 Flume的基本架构以及使用案例
Flume的基本架构以及使用案例

在大数据时代背景下,如何采集出有用的信息已经是大数据发展的关键因素之一,数据采集可以说是大数据产业的基石。Flume作为开源的数据采集系统,受到了业界的认可与广泛应用。本文将带你了解Flume的基本架构以及使用案例等。
01
Flume简介
1.1 Flume是什么?
Flume是Apache Software Foundation的顶级项目。它是一个分布式,可靠且可用的系统,主要用于高效地收集,聚合大量日志数据并将其从不同的源移动到集中式数据存储中。
Flume的使用不仅限于日志数据聚合。由于数据源是可定制的,因此Flume可用于传输大量事件数据,包括但不限于网络流量数据,社交媒体数据,电子邮件消息以及几乎所有可能的数据源。
1.2 Flume外部结构
数据发生器产生的数据被所在服务器上的agent收集,之后数据收容器从各个agent上汇集数据并将采集到的数据存入到HDFS或者HBase中。同时,Flume还有如下特点:
- 使用Flume,我们可以将多个服务器中获取的数据迅速的移交给Hadoop中;
- 支持各种接入数据的类型以及接出数据类型;
- 支持多路径流量,多管道接入流量,多管道接出流量,上下文路由等;
- 支持水平扩展。
02
Flume的一些核心概念
Client:客户端,生产数据,运行在一个独立的线程。
Event:事件,是一个数据单元,由消息头和消息体组成。
Agent:一个独立的Flume进程,包含组件Source、 Channel、 Sink。
Source:数据的收集端,负责将数据捕获后进行特殊的格式化,将数据封装到Event里,然后推入Channel中。
Channel:中转Event的一个临时存储,保存由Source组件传递过来的Event。
Sink:从Channel中读取并移除Event, 将Event传递到下一个Agent。
2.1 Flume Agent结构
Flume内部有一个或者多个Agent,它是Flume 运行的核心。然而对于每一个Agent来说,它就是一个独立的守护进程(JVM),它从客户端或者其他的 Agent接收数据,然后迅速的传给下一个目的节点Sink,或者Agent。
Flume以Agent为最小的独立运行单位。它是一个完整的数据收集工具,含有三个核心组件,分别是Source、 Channel、 Sink。其工作流程为:把数据从数据源(Source)收集过来,在将收集到的数据送到指定的目的地(Sink)。为了保证输送的过程一定成功,在送到目的地之前,会先缓存数据(Channel),待数据真正到达目的地(Sink)后,Flume再删除缓存的数据。
2.2 Source
Source 负责数据的产生或搜集,并将数据捕获后进行特殊的格式化,封装到Event,然后再推入Channel。一般是对接一些RPC的程序或者是其他的Flume节点的Sink,从数据发生器接收数据,并将接收的数据以Event格式传递给一个或者多个通道Channel,Flume提供多种数据接收的方式,比如avro、thrift、netcat、sequence generator、syslog、http等,如果内置的Source无法满足需要, Flume还支持自定义。
2.3Channel
Channel 是一种短暂的存储容器,负责数据的存储持久化,可以持久化到jdbc,file,memory,将从Source接收到的Event格式的数据缓存起来,直到它们被Sink消费掉,可以把Channel看成是一个队列,队列的优点是先进先出,放好后尾部一个个Event出来,Flume比较看重数据的传输,因此几乎没有数据的解析预处理。仅仅是数据的产生,封装成Event然后传输。数据只有存储在下一个存储位置,数据才会从当前的Channel中删除。这个过程是通过事务来控制的,这样就保证了数据的可靠性。
不过Flume的持久化也是有容量限制的,比如内存如果超过一定的量,不够分配,也一样会爆掉。
2.4 Sink
Sink负责数据的转发,将数据存储到集中存储器比如Hbase和HDFS,它从Channel消费数据并将其传递给目标地。目标地可能是另一个Sink,也可能是hdfs、logger、avro、thrift、file、Hbase、solr或者自定义等。
Sink从Channel中取出事件,然后将数据发到别处,可以向文件系统、数据库、 hadoop存数据, 也可以是其他agent的Source。在日志数据较少时,可以将数据存储在文件系统中,并且设定一定的时间间隔保存数据。
Sink支持设置存储数据位置,在日志数据较少时,可以将数据存储在文件系中,并且设定一定的时间间隔保存数据。在日志数据较多时,可以将相应的日志数据存储到Hadoop中,便于日后进行相应的数据分析。
2.5 Event
Flume使用Event对象作为传递数据的格式,特点如下:
① Event将传输的数据进行封装,是Flume传输数据的基本单位,如果是文本文件,通常是一行记录。
② Event也是事务的基本单位。
③ Event从Source,流向Channel,再到Sink,本身为一个字节数组,并可携带headers(头信息)信息。
④ Event代表着一个数据的最小完整单元,从外部数据源来,向外部的目的地去。
一个完整的Event包括:headers、body、Event信息(即文本文件中的单行记录)。其中body是一个字节数组,包含了实际的内容,如下图所示:

03
Flume拦截器、数据流以及可靠性
3.1 Flume拦截器
当我们需要对数据进行过滤时,除了在Source、 Channel和Sink进行代码修改之外, Flume为我们提供了拦截器,位于Source和Channel之间,在日志进入到Source之前,对日志进行一些包装、清洗过滤等动作。
当我们为Source指定拦截器后,会在其中得到Event,根据需求我们可以对Event进行保留还是抛弃,抛弃的数据不会进入Channel中。
3.2 Flume数据流
Flume 的核心是把数据从数据源收集过来,再送到目的地。为了保证输送成功,在送到目的地之前,会先缓存数据,待数据真正到达目的地后,删除缓存的数据。
Flume 传输数据的基本单位是 Event,如果是文本文件,通常是一行记录。Event 从 Source,流向 Channel,再到Sink,本身为一个byte数组,并可携带 headers 信息。Event 代表着一个数据流的最小完整单元,从外部数据源来,向外部的目的地去。
值得注意的是,Flume提供了大量内置的Source、Channel和Sink类型。不同类型之间可以自由组合。组合方式基于用户设置的配置文件,非常灵活。比如:Channel可以把事件暂存在内存里,也可以持久化到本地硬盘上。Sink可以把日志写入HDFS、HBase或其它Source等。Flume支持用户建立多级流,也就是说,多个agent可以协同工作,这也是Flume强大之处。
3.3 Flume可靠性
Flume可以通过以下方式保证其可靠性:
① Flume保证单次跳转可靠性的方式:传送完成后,该事件才会从通道中移除;
② Flume使用事务性的方法来保证事件交互的可靠性;
③ Flume可以将数据可暂存,当目标不可访问后,数据会暂存在Channel中,等目标可访问之后,再进行传输;
④ 数据处理过程中,如果因为网络中断或者其他原因,在某一步被迫结束了,这个数据会在下一次重新传输;
⑤ Source和Sink封装在一个事务的存储和检索中,即事件的放置或者提供由一个事务通过通道来分别提供,保证了事件集在流中可靠地进行端到端的传递。
04
Flume使用场景****
Flume在英文中的意思是水道,它更像是可以随意组装的消防水管,下面根据官方文档,展示几种Flow。
4.1 单个agent采集数据
单个Agent收集数据源,存储到最终的外部系统中,这是最简单的情况。
4.2 多个agent顺序连接

多个Agent顺序连接起来,将最初的数据源经过收集,最终存储到外部系统中。一般情况下,应该控制这种顺序连接的Agent 的数量,因为数据流经的路径变长了,如果出现故障将影响整个服务。
4.3 多个Agent数据汇集

日志收集中的一个非常常见的情况是,大量的日志生成客户端将数据发送到连接存储子系统的使用方代理。例如,从数百台Web服务器收集的日志发送到多个写入HDFS群集的代理。
这可以在Flume中实现,方法是为多个第一层代理配置一个avro接收器,它们均指向单个代理的avro源。第二层代理上的此源将接收到的事件合并到一个通道中,该通道由接收器消耗到其最终目地的。
4.4 多级流
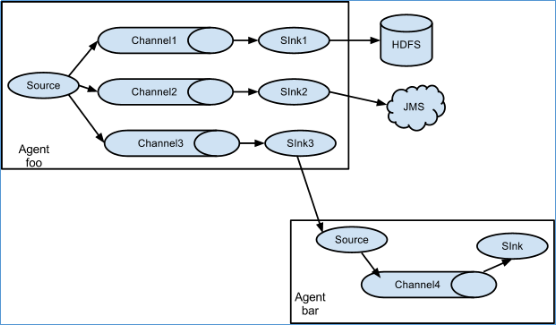
Flume支持多级流,那么什么是多级流呢?我们举个例子,当syslog, java, nginx、 tomcat等混合在一起的日志流开始流入一个agent后,可以在agent中将混杂的日志流分开,然后给每种日志建立一个自己的传输通道。
上面的示例显示了来自代理“ foo”的源,将流扩展到三个不同的通道。
值得注意的是,当多个agent级联时,一个Source可以对接多个chanel,但是一个chanel只能对接一个Sink。
05
Flume优缺点
5.1 优点
① Flume可以将应用产生的数据存储到多种集中存储器;
② Flume提供上下文路由特征;
③ Flume的管道是基于事务,保证了数据在传送和接收时的一致性;
④ Flume是可靠的,容错性高的,可升级的,易管理的,并且可定制的;
⑤ Flume可以实时的将分析数据并将数据保存在数据库或者其他系统中;
⑥ 当收集数据的速度超过将写入数据的时候,也就是当收集信息遇到峰值时,收集的信息非常大,甚至超过了系统的写入数据能力,这时候,Flume会在数据生产者和数据收容器间做出调整,保证其能够在两者之间提供一个平稳的数据。
5.2 缺点
Flume的配置比较繁琐,Source,Channel,Sink的关系在配置文件里面交织在一起,不便于管理。
-
数据采集
+关注
关注
42文章
8378浏览量
121327 -
大数据
+关注
关注
64文章
9107浏览量
144139
发布评论请先 登录
运动控制系统基本架构及控制轨迹要点简述
flume原理介绍
LabVIEW串行通讯的基本架构
TFT基本架构及原理

详解SOA五种基本架构模式





评论