 C/C++之函数体hack(上)
C/C++之函数体hack(上)
前言
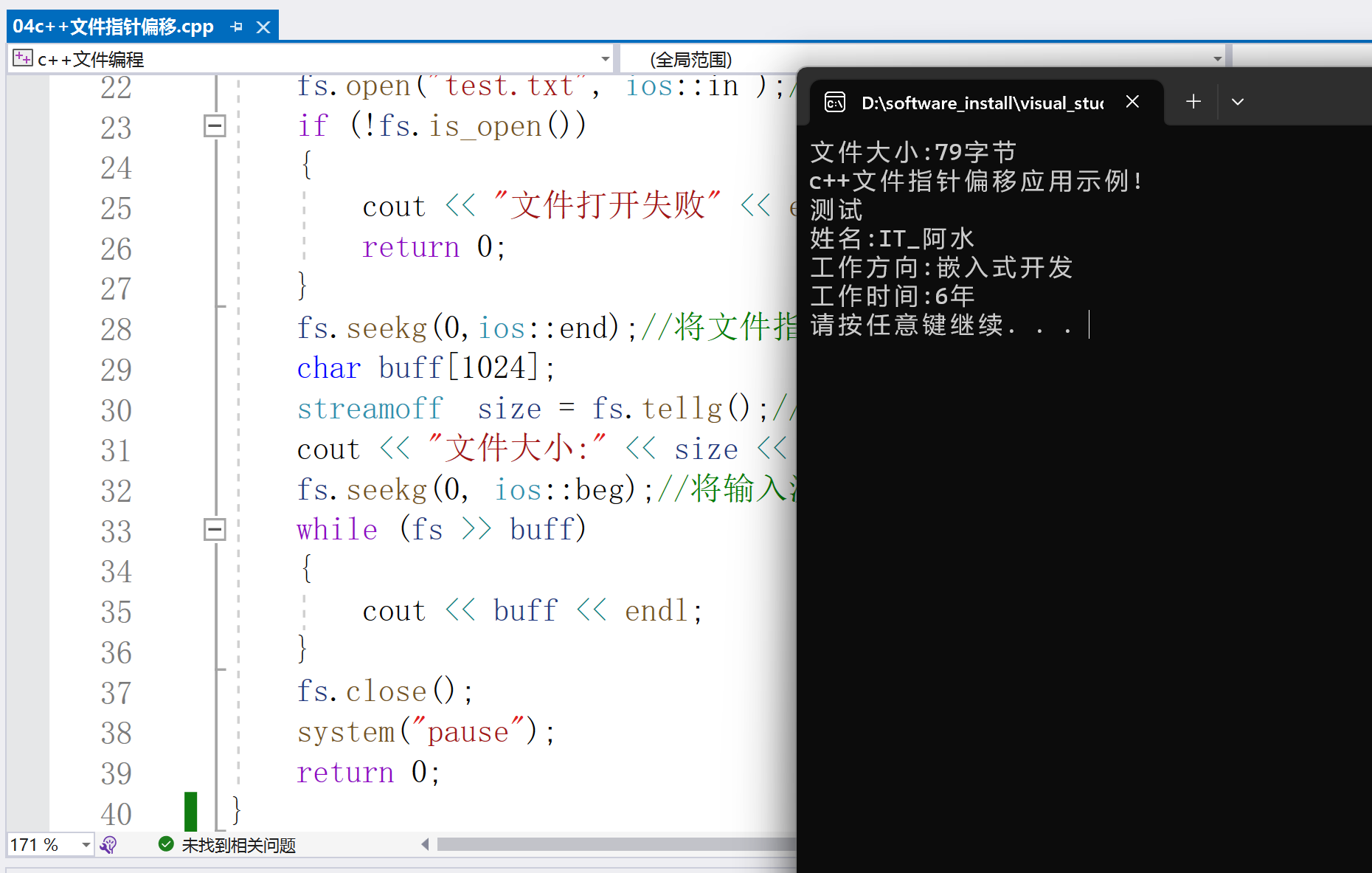
首先来说下 什么是hack ? hack字面意思“ 非法入侵 ”,那么在C/C++中其实就是 使用反汇编查看C/C++代码对应的汇编代码 。
那可能有人要问了,C/C++不是高级语言么,为什么还要看汇编代码?理由嘛见仁见智,
个人理解有下面几种:
- 1.C/C/C++应用不像java,python那样,报错信息可以在日志中一目了然,C/C++应用的报错可以让你查的怀疑人生,为什么呢?因为 报错日志提供的信息可能会误导你 ,比如真实错误是在100行,但是报错信息会在第一行或者全局都有报错,就很让人上头。。有了这个hack过程,就可以定位到可能报错的地方,使用hack反编译得到汇编代码,汇编代码可以让你看清你写的C/C/C++代码对于CPU来说实际执行的行为。
- 2.当我们在调试C/C++应用的时候,经常会 有些疑惑 ,比如i++和++i为什么结果不同,又比如inline内联函数有什么用处?原理是什么?等等,这些也可以使用hack来解释,那有人要说了,这些我都知道啥意思啊,i++和++i前自增和后自增么,内联函数原理就是编译期将函数代码拷贝到调用处嘛。可是这些都是别人告诉你的,那如果一个代码段别人没告诉你呢?百度是不是什么都可以找到的,特别是对于C/C++开发来说,信息更是少的可怜,此时你就会知道hack是多重要了。
- 3.如果你的C/C++应用需要实现一些性 能上优化 ,也可以使用hack过程查看CPU和内存的行为,从而对应用性能做一些提升,是不是很cool。。
既然有这么多用处,那么下面小余就来讲解下如何在我们的应用中hack。
不过在hack前我们需要了解一些汇编语言基础。
汇编语言基础
首先我们得了解汇编语言中的几个模块:1.寄存器 2.内存 3.CPU
1.寄存器
寄存器是我们计算机中的最小存储单位,在计算机金字塔的顶端, 属于CPU的内部存储 ,主要用来存储CPU需要使用到的临时数据。
CPU访问寄存器的速度比访问内存的速度快了100倍左右。
CPU中寄存器种类包括:通用寄存器,指令地址寄存器,状态寄存器等等等等。。 这里只介绍几个比较关键的寄存器:
1.通用寄存器
| 寄存器 | 原文 | 解释 | 说明 |
|---|---|---|---|
| AX | accumulator | 累加寄存器 | 通常用来执行加法,函数调用的返回值一般也放在这里面 |
| CX | counter | 计数寄存器 | 通常用来作为计数器,比如for循环 |
| DX | data | 数据寄存器 | 数据存取 |
| BX | base | 基址寄存器 | 读写I/O端口时,edx用来存放端口号 |
| SP | stack pointer | 栈指针寄存器 | 栈顶指针,指向栈的顶部 |
| BP | base pointer | 基址指针寄存器 | 栈底指针,指向栈的底部,通常用ebp+偏移量的形式来定位函数存放在栈中的局部变量 |
| SI | source index | 源变址寄存器 | 字符串操作时,用于存放数据源的地址 |
| DI | destination index | 目标变址寄存器 | 字符串操作时,用于存放目的地址的,和esi两个经常搭配一起使用,执行字符串的复制等操作 |
这里说明几点:
- 1.在具体hack的过程中你可能看到的是eax,ecx,edx等而不是AX,CX,DX,他们区别: 带e开头的说明是32位寄存器,也就是4个字节存储的寄存器,而AX是eax的低16位的“子寄存器”, 这是早期一些寄存器是16位的,而为了兼容早期这些寄存器就使用“子寄存器”来标识。
- 2.汇编语言中,在函数体返回时,统一使用eax为返回值,这个为什么这样?我也不清楚,可能是早期大家都这么用就约定下来了吧。
- 3.当我们在使用函数的时候,会将ebp的内容压入栈底,作为栈底指针,指向栈的底部,局部变量使用ebp+偏移地址来定位。对于栈顶则使用esp寄存器来定位,关于函数栈会在后面讲解。
2.eip寄存器
eip寄存器可以说是CPU中最关键的一个寄存器了,它指向了下一条要执行的指令所存放的地址, CPU工作其实就是取出eip中的地址中的指令,然后去执行这条指令,并将下一条指令的地址赋值给eip ,这样CPU就可以依次执行完成所有的汇编代码.
如果你要问我它是怎么找到下一条指令的地址的,首先正常执行指令是+1位下一条指令地址,如果碰到一些比如if语句,函数调用等情况,就会在上一条指令中得到这个地址,并赋值给eip,这个赋值动作是CPU自动完成的,开发是不能随便更改的,这也变相的防止你搞出bug不是?
3.状态寄存器
状态寄存器中记录了CPU执行过程中的一系列状态,对于32位就有32个标志位,这些标志大部分都是由CPU自行设置:
| 寄存器标志位 | 解释 |
|---|---|
| CF | 进位标志 |
| PF | 奇偶标志 |
| ZF | 零标志 |
| SF | 符号标志 |
| OF | 补码溢出标志 |
| TF | 跟踪标志 |
| IF | 中断标志 |
| …… |

4.指令寄存器:
根据指令在存贮器中的地址(由指令地址计数器给出),把指令从存贮器中取出来之后,需要有一个专门用于存放指令的地方,以便对指令进行分析和执行。 这个专门存放现行指令的部件就叫做指令寄存器 。
后面会具体汇编代码会涉及到。
关于寄存器就讲这么几个吧,hack过程够用了。
2.内存
这里讲解的内存一般是指高速缓存(Cache)或者主存。
计算机在运行程序时,首先将程序从磁盘读取到主存,然后CPU按规则从主存中取出指令,数据并执行指令,但是直接从主存(一般是DRAM)中读写是很慢的,所以引入了高速缓存(Cache)(使用的是SRAM)。
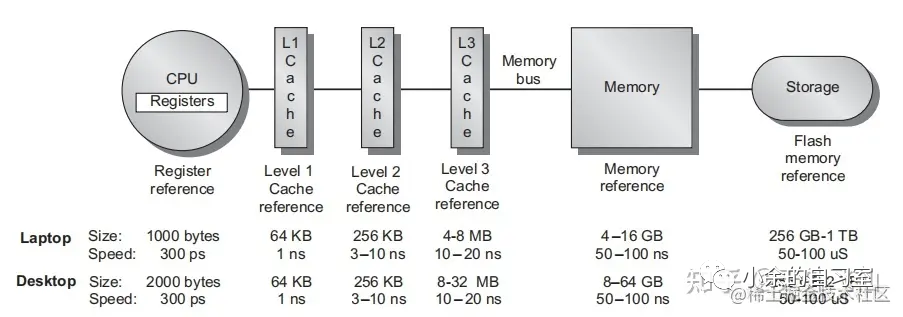
在程序运行前首先会试图将指令,数据从主存中读取到Cache中,然后在程序执行时直接访问Cache, 如果指令和数据可以从Cache中读取到,那么就说是“命中(hit)”,反之就是“不命中(miss)”, miss情况下需要从主存中读取指令或者数据,这样会直接影响CPU的性能,所以命中率对CPU来说至关重要。
内存在计算中又会分为:堆区,栈区,全局(静态)区,常量区,代码区等等。
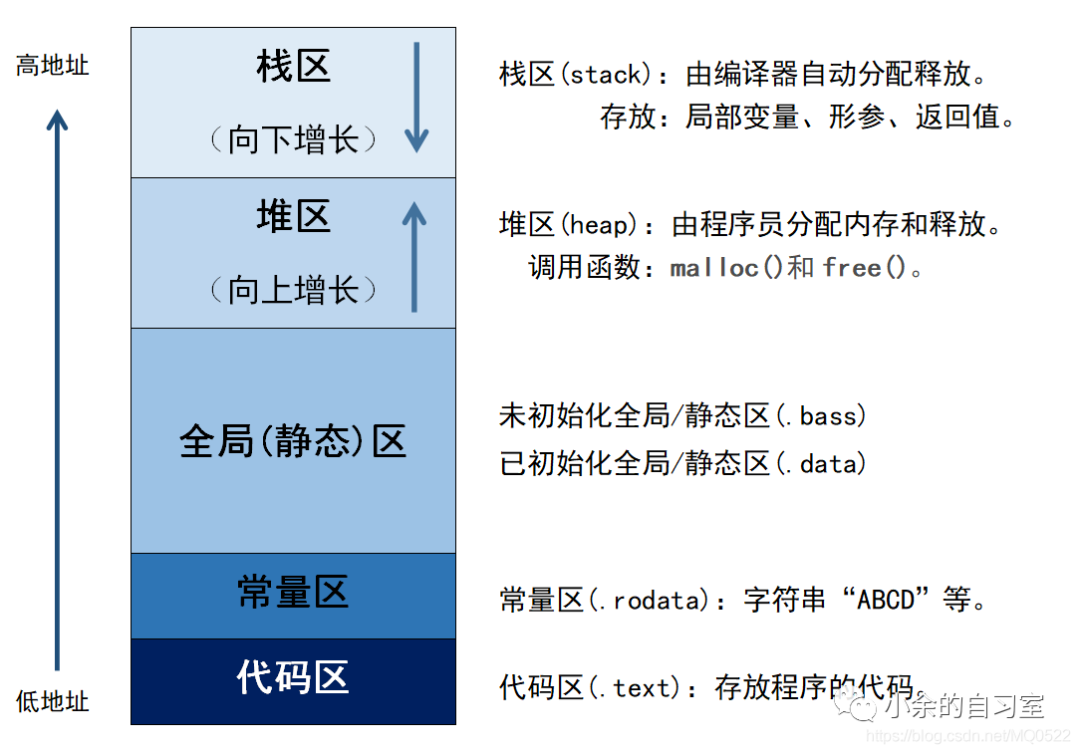
这里讲解下hack中比较关键的栈区。
栈区
- 栈中存放了局部变量,参数,函数的返回地址等
- 栈区由编译器自动分配释放,由操作系统自动管理,无须手动管理
- 栈区中的局部变量只在该函数作用域中有效,函数退出后就会被销毁、
栈区就像一个桶一样,桶底就是栈底为高地址区,桶的顶部为低地址, 桶中放东西当然是先放桶底然后依次叠加咯,也就是平时所说的FILO先进后出的模式。

3.CPU
1.CPU的功能
指令控制(程序的顺序控制)
操作控制(一条指令由若干操作信号实现)
时间控制(指令各个操作实施时间的定时)
数据加工(算术运算和逻辑运算)
2.CPU的基本组成
中央处理器 CPU= 运算器 + 控制器
运算器:
ALU
累加器
暂存器
控制器
程序计数器 (PC) 、指令寄存器 (IR) 、数据缓冲器 (DR) 、地址寄存器 (AR) 、通用寄存器、状态寄存器 (PSW) 、时序发生器、指令译码器 (ID) 、总线

CPU的工作分为以下 5 个阶段:取指令阶段、指令译码阶段、执行指令阶段、访存取数和结果写回。
- 取指令 (IF,instruction fetch),即将一条指令从主存储器中取到指令寄存器的过程。程序计数器中的数值,用来指示当前指令在主存中的位置。当 一条指令被取出后,程序计数器(PC)中的数值将根据指令字长度自动递增。
- 指令译码阶段 (ID,instruction decode),取出指令后,指令译码器按照预定的指令格式,对取回的指令进行拆分和解释,识别区分出不同的指令类 别以及各种获取操作数的方法。现代CISC处理器会将拆分已提高并行率和效率
- 执行指令阶段 (EX,execute),具体实现指令的功能。CPU的不同部分被连接起来,以执行所需的操作。
- 访存取数阶段 (MEM,memory),根据指令需要访问主存、读取操作数,CPU得到操作数在主存中的地址,并从主存中读取该操作数用于运算。部分指令不需要访问主存,则可以跳过该阶段。
- 结果写回阶段 (WB,write back),作为最后一个阶段,结果写回阶段把执行指令阶段的运行结果数据“写回”到某种存储形式。结果数据一般会被写到CPU的内部寄存器中,以便被后续的指令快速地存取;许多指令还会改变程序状态字寄存器中标志位的状态,这些标志位标识着不同的操作结果,可被用来影响程序的动作。 在指令执行完毕、结果数据写回之后,若无意外事件(如结果溢出等)发生,计算机就从程序计数器中取得下一条指令地址,开始新一轮的循环,下一个指令周期将顺序取出下一条指令。 [1] 许多复杂的CPU可以一次提取多个指令、解码,并且同时执行。
一些基础的汇编命令:
1.数据传送指令
-
1.mov :传送指令,也可以单纯理解为赋值语句,这个语句在汇编中是最常用的。 格式:mov det,src
首先mov语句分以下几种情况:
- 1.CPU内部寄存器之间数据传送:mov ebp,esp ,将esp寄存器中的数据传递给ebp寄存器。
- 2.立即数传递到通用寄存器:mov ebp 3 ,将立即数3传递到ebp寄存器中。
- 3.立即数传递到内存存储单元:mov [bx] 123h,将立即数传递到bx指向的内存地址中。
- 4.内存和CPU之间数据传送:内存传递到CPU寄存器中:mov eax,dword ptr [a] ,CPU寄存器传递到内存中:mov dword ptr [a],eax。
2.加减运算指令
首先要了解,加减法运算是会改变状态寄存器中的值的,如一个有符号数的运算高位溢出标志(OF),无符号的运算进位标志(CF)等。
加法指令:add、adc、inc
- 1.add
格式:add OPRD1,OPRD2 功能:OPRD1 = OPRD1 + OPRD2 举例: add eax ecx;//得到的结果为eax = eax+ecx; - 2.adc
格式:add OPRD1,OPRD2 功能:OPRD1 = OPRD1 + OPRD2 举例: adc eax ecx;得到的结果为eax = eax+ecx+状态寄存器中给的进位标志CF; - 3.inc
格式:add OPRD 功能:OPRD = OPRD + 1 举例: inc eax;//得到的结果为eax = eax+1;
减法指令:sub,dec,cmp,当然还有和adc对应的sbb 这里讲解下sub和dec
- 1.sub
格式:sub OPRD1,OPRD2 功能:OPRD1 = OPRD1 - OPRD2 举例: sub eax ecx;//得到的结果为eax = eax - ecx; - 2.dec
格式:dec OPRD 功能:OPRD = OPRD - 1 举例: dec eax;//得到的结果为eax = eax - 1; - 3.cmp
格式:cmp OPRD1,OPRD2 功能:执行OPRD1 - OPRD2,但运算结果不运送到OPRD1 注:该指令通过OPRD - OPRD2影响标志位CF、ZF、SF、OF、AF、PF来判断OPRD1和OPRD2的大小关系。 通过ZF判断是否相等;如果是无符号数,通过CF可判断大小;如果是有符号数,通过SF和OF判断大小
3.逻辑运算和移位指令
1、逻辑运算指令:not、and、or、xor、test
- (1) NOT:非运算
格式:NOT OPRD 功能:把操作数OPRD取反,然后送回OPRD。 注: OPRD可以是通用寄存器,也可以是存储器操作数,此指令对标志没有影响 - (2) AND:与运算
格式:AND OPRD1,OPRD2 功能:对两个操作数进行按位逻辑“与”运算,结果送到OPRD1中 注: 该指令执行后,CF=0,OF=0,标志PF、ZF、SF反映运算结果,AF未定义。 某个操作数与自身相与,值不变,但可以使CF置0。 - (3) OR:或运算
格式:OR OPRD1,OPRD2 功能:对两个操作数进行按位逻辑“或”运算,结果送到OPRD1中 注: 该指令执行后,CF=0,OF=0,标志PF、ZF、SF反映运算结果,AF未定义。 某个操作数与自身相或,值不变,但可以使CF置0。 - (4) XOR:异或运算
格式:XOR OPRD1,OPRD2 功能:对两个操作数进行按位逻辑“异或”运算,结果送到OPRD1中
2、一般移位指令:SAL/SHL,SAR/SHR
- (1) SAL/SHL(Shift Arithmetic Left / Shift Logic Left);算术左移/逻辑左移
格式:SAL OPRD,m SHL OPRD,m 功能:把操作数OPRD左移m位,每移动一位,右边用0补足1位,移出的最高位进入标志位CF 注: 算术左移和逻辑左移进行相同的动作,为了方便提供了两个助记符。 - (2) SAR(Shift Arithmetic Right) ;算数右移指令
格式:SAR OPRD,m 功能:操作数右移m位,同时每移1位,左边的符号位保持不变,移出的最低位进入标志位CF 注: 对有符号数和无符号数,算数右移1位相当于除以2 如:SAR BH,1 ;(BH)= 80H,指令执行后(BH)= C0H - (3) SHR(Shift Logic Right) ;逻辑右移指令
格式:SHR OPRD,m 功能:操作数右移m位,同时每移1位,左边用0补足,移出的最低位进入标志位CF 注: 对无符号数,逻辑右移1位相当于除以2 如:SHR AH,1 ;(AH)= 80H,指令执行后(AH)= 40H
切记:算术移位和逻辑移位的区别:
对于左移不管是算术移位和逻辑移位,低位都补0; 对于右移的算术移位:对于有符号数,符号位不变,然后整体右移。
4.转移指令
1、无条件转移指令:JMP(Jump)
直接跳转到Jump指定的地址, 跳转指令也是改变当前eip的值来决定的 ,这样下次取指令会去新的eip地址下取。
格式:JMP OPRD
功能:使控制指令无条件转移到OPRD的内容给定的目标地址处。操作数OPRD可以是通用寄存器,也可以是字存储单元
例如:
jmp cx ;CX寄存器的内容送IP
jmp word ptr [1234h] ;字存储单元[1234h]的内容送IP
-
C++
+关注
关注
22文章
2108浏览量
73618 -
汇编代码
+关注
关注
0文章
23浏览量
7548 -
hacker
+关注
关注
0文章
4浏览量
1361
发布评论请先 登录
相关推荐
C++课程资料详细资料合集包括了:面向对象程序设计与C++,算法,函数等
如何在中断C函数中调用C++


C++基础语法之inline 内联函数
深度解析C++中的虚函数





 工商网监
工商网监
评论