 字节跳动在令牌桶限速器优化上的实践
字节跳动在令牌桶限速器优化上的实践
限速器(rate limiter)是一个非常基础的网络包处理功能,被广泛应用于各类网元设备,在流量调度、网络安全等领域发挥着重要作用。常见的限速器的实现方式基于令牌桶(token bucket),尽管令牌桶的原理已经被人熟知,在具体实践中,我们也发现了一些挑战和共性问题。本文总结了近两年字节跳动系统与技术工程团队(简称 STE 团队)在限速器优化方面的一些探索,将一些经验和教训总结出来,以飨读者。
令牌桶限速器的基本原理
相信每个写网络包处理的工程师都写过基本的令牌桶限速器。令牌桶是一个形象的描述,既可以想象有一个桶可以容纳一定量的令牌(token),每放行一个数据包便消耗一定量的令牌,数据包的放行与否取决于令牌桶中的令牌个数。
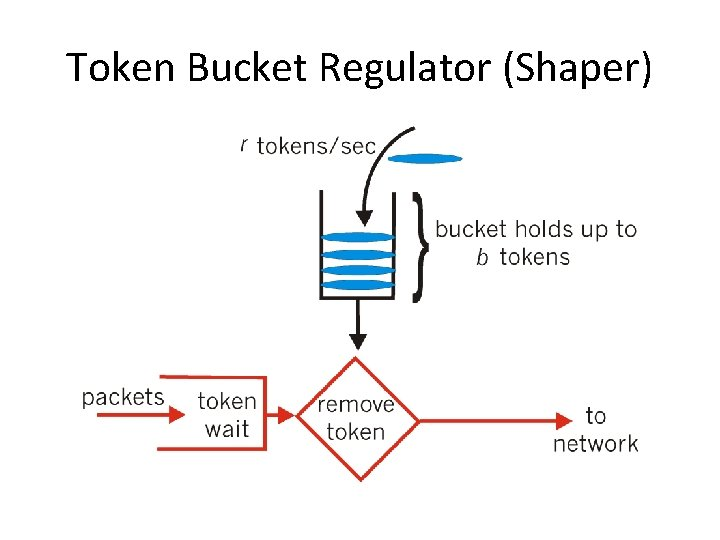
图1 令牌桶图示

在具体实践中,令牌桶具有实现简单、效率高等特点,在很多场景下,提到限速器,基本是令牌桶的代名词。
存在的问题
在具体工程时间中,我们遇到了以下三个问题:
1. 精度问题
实际工程实践中,时间计量单位其实是受限于系统,比如时间戳可能是以微秒(us)为单位,而每次计算的时间差可能只有 1~2us。那么一个 PPS=300K 的限速器,可能一次计算,所产生的令牌是 0.3 个,容易被整数运算忽略。最终的结果则是,实际限制为 300K/s,最后效果是只有 250Kpps 流量放行。精度过低,效果不理想。
这种解决方式也比较简单,可以让一个数据包消耗的令牌量不是 1个,而是 1000个。这样,即使 1us,令牌桶产生的令牌数是 300个,而非 0.3个,这样便保证了精度。但此时又引入了新的问题,因为令牌数扩大了 1000 倍,此时需要考虑令牌桶的深度是否会溢出 32bit。一旦溢出,则会出现其他诡异的问题。
2. 级联补偿问题
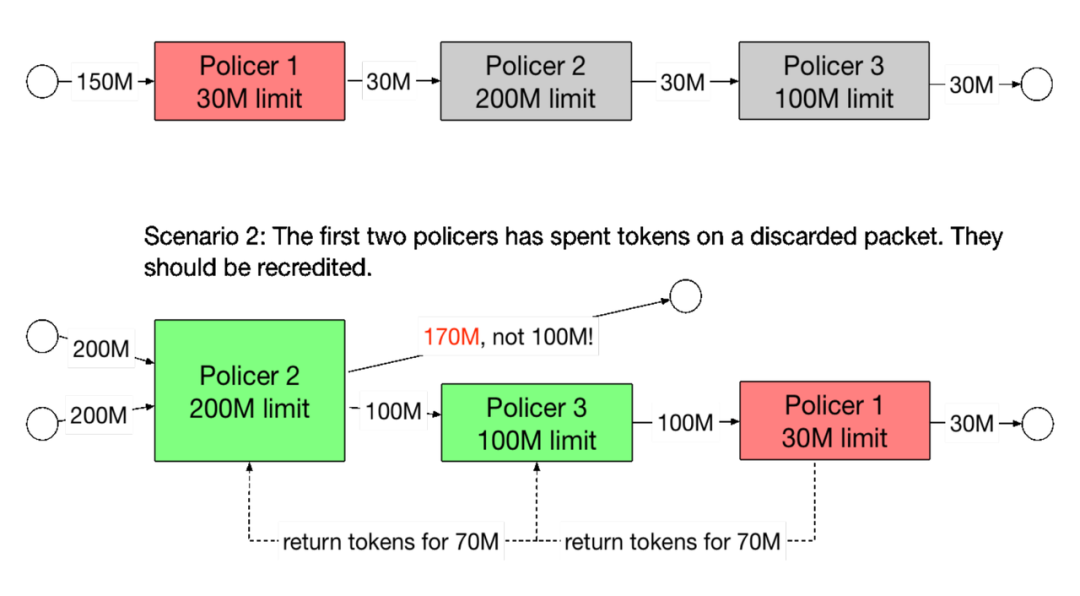 图2 限速器级联补偿
图2 限速器级联补偿
我们在实践中发现,多个限速器级联的时候,需要补偿令牌。比如对于限速器 A,这个包是放行,消耗了 A 的令牌。对于限速器 B,这个包是丢弃,因为 B 没令牌了。此时包被丢了。那么此时 A 的令牌就白白消耗了,即消耗了 token,然后包还是丢了。如果想达到一个准确的限速效果,限速器A的令牌应该被补偿。如图 2 所示那样。
级联补偿使得多个限速器互相耦合,在代码编写上也比较麻烦。我们在实际中发现,如果限速器 A 和限速器 B 的限速值接近,并且都有丢包,那么缺乏级联补偿会对精度有严重影响。但如果限速值差的很远,则对精度的影响没有那么大。
3. TCP对丢包敏感问题
令牌桶是没有缓存的,一旦速率超过限定值,则会出现丢包。而 TCP 协议则对丢包非常敏感,一旦出现丢包,TCP 的对速率的调整比较激进。令牌桶这一特性使得他在应用于 TCP 这种流量时,经常会导致限制 100Mbps,实际上最多只能跑到 80Mbps,因为不断的丢包导致 TCP 不断地降低发送窗口。
在 vSwitch 的使用时,BPS (Bits Per Second)限速对 TCP 的损耗尤其大,这是因为,一般虚拟网卡都开启了 TSO(TCP Segmentation Offload)优化,开启 TSO 情况下,主机向外发送的 TCP 包都很大,一个包有可能是 64K 字节,在这么大的情况下,随便丢若干个包,就对 TCP 的速率影响非常明显了。
第一次改进:端口借贷反压限速器
我们在实践中发现,级联补偿反馈问题虽然存在但不是非常突出,原因是一般级联的限速器的限速值差距很大,比如单网卡的速率和整机速率,一般差距较大,不容易出现精度问题。最严重的问题是 TCP 丢包敏感导致的限速带宽达不到,影响用户体验。由图3所示,随着 TCP RTT 的增加,实际可以达到的带宽会明显下降。
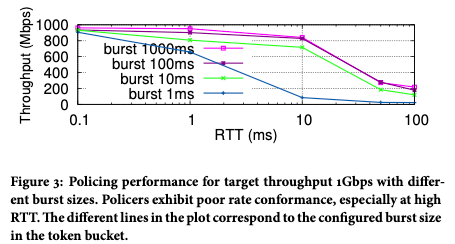
图3 流量通过1Gbps限速器之后,实际获得速率
反压(backpressure),就是针对 TCP 对丢包敏感这一问题进行的改进。我们在第一次设计的时候,其实针对的是一个特定的场景。既虚机的虚拟网卡进行限速。而且我们的限速器正好是每个网卡有一个特定的限速器。
每个虚拟网卡都有若干队列,vSwitch 会持续的轮询这些队列拿到数据包发出。这些队列本质上其实就是包的缓存区。反压,其实就是停止或者延缓对这些队列的轮询发包,让数据包在队列上堆积,而达到将压力反馈到 Guest Kernel 的目的,这样 Guest Kernel 的 TCP 栈就会感知到拥塞,调整发送的节奏。
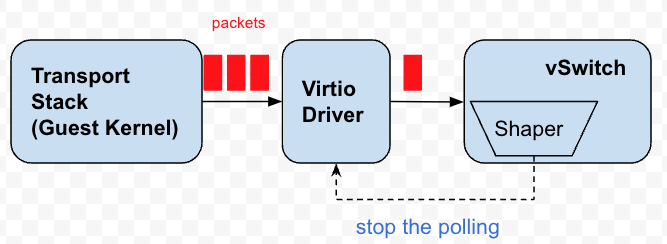
图4 反压限速器
当时我们设计反压限速器的时候,有一个限制影响了最后的实现:
虚机的虚拟网卡没有提供 Peek 功能,即 vSwitch 只是 Peek 数据包,而非真正将数据包从队列中拿出。这一个限制导致了我们利用了“借贷”的思想。既设置一个开始轮询的准许时间点,如果当前时间超过了准许时间点,那么将队列中的数据包一股脑全部发出,不考虑令牌是否足够,如果令牌足够则没有问题,但是当令牌不够了,那么就考虑向未来借贷一笔令牌,反向计算出一个未来的时间戳,那么在这个时间戳之前,vSwitch 停止轮询虚拟网卡。
借贷方法的提出,一开始只是为了性能考虑,避免好不容易将数据包从虚机队列拷贝出来,却发现令牌不够又只能丢弃。既然不想丢弃,索性就向未来借贷一笔令牌都发出去。
如今回过头来看这个设计,和 Peek 相比,其实有好有坏:
1)每次借贷的令牌量,不可控。这会导致公平性问题。大象流会不断的获取借贷资格,而小流则会趋向于饿死,在限速器竞争中,如果一方取得了优势,优势方容易持续获得优势。
2)简单的时间戳比较,开销比 peek 低。如果能够 peek 数据包,就不会有借贷的机制,也就没有停止轮询的可能,而是每次都会去虚拟队列里查看,反而开销有点大。
3)反过来,有 peek 功能的话,也可以先看看队列里积压的数据包,可以等待队列积累了一定量数据包之后,计算将下一次 Batch 个数据包发出的时间戳,在此之前都停止轮询。这对增加 batch 提升性能反而有好处。
反压限速器因为反压的是虚机的网卡队列,只能对虚机往外发数据包有限制,而无法限制虚机的收方向的流量。这是因为我们无法反压物理网卡的数据包,物理网卡的数据包可能发往不同的虚拟网卡,每个网卡的限速值是不一样的,我们无法计算出一个确切的时间点,在这个时间点之前可以不用轮询数据包。况且,物理网卡队列满了之后,只会丢包,而虚机网卡队列满了之后,可以反压 TCP 协议栈,两者效果是不一样的。
因此在入向流量的限制上,我们只是延续了准许时间戳的思想。如果当前时间超过准许时间,就放行所有数据包,如果没有,则丢弃所有数据包。
第二次改进:Carousel限速器
Carousel 限速器是 Google 在 SIGCOMM 17' 上的论文提出的一种限速器算法[2],实际上想法也很简单,即给每个数据包计算一个发出的时间戳,如果当前时间戳小于发出时间戳,则缓存在一个时间轮里,即不是丢包,而是将数据包延迟发送。
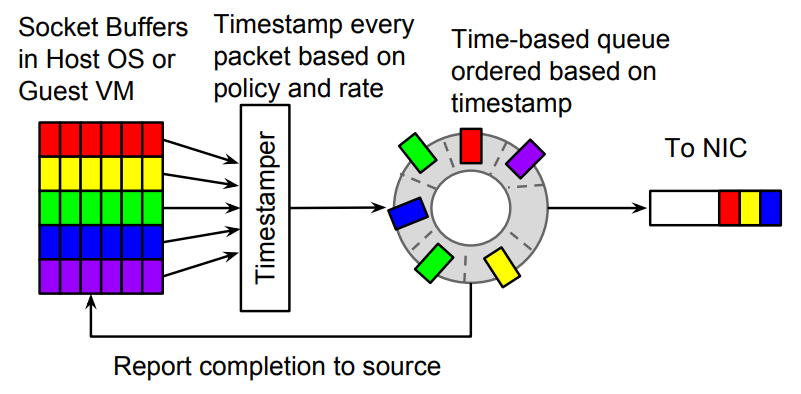
图5 Carousel限速器
我们基于这个算法基本原理,在 OVS-DPDK 实现了一个类似限速器,这中间有很多细节决定了算法的参数,比如一次轮询的时间粒度是 1us 还是 10us ?实际使用的限速器的速率区间在什么范围?是 300Kpps 还是 3Mpps?这些都直接决定了算法的参数设置,诸多细节就不展开说明了。
Carousel 最大的一个好处是引入了缓存。时间轮的本质就是一个缓存,这个对 TCP 流量有明显的好处,同时,时间轮也解决了虚机入向流量的无法反压的问题,使得所有的流量都能统一在一个时间轮下。第三个好处,可能有点意想不到,就是它一定程度的消除了级联补偿的必要性,因为数据包不在丢包,而是延迟发送。在没有丢包的情况下,不需要级联补偿。
下图是在限速 10Gbps 下,通过 iperf 工具,测试 100s 情况下,虚机出入向,在使用老的反压限速器和新的 Carousel 限速器的对比效果。
横轴是时间(s),竖轴是吞吐(Gbps),即每秒 iperf 报告出的当前的吞吐性能。可以看到入向流量增加了 500Mbps。更靠近 10Gbps。
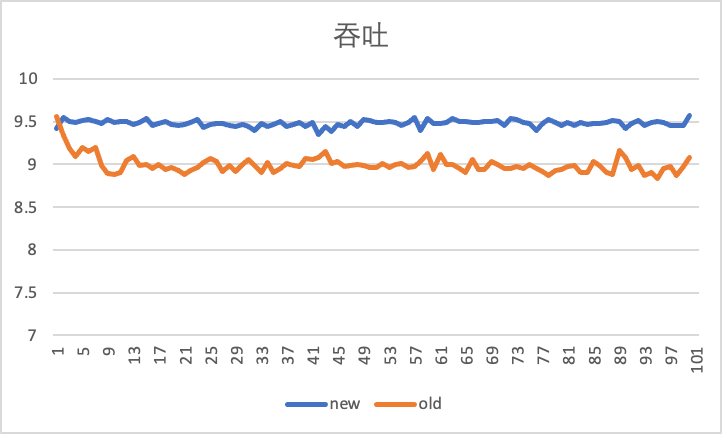
出向吞吐性能,可以看出 Carousel 限速器更加稳定: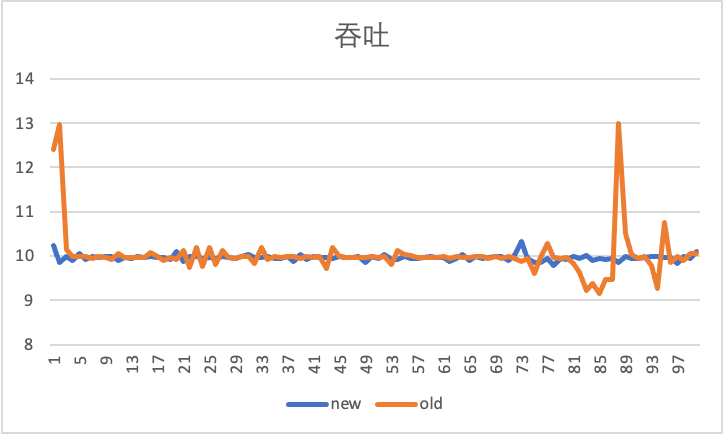
这些改进的源头,都来自于缓存对 TCP 流量的平滑作用。
未来的改进和小结
1. 进一步改进
基于借贷机制的反压限速,当限速值较大时,因借贷超发的数据包对整个限速抖动影响是有限的。比如限速 1G,在某个时刻超发几个包,对限速的抖动影响是比较小的。但是如果限速值很小,比如小到 5Mbps,那么超发几个数据包的影响就会比较大。此时,通过时间戳控制虚机端口的轮询,会带来 ON-OFF 效应,既在虚机看来,出向流量的路径上,好像有一个闸门,一会打开,一会关闭。
但这只是在虚机发送端视角看到的情况,接收端因为有时间轮的调节,速率会比较稳定。为在发送端带来比较稳定的体验,需要将反压的效果更加细化,既降低超发的几率。
此外,基于端口粒度的限速可以通过控制端口的轮询来实现,但是对于粒度小于端口的限速,则不好实现反压。为了实现更细粒度的反压,Google 在论文 PicNIC[3] 中,在Carousel 之上,利用 virtio 支持 OOO completion (乱序完成) 的特点,实现了更细粒度的反压,这些都为进一步优化限速器提供了思路。
2. 主动限速(基于ECN或者修改TCP window选项)
我们可以在 vSwitch 中对 TCP 的 Window 窗口进行跟踪修改,协商一个小窗口进行的方式,获得更平稳的 TCP 吞吐。同时ECN标记也可以在 vSwitch 中进行感知,通过直接或者间接的方式反馈到虚机内部,或者影响 vSwitch 的轮询频率。
3. 锁机制改进
以上所有的限速器改进均是针对网络方面,系统方面由于多核存在,而限速器的粒度经常跨越线程,如何设计一个无锁的限速器也是一个值得探索的方向。
4. 小结
从限速器的改进历史中可以看出,当前的算法已经越来越和实际场景相关。算法不再只是一个独立的组件,而越来越和实际的运行系统和产品特性紧密耦合。
审核编辑:刘清
-
PPS
+关注
关注
0文章
27浏览量
10612 -
RTT
+关注
关注
0文章
65浏览量
17243 -
虚拟机
+关注
关注
1文章
950浏览量
28521 -
TCP通信
+关注
关注
0文章
146浏览量
4303
原文标题:字节跳动在限速器优化上的实践探索
文章出处:【微信号:OSC开源社区,微信公众号:OSC开源社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论