(满分800)。
(2)GPT能够处理图像内容,能够识别较为复杂的图片信息并进行解读。GPT-4 突破了纯文字的模态,增加了图像模态的输入,支持用户上传图像,并且具备强大 的图像能力—能够描述内容、解释分析图表、指出图片中的不合理指出或解释梗图。 在OpenAI发布的产品视频中,开发者给GPT-4输入了一张“用VGA电脑接口给 iPhone充电”的图片,GPT-4不仅可以可描述图片,还指出了图片的荒谬之处。
(3)GPT-4可以处理超过25000字的文本。在文本处理上,GPT-4支持输入的文字 上限提升至25000字,允许长文内容创建、扩展对话以及文档搜索和分析等用例。 且GPT-4的多语言处理能力更优,在GPT-4的测评展示中,GPT-4可以解决法语的 物理问题,且在测试的英语、拉脱维亚语、威尔士语和斯瓦希里语等26种语言中, 有24种语言下,GPT-4优于GPT-3.5和其他大语言模型(Chinchilla、PaLM)的英 语语言性能。(4)具备自我训练与预测能力,同时改善幻觉、安全等局限性。GPT-4的一大更新 重点是建立了一个可预测拓展的深度学习栈,使其具备了自我训练及预测能力。同 时,GPT-4在相对于以前的模型已经显著减轻了幻觉问题。在OpenAI的内部对抗性 真实性评估中,GPT-4的得分比最新的GPT-3.5模型高 40%;在安全能力的升级上, GPT-4明显超出ChatGPT和GPT3.5。
(四)商业模式愈发清晰,微软Copilot引发跨时代的生产力变革
OpenAI已正式宣布为第三方开开发者开放ChatGPT API,价格降低加速场景应用 爆发。起初ChatGPT免费向用户开放,以获得用户反馈;今年2月1日,Open AI推 出新的ChatGPT Plus订阅服务,收费方式为每月20美元,订阅者能够因此而获得更 快、更稳定的响应并优先体验新功能。3月2日,OpenAI官方宣布正式开放ChatGPT API(应用程序接口),允许第三方开发者通过API将ChatGPT集成至他们的应用程 序和服务中,价格为1ktokens/$0.002,即每输出100万个单词需要2.7美元,比已有 的GPT-3.5模型价格降低90%。模型价格的降低将推动ChatGPT被集成到更多场景 或应用中,丰富ChatGPT的应用生态,加速多场景应用的爆发。
GPT-4发布后OpenAI把ChatGPT直接升级为GPT-4最新版本,同时开放了GPT-4 的API。ChatGPT Plus付费订阅用户可以获得具有使用上限的GPT-4访问权限(每4 小时100条消息),可以向GPT-4模型发出纯文本请求。用户可以申请使用GPT-4 的API,OpenAI会邀请部分开发者体验,并逐渐扩大邀请范围。该API的定价为每输 入1000个字符(约合750个单词),价格为0.03美元;GPT-4每生成1000个字符价格为 0.06美元。 Office引入GPT-4带来的结果是生产力、创造力的全面跃升。微软今天宣布,其与 OpenAI共同开发的聊天机器人技术Bing Chat正在GPT-4上运行。
Copilot OpenAI发布升级后的GPT-4后,微软重磅发布了GPT-4平台支持的新AI功能, Microsoft 365 Copilot,并将其嵌入Word、PowerPoint、Excel、Teams等Office办 公软件中。Copilot可以在一篇速记的基础上快速生成新闻草稿、并完成草稿润色; 在Excel中完成各种求和、求平均数,做表格、归纳数据、甚至是完成总结提取;在 PPT上可以直接将文稿内容一键生成;在Outlook邮件中自动生成内容、并自由调整 写作风格、插入图表;在Teams中总结视频会议的要点/每个发言人谁说了核心内容, 跟进会议流程和内容,自动生成会议纪要、要点和任务模板。基于GPT-4的Copilot 可以看作是一个办公AI助理,充分发挥出了AI对于办公场景的赋能作用,有望从根 本上改变工作模式并开启新一轮生产力增长浪潮。
二、GPT-4带动多模态x多场景落地,AIGC蓝海市场打开
(一)历经三阶段发展,AIGC技术升级步入深化阶段
AIGC全程为AI-Generated Content,人工智能生成内容,是继专业生成内容(PGC, Professional Generate Content)和用户生成内容(UGC,User Generate Content) 之后,利用AI自动生成内容的新型生产方式。传统AI大多属于分析式AI,对已有数 据进行分析并应用于相应领域。以AIGC为典型的生成式AI不在局限于分析固有数据, 而是基于训练数据和算法模型自主生成创造新的文本、3D、视频等各种形式的内容。
历经三阶段迭代,AIGC现已进入快速发展阶段: (1)早期萌芽阶段(1950s-1990s),受限于科技水平及高昂的系统成本,AIGC 仅限于小范围实验。 (2)沉淀积累阶段(1990s-2010s),AIGC开始从实验性向实用性逐渐转变。但 由于其受限于算法瓶颈,完成创作能力有限,应用领域仍具有局限性; (3)快速发展阶段(2010s-至今),GAN(Generative Adversarial Network,生成 式对抗网络)等深度学习算法的提出和不断迭代推动了AIGC技术的快速发展,生成 内容更加多元化。
AIGC可分为智能数字内容孪生、智能数字内容编辑及智能数字内容创作三大层次。 生成式AI是指利用现有文本、音频文件或图像创建新内容的人工智能技术,其起源 于分析式AI,在分析式AI总结归纳数据知识的基础上学习数据产生模式,创造出新 的样本内容。在分析式AI的技术基础上,GAN、Transformer网络等多款生成式AI 技术催生出许多AIGC产品,如DALL-E、OpenAI系列等,它们在音频、文本、视觉 上有众多技术应用,并在创作内容的方式上变革演化出三大前沿能力。AIGC根据面 向对象、实现功能的不同可以分为智能数字内容孪生、智能数字内容编辑及智能数 字内容创作三大层次。
(二)生成算法+预训练模型+多模态推动AIGC的爆发
AIGC的爆发离不开其背后的深度学习模型的技术加持,生成算法、预训练和多模态 技术的不断发展帮助了AIGC模型具备通用性强、参数海量、多模态和生成内容高质 量的特质,让AIGC实现从技术提升到技术突破的转变。 (1)生成算法模型不断迭代创新,为AIGC的发展奠定基础。早期人工智能算法学 习能力不强,AIGC技术主要依赖于事先指定的统计模型或任务来完成简单的内容生 成和输出,对客观世界和人类语言文字的感知能力较弱,生成内容刻板且具有局限 性。GAN(Generative Adversarial Network,生成式对抗网络)的提出让AIGC发展 进入新阶段,GAN是早期的生成模型,利用博弈框架产生输出,被广泛应用于生成 图像、视频语音等领域。随后Transformer、扩散模型、深度学习算法模型相继涌现。
Transformer被广泛应用于NLP、CV等领域,GPT-3、LaMDA等预训练模型大多是 基于transformer架构构建的。ChatGPT是基于Transformer架构上的语言模型, Transformer负责调度架构和运算逻辑,进而实现最终计算。Tansformer是谷歌于 2017年《Attention is All You Need》提出的一种深度学习模型架构,其完全基于注 意力机制,可以按照输入数据各部分重要性来分配不同的权重,无需重复和卷积。 相较于循环神经网络(RNN)流水线式的序列计算,Transformer可以一次处理所有 的输入,摆脱了人工标注数据集的缺陷,实现了大规模的并行计算,模型所需的训 练时间明显减少,大规模的AI模型质量更优。
Transformer的核心构成是编码模块和解码模块。GPT使用的是解码模块,通过模 块间彼此大量堆叠的方式形成了GPT模型的底层架构,模块分为前馈神经网络层、 编解码自注意力机制层(Self-Attention)、自注意力机制掩码层。自注意力机制层 负责计算数据在全部内容的权重(即Attention),掩码层帮助模型屏蔽计算位置右 侧未出现的数据,最后把输出的向量结果输入前馈神经网络,完成模型参数计算。
(2)预训练模型引发AIGC技术能力的质变。AI预训练模型是基于大规模宽泛的数 据进行训练后拥有适应广泛下游任务能力的模型,预训练属于迁移学习的领域,其 主旨是使用标注数据前,充分利用大量无标注数据进行训练,模型从中全面学习到 与标注无关的潜在知识,进而使模型灵活变通的完成下游任务。视觉大模型提升 AIGC感知能力,语言大模型增强AIGC认知能力。
NLP模型是一种使用自然语言处理(Natural Language Processing,NLP)技术来解决自然语言相关问题的机器学习模型。在NLP领域,AI大模型可适用于人机语言交互,并进行自然语言处理从实现相应的文本分类、文本生成、语音识别、序列标注、机器翻译等功能。NLP的研究经过了以规则为基础的研究方法和以统计为基础的研究方法的发展,目前以基于Transformer的预训练模型已成为当前NLP领域的研究热点,BERT、GPT等模型均采用这一方法。CV模型指计算机视觉模型,是一种基于图像或视频数据的人工智能模型。常见的CV 模型有采用深度学习的卷积神经网络(CNN)和生成对抗网络(GAN)。
近年来以 视觉Transformer(ViT)为典型的新型神经网络,通过人类先验知识引入网络设计, 使得模型的收敛速度、泛化能力、扩展性及并行性得到飞速提升,通过无监督预训 练和微调学习,在多个计算机视觉任务,如图像分类、目标检测、物体识别、图像 生成等取得显著的进步。
(3)多模态技术拓宽了AIGC技术的应用广度。多模态技术将不同模态(图像、声 音、语言等)融合在预训练模型中,使得预训练模型从单一的NLP、CV发展成音视 频、语言文字、文本图像等多模态、跨模态模型。多模态大模型通过寻找模态数据 之间的关联点,将不同模态的原始数据投射在相似的空间中,让模态之间的信号相 互理解,进而实现模态数据之间的转化和生成。这一技术对AIGC的原创生成能力的 发展起到了重要的支持作用,2021年OpenAI推出AI绘画产品DALL.E可通过输入文 字理解生成符合语义且独一无二的绘画作品,其背后离不开多模态技术的支持。
(三)多模态x多场景落地,AIGC爆发商业潜力
ChatGPT的广泛应用意味着AIGC规模化、商业化的开始。ChatGPT是文字语言模 态AIGC的具体应用,在技术、应用领域和商业化方面和传统AI产品均有所不同。 ChatGPT已经具备了一定的对现实世界内容进行语义理解和属性操控的能力,并可 以对其回以相应的反馈。ChatGPT是AIGC重要的产品化应用,意味着AIGC规模化、 商业化的开始。创新工场董事长兼CEO李开复博士在3月14日表示,ChatGPT快速 普及将进一步引爆AI 2.0商业化。AI 2.0 是绝对不能错过的一次革命。
多家公司正加紧研发ChatGPT类似产品,引爆新一轮科技企业AI军备竞赛。在GPT4 推出之后,Google开放自家的大语言模型API「PaLM API」,此外还发布了一款帮 助开发者快速构建AI程序的工具 MakerSuite。2月底,META公布一款全新的AI大型 语言模型LLaMA,宣称可帮助研究人员降低生成式AI工具可能带来的“偏见、有毒 评论、产生错误信息的可能性”等问题。 AIGC的应用领域分为视频、音频、文本、图像、跨模态生成五个部分。
AIGC以其 真实性、多样性、可控性、组合性的特质,为各行业、各领域提供了更加丰富多元、 动态且可交互的内容。根据AIGC生成内容的模态不同,可将AIGC的应用领域分为 视频、音频、文本、图像、跨模态生成五个部分。其中,在图像、文本、音频等领 域,AIGC已经得到了较大优化,生成内容质量得到明显提升;而在视频与跨模态内 容生成方面,AIGC拥有巨大发展潜力。
三、高算力需求带动基础设施迭代加速
(一)AI大模型驱动高算力需求
数据、算力及模型是人工智能发展的三要素。以GPT系列为例: (1)数据端:自OpenAI于2018年发布GPT-1,到2020年的GPT-3,GPT模型参数 数量和训练数据量实现指数型增长。参数数量从GPT-1的1.17亿增长到GPT-3的 1750亿,训练数据量从5GB增长到的45TB; (2)模型端:ChatGPT在以往模型的基础上,在语料库、计算能力、预训练、自我 学习能力等方面有了明显提升,同时Transformer架构突破了人工标注数据集的不足, 实现与人类更顺畅的交流; (3)算力端:根据OpenAl发布的《Language Models are Few-Shot Learners》, 训练13亿参数的GPT-3 XL模型训练一次消耗的算力约为27.5 PFlop/s-dav,训练 1750亿参数的完整GPT-3模型则会消耗算力3640 PFlop/s-dav(以一万亿次每秒速 度计算,需要3640天完成)。
在人工智能发展的三要素中,数据与算法都离不开算力的支撑。随着AI算法突飞猛 进的发展,越来越多的模型训练需要巨量算力支撑才能快速有效实施,同时数据量 的不断增加也要求算力配套进化。如此看来,算力成为AI突破的关键因素。 AI大模型的算力需求主要来自于预训练、日常运营和模型微调。 (1)预训练:在完成完整训练之前,搭建一个网络模型完成特定任务,在训练网络 过程中不断调整参数,直至网络损失和运行性能达到预期目标,此时可以将训练模 型的参数保存,用于之后执行类似任务。根据中国信通院数据,ChatGPT基于GPT3.5 系列模型,模型参数规模据推测达十亿级别,参照参数规模相近的GPT-3 XL模型, 则ChatGPT完整一次预训练消耗算力约为27.5 PFlop/s-dav。
(2)日常运营:满足用户日常使用数据处理需求。根据Similarweb的数据,23年1月份ChatGPT月活约6.16亿,跳出率13.28%每次访问页数5.85页,假设每页平均200 token。同时假设:模型的FLlops利用率为21.3%与训练期间的GPT-3保持一致;完整参数模型较GPT-3上升至2500亿;以FLOPs为指标,SOTA大型语言在在推理过程中每个token的计算成本约为2N。根据以上数据及假设,每月日常运营消耗算力约为6.16亿*2*(1-13.28%)*5.85*200*2500亿/21.3%=14672PFlop/s-day。(3)模型微调:执行类似任务时,使用先前保存的模型参数作为初始化参数,在训练过程中依据结果不断进行微调,使之适应新的任务。
ChatGPT引发新一轮AI算力需求爆发。根据OpenAI发布的《AI and Compute》分 析报告中指出,自2012年以来,AI训练应用的算力需求每3.4个月就回会翻倍,从 2012年至今,AI算力增长超过了30万倍。据OpenAI报告,ChatGPT的总算力消耗 约为3640PF-days(即假如每秒计算一千万亿次,需要计算3640天),需要7-8个算 力500P的数据中心才能支撑运行。上海新兴信息通信技术应用研究院首席专家贺仁 龙表示,“自2016年阿尔法狗问世,智能算力需求开启爆发态势。如今ChatGPT则 代表新一轮AI算力需求的爆发”。
全球算力规模将呈现高速增长态势。根据国家数据资源调查报告数据,2021年全球 数据总产量67ZB,近三年平均增速超过26%,经中国信息通信研究院测算,2021 年全球计算设备算力总规模达到615EFlops,增速达44%。根据中国信通院援引的 IDC数据,2025年全球算力整体规模将达3300EFlops,2020-2025年的年均复合增 长率达到50.4%。结合华为GIV预测,2030年人类将迎来YB数据时代,全球算力规 模达到56ZFlops,2025-2030年复合增速达到76.2%。
(二)云商/运营商推进AI领域算力基础设施投入
北美云厂商资本支出向技术基础设施和新数据中心架构倾斜。22Q4亚马逊资本支出 主要用于技术基础设施的投资,其中大部分用于支持AWS业务增长与支持履行网络 的额外能力。预计未来相关投资将延续,并增加在技术基础设施方面的支出。谷歌 指引2023年资本开支与2022年基本持平,其中技术基础设施有所增加,而办公基础 设施将减少。Meta2022年资本开支为314.3亿美元,同比增长69.3%,但同时Meta 略微调低其2023年资本开支预期至300-330亿美元(此前预期为340-370亿美元), 主要原因系减少数据中心建设的相关支出,转向新的更具成本效益的、同时支持AI 和非AI工作量的数据中心新架构。
国内三大运营商积极布局算力网络,资本支出向新兴业务倾斜。电信运营商作为数 字基座打造者,运营商数字业务板块成为收入增长的主要引擎,近几年资本支出由 主干网络向新兴业务倾斜。中国移动计划2022年全年算力网络投资480亿元,占其 总资本开支的39.0%。2022Q3,中国移动算力规模达到7.3EFLOPS,并计划在2025 年底达到20EFLOPS以上。中国电信产业数字化资本开支占比同比上升9.3pc,算力 总规模计划由2022年中的3.1EFLOPS提升至2025年底的16.3EFLOPS。中国联通 2022年预计算力网络资本开支达到145亿,同比提升43%,云投资预计提升88%。
作为算力基础设施建设的主力军,三大运营商目前已经进行前瞻性的基础设施布局。 通信运营商自身拥有优质网络、算力、云服务能力的通信运营商,同时具备天然的 产业链优势,依靠5G+AI技术优势,为下游客户提供AI服务能力,是新型信息服务 体系中重要的一环,助力千行百业数字化转型。在移动网络方面,中国运营商已建 设覆盖全国的高性能高可靠4/5G网络;在固定宽带方面,光纤接入(FTTH/O)端 口达到10.25亿个,占比提升至95.7%;在算力网络方面,运营商在资本开支结构上 向算力网络倾斜,提升服务全国算力网络能力。在AI服务能力方面,加快AI领域商 业化应用推出,发挥自身产业链优势,助力千行百业数字化转型。
(三)算力需求带动数据中心架构及技术加速升级
1、数据中心呈现超大规模发展趋势。超大规模数据中心,即Hyperscale Data Center,与传统数据中心的核心区别在于 超大规模数据中心具备更强大的可扩展性及计算能力。1)规模上,超级数据中心可 容纳的规模要比传统数据中心大得多,可以容纳数百万台服务器和更多的虚拟机;2) 性能上,超级数据中心具有更高的可扩展性和计算能力,能够满足数据处理数量和 速率大幅提升的需求。
具体来讲,相较于传统数据中心,超大规模数据中心的优势在于: (1)可扩展性:超大规模数据中心的网络基础架构响应更迅速、扩展更高效且更具 成本效益,并且提供快速扩展存储和计算资源以满足需求的能力,超大规模数据中 心通过在负载均衡器后水平扩展,快速旋转或重新分配额外资源并将其添加到现有 集群,可以实现快速向集群添加额外资源,从而在不中断操作的情况下进行扩展; (2)定制化:超大规模数据中心采用更新的服务器设计,具有更宽的机架,可以容 纳更多组件并且允许定制化设计服务器,使得服务器能够同时接入多个电源和硬盘 驱动器;
(3)自动化服务:超大规模数据中心提供自动化服务,帮助客户管理高流量网站和 需要专门处理的高级工作负载,例如密码学、基因处理和三维渲染; (4)冷却效率更高:超大规模数据中心对其电源架构进行了优化,并将冷却能力集 中在托管高强度工作负载的服务器,大大降低了成本和对环境的影响,电源使用效 率和冷却效率远高于传统数据中心;
(5)工作负载更平衡:超大规模数据中心有效地将工作负载分布在多台服务器上, 从而避免单台服务器过热。避免了过热的服务器损坏附近的服务器,从而产生不必 要的连锁反应。 Statista数据显示,全球超大规模数据中心的数量从2015年的259个,提升到2021年 的700个。根据PrecedenceResearch的报告显示,全球超大规模数据中心市场规模 在2021年为620亿美元,到2030年将达到5930亿美元,预计在2022-2030年间以 28.52%的复合增长率(CAGR)增长。
海内外云商均具备自己的超大规模数据中心。Structure Research在其报告中估计, 到2022年全球超大规模自建数据中心总容量将达到13177兆瓦(MW)。全球四大 超大规模数据中心平台——AWS、谷歌云、Meta和微软Azure——约占该容量的78%。 全球占主导地位的超大规模数据中心企业仍然是亚马逊、谷歌、Meta和微软,在中 国,本土企业阿里巴巴、华为、百度、腾讯和金山云都是领先的超大规模数据中心 企业。
2、IB网络技术将更广泛应用于AI训练超算领域。超级数据中心是具有更大规模和更高计算能力的数据中心。随着对数据处理数量和 速率需求的提升,数据中心的可扩展性需求也在迅速提升。超级数据中心在规模和 性能上较传统数据中心都有了大幅升级,能够满足超高速度扩展以满足超级需求的 能力。
泛AI应用是超算中心的重要下游。自20世纪80年代以来,超级计算主要服务于科研 领域。传统超算基本上都是以国家科研机构为主体的超算中心,如气象预测、地震 预测、航空航天、石油勘探等。截止2022年底,国内已建成10家国家超级计算中心, 不少省份都建立起省级超算中心,服务于当地的中科院、气象局以及地震爆炸模型。 一方面,行业头部企业将超算应用于芯片设计、生物医疗、材料测试等工业应用场 景;另一方面,自动驾驶训练、大语言模型训练、类ChatGPT等AI训练的需求,也 推动超算应用场景延伸至图像识别、视频识别定位、智能驾驶场景模拟以及对话和 客服系统等,成为超算中心的重要下游。
超级数据中心成为算力储备的重要方向,中美加速算力基建布局。凭借其在算力能 力及能耗效率的巨大提升,超级数据中心在算力储备中的地位日渐凸显。根据 Synergy Research Group数据,全球超级数据中心数量从2017年的390个增长至 2021年二季度的659个,增长近一倍,预计2024年总数将超1000个。份额方面,中 美持续加强超级数据中心的布局,占全球市场份额持续提升。
InfiniBand网络满足大带宽和低时延的需求,成为超算中心的主流。InfiniBand(简 称IB)是一个用于高性能计算的计算机网络通信标准,主要应用于大型或超大型数 据中心。IB网络的主要目标是实现高的可靠性、可用性、可扩展性及高性能,且能 在单个或多个互联网络中支持冗余的I/O通道,因此能够保持数据中心在局部故障时 仍能运转。相比传统的以太网络,带宽及时延都有非常明显的优势。(一般InfiniBand 的网卡收发时延在600ns,而以太网上的收发时延在10us左右,英伟达推出的 MetroX-3提升长距离InfiniBand系统带宽至400G)。作为未来算力的基本单元,高 性能的数据中心越来越多的采用InfiniBand网络方案,尤其在超算中心应用最为广 泛,成为AI训练网络的主流。
(四)细分受益环节
GPT-4多模态大模型将引领新一轮AI算力需求的爆发,超大规模数据中心及超算数 据中心作为泛AI领域的重要基础设施支持,其数量、规模都将相应增长,带动整个 算力基础设施产业链(如高端服务器/交换机、CPO技术、硅光、液冷技术)的渗透 加速。同时在应用侧,Copilot的推出加速AI在办公领域的赋能,看好办公场景硬件 配套厂商机会。
1、服务器/交换机: AIGC带动算力爆发式增长,全球进入以数据为关键生产要素的数字经济时代。从国 内三大运营商资本支出结构上看,加码算力基础设施投资成重要趋势。重点推荐: 中兴通讯。公司作为运营商板块算力投资的核心受益标的,持续在服务器及存储、 交换机/路由器、数据中心等算力基础设施领域加强布局,将作为数字经济筑路者充 分受益我国数字经济建设。
算力需求带动上游硬件设备市场规模持续增长,高规格产品占比提升。伴随着数据 流量持续提升,交换机作为数据中心必要设备,预计全球数据中心交换机保持稳定 增长。2021年全球数据中心交换机市场规模为138亿美元,预计到2031年将达246 亿美元,2022年至2031年复合年增长率为5.9%。多元开放的AI服务器架构为可以人 工智能发展提供更高的性能和可扩展性的AI算力支撑,随着AI应用的发展,高性能 服务器数量有望随之增长,带动出货量及服务器单价相应提升。根据IDC报告, 2022Q3,200/400GbE交换机市场收入环比增长25.2%,100GbE交换机收入同比增 长19.8%,高速部分呈现快速增长。
2、光模块/光芯片: 算力需求提升推动算力基础设施升级迭代,传统可插拔光模块技术弊端和瓶颈开始 显现。(1)功耗过高,AI技术的加速落地,使得数据中心面临更大的算力和网络流 量压力,交换机、光模块等网络设备升级的同时,功耗增长过快。以博通交换机芯 片为例,2010年到2022年交换机芯片速率从640G提升到51.2T,光模块速率从10G 迭代到800G。速率提升的同时,交换机芯片功耗提升了约8倍,光模块功耗提升了 26倍,SerDes功耗提升了25倍。(2)交换机端口密度难以继续提升,光模块速率 提升的同时,自身体积也在增大,而交换机光模块端口数量有限。(3)PCB材料遭 遇瓶颈,PCB用于传输高速电信号,传统可插拔光模块信号传输距离长、传输损失 大,更低耗损的可量产PCB材料面临技术难题难以攻克。
NPO/CPO技术有望成为高算力背景下的解决方案。CPO(光电共封装技术)是一 种新型的高密度光组件技术,将交换芯片和光引擎共同装配在同一个Socketed(插 槽)上,形成芯片和模组的共封装。CPO可以取代传统的插拔式光模块技术,将硅 光电组件与电子晶片封装相结合,从而使引擎尽量靠近ASIC,降低SerDes的驱动功 耗成本,减少高速电通道损耗和阻抗不连续性,实现更高密度的高速端口,提升带 宽密度,大幅减少功耗。
CPO技术的特点主要有:(1)CPO技术缩短了交换芯片和光引擎之间的距离(控制在5~7cm),使得高速电信号在两者之间实现高质量传 输,满足系统的误码率(BER)要求;(2)CPO用光纤配线架取代更大体积的可 插拔模块,系统集成度得到提升,实现更高密度的高速端口,提升整机的带宽密度; (3)降低功耗,根据锐捷网络招股说明书,采用CPO技术的设备整机相比于采用可 插拔光模块技术的设备,整机功耗降低23%。
高算力背景下,数据中心网络架构升级带动光模块用量扩张及向更高速率的迭代。 硅光、相干及光电共封装技术(CPO)等具备高成本效益、高能效、低能耗的特点, 被认为是高算力背景下的解决方案。CPO将硅光电组件与电子晶片封装相结合,使 引擎尽量靠近ASIC,减少高速电通道损耗,实现远距离传送。目前,头部网络设备 和芯片厂商已开始布局硅光、CPO相关技术与产品。
3、数据中心: IDC数据中心:“东数西算”工程正式全面启动一周年,从系统布局进入全面建设阶 段。随着全国一体化算力网络国家枢纽节点的部署和“东数西算”工程的推进,算 力集聚效应初步显现,算力向规模化集约化方向加速升级,同时数据中心集中东部 的局得到改善,西部地区对东部地区数据计算需求的支撑作用越发明显。我们认为 政策面推动供给侧不断出清,AI等应用将带动新一轮流量需求,有望打破数据中心 近两年供给过剩的局面,带动数据中心长期发展。
液冷温控:随云计算、AI、超算等应用发展,数据中心机柜平均功率密度数预计将 逐年提升,高密度服务器也将被更广泛的应用于数据中心中。数据中心液冷技术能 够稳定CPU温度、保障CPU在一定范围内进行超频工作不会出现过热故障,有效提 升了服务器的使用效率和稳定性,有助于提高数据中心单位空间的服务器密度,大幅 提升数据中心运算效率,液冷技术有望在超高算力密度场景下持续渗透。
4、运营商: 通信运营商自身拥有优质网络、算力、云服务能力的通信运营商,同时具备天然的 产业链优势,依靠5G+AI技术优势,为下游客户提供AI服务能力,是新型信息服务 体系中重要的一环,助力千行百业数字化转型。作为算力基础设施建设的主力军已 经进行前瞻性的基础设施布局。中国移动打造九天人工智能平台,推进AI商业化, 赋能中国移动内外部数智化转型;中国电信全面布局大模型技术,积极探索产业版 “ChatGPT”的商业化应用;中国联通全力升级算力网络,推动5G和AI技术的融合。
5、企业通信: 3月16日晚微软正式宣布推出Microsoft 365 Copilot,将大型语言模型(LLMs)的能 力嵌入到Office办公套件产品中。基于GPT-4的Copilot以其视频+图文的多模态分析 以及更强大生成与理解能力,可更深度、全面发挥视频会议AI助理功能,比如可以确定目标捕捉发言总结某人谈话要点、全面理解会议主要内容并自动整理及发送会 议纪要等。随着Copilot更强大功能对微软办公套件的加持,有望带动Teams需求的 增长,中国企业通信终端厂商将作为微软重要的硬件合作伙伴有望深度受益。
审核编辑 :李倩
-
GPT
+关注
关注
0文章
354浏览量
15400 -
AI算力
+关注
关注
0文章
72浏览量
8689 -
OpenAI
+关注
关注
9文章
1092浏览量
6537
原文标题:GPT~4引发新一轮AI算力需求爆发
文章出处:【微信号:AIOT大数据,微信公众号:AIOT大数据】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
ChatGPT新增实时搜索与高级语音功能
OpenAI世界最贵大模型:昂贵背后的技术突破
怎样搭建基于 ChatGPT 的聊天系统
ChatGPT 适合哪些行业
如何使用 ChatGPT 进行内容创作
ChatGPT背后的AI背景、技术门道和商业应用






 工商网监
工商网监
评论