 MySQL MHA基本介绍
MySQL MHA基本介绍

******** 摘要********
MySQL是目前主流的关系型数据库管理系统,目前在全球被广泛地应用。由于其开源、体积小、速度快、成本低、安全性高,因此许多网站选择MySQL作为数据库进行存储数据。
****以前在运维数据库过程中经常会遇到这样的困扰:没有工具快速切换集群主库,如果切换主库,需要DBA手动修改从库指向,修改元信息等。所以今天给大家介绍一款工具MHA,可以实现需求快速上线,不影响当前架构,整个切换全部自动化处理,方便DBA使用,例如检查,操作,展示等。
在 MySQL(5.5 及以下)传统复制的时代,MHA(Master High Availability)在 MySQL 高可用应用中非常成熟。在 MySQL(5.6)及 GTID 时代开启以后,MHA 没有随之进行进一步的更新,但是很多互联网公司依然在沿用这个技术。因此本文给出了MHA的简单介绍。
2
MHA简介
【 什么是MHA 】
****MHA目前在MySQL高可用方面是一个相对成熟的解决方案,它由日本DeNA公司youshimaton开发,是一套优秀的作为MySQL高可用性环境下故障切换和主从提升的高可用软件。在MySQL故障切换过程中,MHA能做到在0~30秒之内自动完成数据库的故障切换操作,并且在进行故障切换的过程中,MHA能在最大程度上保证数据的一致性,以达到真正意义上的高可用。
目前MHA主要支持一主多从的架构,在搭建MHA时至少要有一个Master主库和两个Slave从库,MHA架构支持任何存储引擎。
****该软件由两部分组成:MHA Manager(管理节点)和MHA Node(数据节点)。MHA Manager可以单独部署在一台独立的机器上管理多个master-slave集群,也可以部署在一台slave节点上。MHA Node运行在每台MySQL服务器上,MHA Manager会定时探测集群中的master节点,当master出现故障时,它可以自动将最新数据的slave提升为新的master,然后将所有其他的slave重新指向新的master。整个故障转移过程对应用程序完全透明。
【 MHA优势 】
- 不影响服务器性能,易安装,不改变现有部署
- 故障切换(实现自动故障检测和故障转移,通常在30秒以内)
- 数据一致性保证
- 不需要对当前mysql环境做重大修改
- 不需要添加额外的服务器(仅一台manager就可管理上百个replication)
- ****性能优秀,可工作在半同步复制和异步复制,当监控mysql状态时,仅需要每隔N秒向master发送ping包(默认3秒),所以对性能无影响。你可以理解为MHA的性能和简单的主从复制框架性能一样
- ****只要replication支持的存储引擎mha都支持
【 MHA组成 】
MHA软件由两部分组成,Manager工具包和Node工具包,具体的说明如下。
Manager工具包主要包括以下几个工具:
- masterha_check_ssh 检查MHA的SSH配置状况
- masterha_check_repl 检查MySQL复制状况
- masterha_manger 启动MHA
- masterha_check_status 检测当前MHA运行状态
- masterha_master_monitor 检测master是否宕机
- masterha_master_switch 控制故障转移(自动或者手动)
- masterha_conf_host 添加或删除配置的server信息
Node工具包(这些工具通常由MHA Manager的脚本触发,无需人为操作)主要包括以下几个工具:
- save_binary_logs 保存和复制master的二进制日志
- apply_diff_relay_logs 识别差异的中继日志事件并将其差异的事件应用于其他的slave
- filter_mysqlbinlog 去除不必要的ROLLBACK事件
- purge_relay_logs 清除中继日志(不会阻塞SQL线程)
【 MHA版本选择 】
从MHA的0.56版本开始,也支持基于GTID的故障切换。MHA会自动检测mysqld是否在GTID运行,如果GTID开启,MHA就实现带GTID的故障切换,如果没有启用,MHA就使用基于relay log的故障切换。
3MHA实现
【 工作流程 】
- 从宕机崩溃的master保存二进制日志事件(binlog events);
- 识别含有最新更新的slave;
- 应用差异的中继日志(relay log)到其他的slave;
- 应用从master保存的二进制日志事件(binlog events);
- 提升一个slave为新的master;
- 使其他的slave连接新的master进行复制。
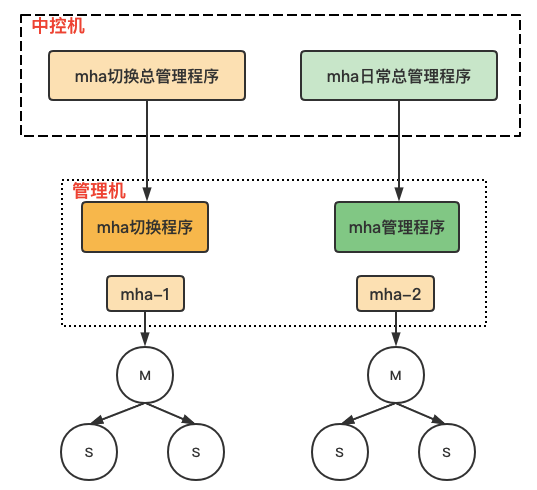
【 MHA架构 】
中控机管理工具,用于管理mha部署、主从切换等;****
****mha管理工具,支持部署、更新配置文件、目录等开关。manager收集切换日志、集群互信、检查ssh、repl状态、配置文件一致性等。
【 核心脚本工作原理介绍 】
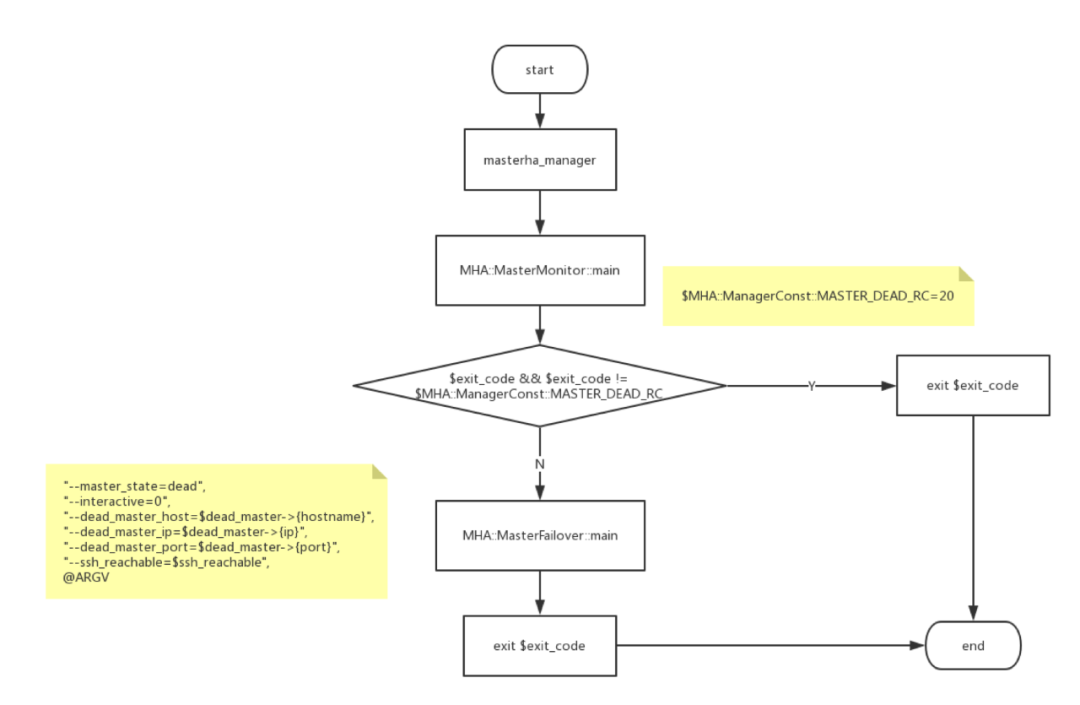
1) masterha_manager
mha启动脚本为masterha_manager,可选参数为remove_dead_master_conf、manger_log、ignore_last_failover。
masterha_manager主要流程为:
1.调用MasterMonitor,监控MySQL master状态;
2.发现master状态异常后,调用MasterFailover进行切换;
3.manager通过monitor监测master状态,一旦获得返回值,则表明monitor状态异常。通过判断exit_code确定是否应切换。
4.检测通过后,调用MasterFailover进执行切换操作。
具体流程如下:
2) MasterMonitor
MasterHA_Manager调用MasterMonitor的main方法对MySQL进行监控。
具体流程图如下:
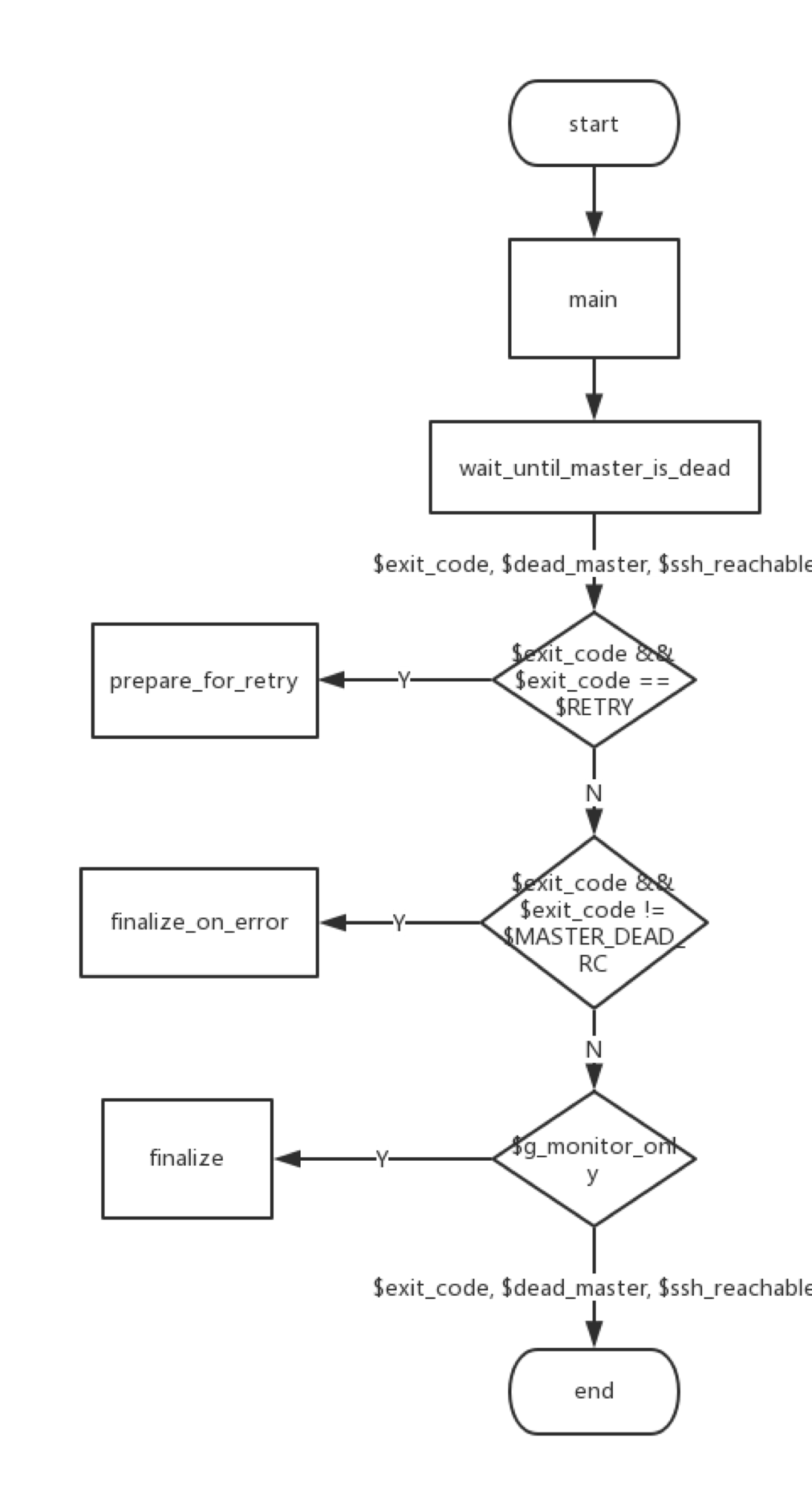
核心方法是一个死循环,不断调用wait_until_master_is_dead方法监测主库状态。wait_until_master_is_dead方法的返回值中,exit_code有的值有四种,分别是0、1、20、retry。其中只有当exit_code=MHA::ManagerConst::MASTER_DEAD_RC,也就是20时,后续才会调用failover方法。
wait_until_master_is_dead方法中,核心方法是调用wait_until_master_is_unreachable方法并处理其返回值。逻辑关系如下:
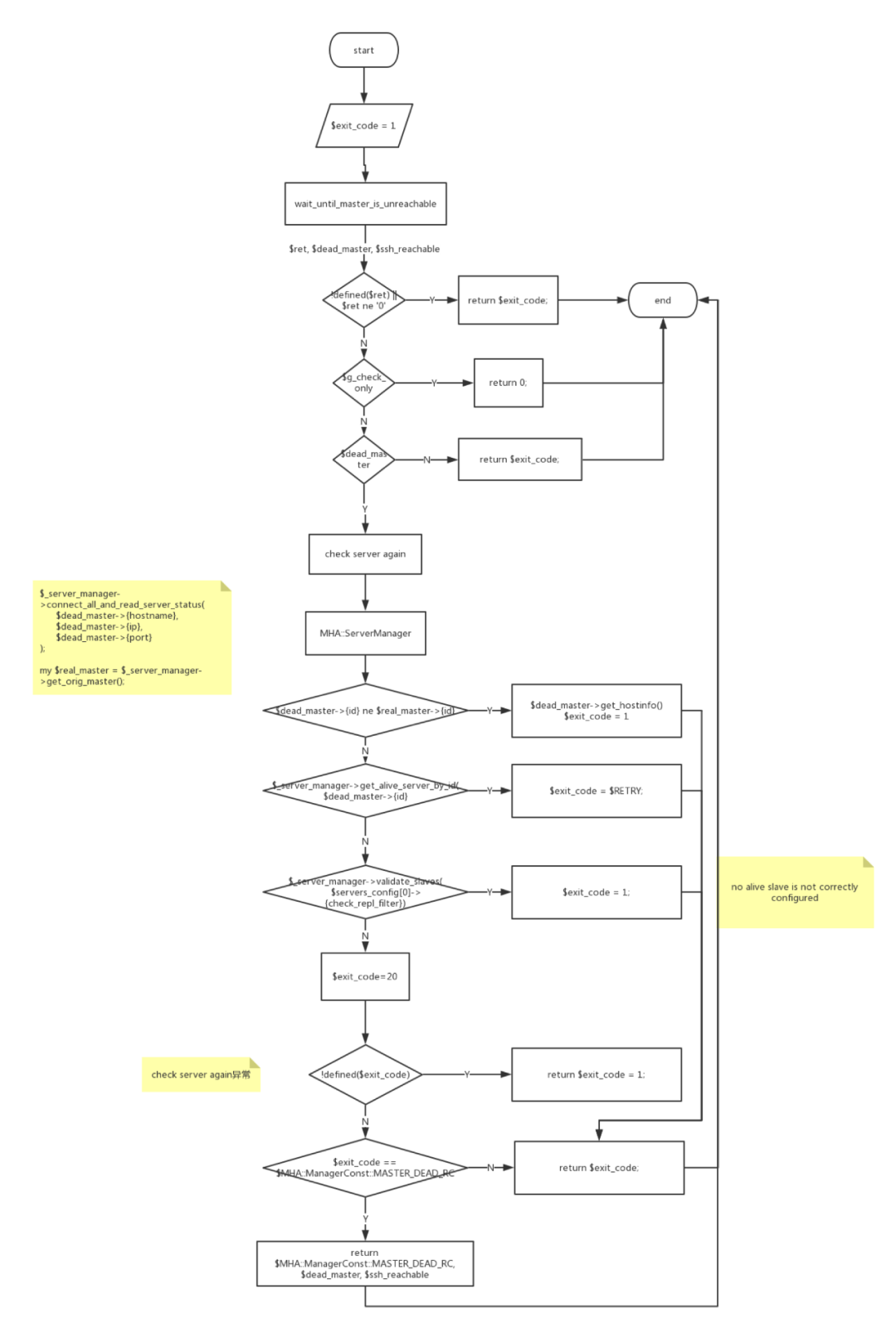
拿到wait_until_master_is_unreachable的返回值后,会再次根据配置文件探活,确认主库连接失败后,根据配置文件检测slave状态和数量,有合适新主库后,exit_code返回20,否则返回0或者1。
wait_until_master_is_unreachable方法的返回值有三个,分别是ret、dead_master和ssh_reachable。该方法的逻辑如下:
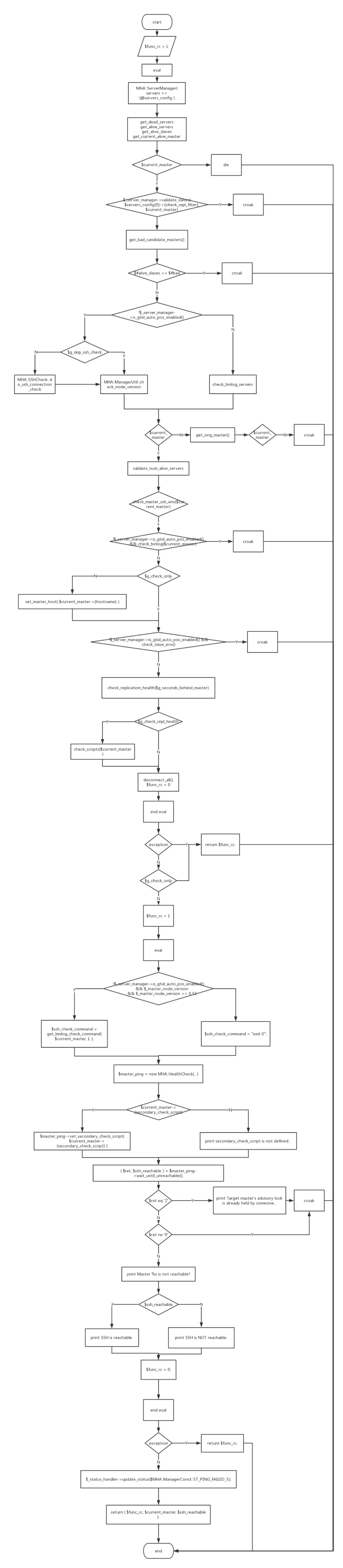
wait_until_master_is_unreachable调用MHA::ServerManager对主库进行实时检测,包括deadservers、aliveservers、aliveslaves等。如果启用GTID,则检查binlog server,否则进行ssh和slave版本检测。
后续使用MHA::HealthCheck对主库进行ping检查。检查确认主库的确不可达后,返回func_rc, current_master, ssh_reachable。
4
总结
MHA 由日本 DeNA 公司 youshimaton 开发,他认为在 GTID 环境下MHA 存在的价值不大,MHA 最近一次发版是 2018 年。现如今使用 MySQL 已离不开 GTID ,无论是从功能、性能角度,还是从维护角度,GTID 能具备更优异的表现。但是无论是什么技术,他的核心原理都是可以自动将最新数据的Slave提升为新的 Master,然后将所有其他的Slave重新指向新的Master。整个故障转移过程对应用程序是完全透明的,因此MHA的时代是值得被大家了解和记忆的。
-
数据库
+关注
关注
7文章
4082浏览量
68530 -
MySQL
+关注
关注
1文章
930浏览量
29744 -
存储数据
+关注
关注
0文章
90浏览量
14490
发布评论请先 登录

恒讯科技解析:如何安装MySQL并创建数据库
REF-MHA50WIMI111T:iMOTION™ 风扇驱动参考设计套件深度解析
工业数据中台支持接入MySQL数据库吗





评论